imagen pytorch
2.1.0
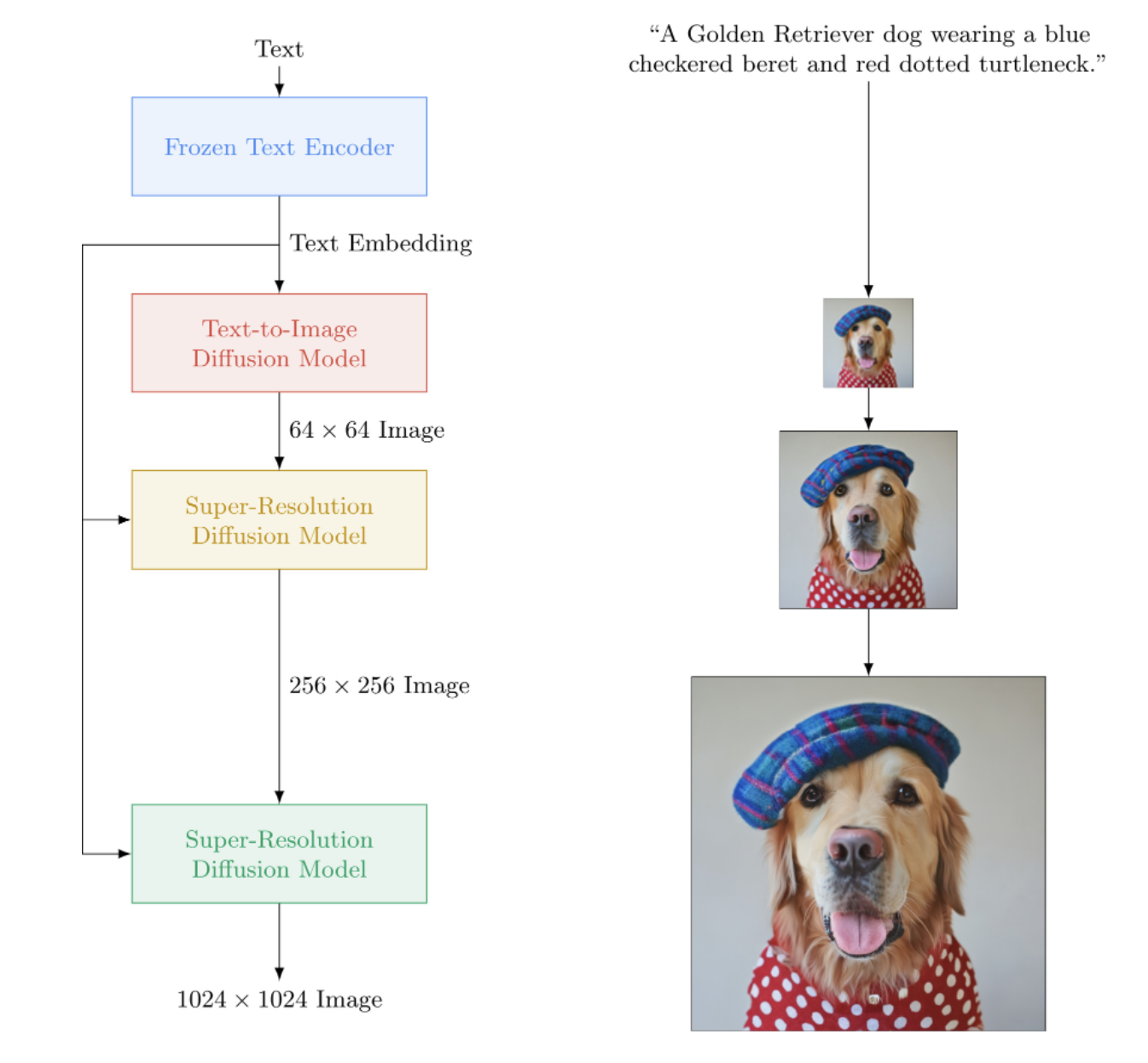
تنفيذ Imagen، الشبكة العصبية التي تعمل على تحويل النص إلى صورة من Google والتي تتفوق على DALL-E2، في Pytorch. إنه SOTA الجديد لتركيب النص إلى الصورة.
من الناحية المعمارية، فهو في الواقع أبسط بكثير من DALL-E2. وهو يتألف من DDPM متتالي مشروط بتضمين نص من نموذج T5 كبير تم تدريبه مسبقًا (شبكة الاهتمام). كما أنه يحتوي على قصاصة ديناميكية لتحسين التوجيه المجاني للمصنف، وتكييف مستوى الضوضاء، وتصميم وحدة فعالة للذاكرة.
يبدو أنه ليست هناك حاجة لـ CLIP أو الشبكة السابقة بعد كل شيء. وهكذا يستمر البحث.
استراحة القهوة بالذكاء الاصطناعي مع ليتيتيا | التجميع AI | يانيك كيلشر
يرجى الانضمام إذا كنت مهتمًا بالمساعدة في النسخ المتماثل مع مجتمع LAION
StabilityAI على الرعاية السخية، وكذلك الرعاة الآخرين هناك
؟ Huggingface لمكتبة المحولات المذهلة الخاصة بهم. يتم الاهتمام بجزء برنامج تشفير النص إلى حد كبير بسببها
جوناثان هو لإحداثه ثورة في الذكاء الاصطناعي التوليدي من خلال بحثه المبتكر
سيلفان وزاكاري لمكتبة Accelerate، التي يستخدمها هذا المستودع للتدريب الموزع
Alex for einops، أداة لا غنى عنها لمعالجة الموتر
خورخي جوميز للمساعدة في كود التحميل T5 ونصيحته بشأن إصدار T5 الصحيح
كاثرين كروسون، على كودها الجميل، الذي ساعدني على فهم النسخة الزمنية المستمرة للانتشار الغوسي
Marunine وNetruk44، لمراجعة التعليمات البرمجية ومشاركة النتائج التجريبية والمساعدة في تصحيح الأخطاء
Marunine لتوفير حل محتمل لمشكلة تغيير اللون في شبكات u ذات الكفاءة في الذاكرة. شكرًا لجاكوب على مشاركة المقارنات التجريبية بين الوحدات الأساسية والوحدات ذات الكفاءة في الذاكرة
Marunine لعثوره على العديد من الأخطاء، وحل مشكلة تتعلق بتغيير الحجم بشكل صحيح، ولمشاركته تكويناته ونتائجه التجريبية
MalumaDev لاقتراحه استخدام أداة خلط وحدات البكسل لإصلاح عيوب لوحة التحقق
فالنتين للإشارة إلى عدم كفاية اتصالات التخطي في الوحدة، بالإضافة إلى الطريقة المحددة لتكييف الانتباه في الوحدة الأساسية في الملحق
BIGJUN للقبض على حشرة كبيرة مع تكييف مستوى الضوضاء المنتشر الغاوسي في وقت الاستدلال
Bingbing لتحديد الخلل عن طريق أخذ العينات وترتيب التطبيع والضوضاء باستخدام صورة تكييف منخفضة الدقة
Kay لمساهمته في تدريب أمر سطر واحد لـ Imagen!
هادريان رينو لاختبار تحويل النص إلى فيديو على مجموعة بيانات طبية، ومشاركة نتائجه، وتحديد المشكلات!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)للحصول على تدريب أبسط، يمكنك توفير سلاسل نصية مباشرة بدلاً من الحوسبة المسبقة لترميزات النص. (على الرغم من أنه لأغراض القياس، ستحتاج بالتأكيد إلى حساب التضمينات النصية + القناع مسبقًا)
يجب أن يتطابق عدد التسميات التوضيحية النصية مع حجم مجموعة الصور إذا اتبعت هذا المسار.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () باستخدام فئة غلاف ImagenTrainer ، سيتم الاهتمام تلقائيًا بالمتوسطات المتحركة الأسية لجميع شبكات U في DDPM المتتالية عند استدعاء update
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)يمكنك أيضًا تدريب Imagen بدون نص (إنشاء صور غير مشروطة) على النحو التالي
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)أو قم بتدريب الوحدات فائقة الدقة فقط
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) يمكنك في أي وقت حفظ وتحميل المدرب وجميع الحالات المرتبطة به باستخدام طريقتي save load . يوصى باستخدام هذه الطرق بدلاً من الحفظ يدويًا باستخدام استدعاء state_dict ، نظرًا لوجود بعض إدارة ذاكرة الجهاز التي يتم إجراؤها أسفل الغطاء داخل المدرب.
السابق.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 يمكنك أيضًا الاعتماد على ImagenTrainer لتدريب مثيلات DataLoader تلقائيًا. ما عليك سوى إنشاء DataLoader الخاص بك لإرجاع images (للحالة غير المشروطة)، أو ('images', 'text_embeds') للإنشاء الموجه بالنص.
السابق. التدريب غير المشروط
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )شكرا ل؟ تسريع، يمكنك إجراء تدريب GPU متعدد بسهولة بخطوتين.
تحتاج أولاً إلى استدعاء accelerate config في نفس الدليل الذي يحتوي على البرنامج النصي للتدريب الخاص بك (على سبيل المثال، اسمه train.py )
$ accelerate config بعد ذلك، بدلاً من استدعاء python train.py كما تفعل مع وحدة معالجة الرسومات الفردية، يمكنك استخدام سطر الأوامر المتسارع هكذا
$ accelerate launch train.pyهذا كل شيء!
يمكن أيضًا استخدام Imagen عبر CLI مباشرةً.
السابق.
$ imagen configأو
$ imagen config --path ./configs/config.jsonفي التكوين، يمكنك تغيير إعدادات المدرب ومجموعة البيانات وتكوين الصورة.
يمكن العثور على معلمات تكوين Imagen هنا
يمكن العثور على معلمات تكوين Elucidated Imagen هنا
يمكن العثور على معلمات تكوين Imagen Trainer هنا
بالنسبة لمعلمات مجموعة البيانات، يمكن استخدام جميع معلمات أداة تحميل البيانات.
يتيح لك هذا الأمر تدريب نموذجك أو استئناف تدريبه
السابق.
$ imagen trainأو
$ imagen train --unet 2 --epoches 10يمكنك تمرير الوسائط التالية إلى أمر التدريب.
--config حدد ملف التكوين المطلوب استخدامه للتدريب [افتراضي: ./imagen_config.json]--unet فهرس الوحدة المراد تدريبها [الافتراضي: 1]--epoches كم عدد العصور التي يجب التدريب عليها [الافتراضي: 50]كن على دراية عند أخذ العينات، يجب أن تقوم نقطة التفتيش الخاصة بك بتدريب جميع الوحدات للحصول على نتيجة قابلة للاستخدام.
السابق.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngيمكنك تمرير الوسائط التالية إلى نموذج الأمر.
--model حدد ملف النموذج الذي سيتم استخدامه لأخذ العينات--cond_scale (إرشادات مجانية للمصنف) في وحدة فك التشفير--load_ema قم بتحميل إصدار EMA من الوحدات إذا كان متاحًا من أجل استخدام نقطة تفتيش محفوظة مع هذه الميزة، يجب عليك إما إنشاء مثيل Imagen الخاص بك باستخدام فئات التكوين، ImagenConfig و ElucidatedImagenConfig أو إنشاء نقطة تفتيش عبر واجهة سطر الأوامر مباشرة
للحصول على تدريب مناسب، من المحتمل أنك ستحتاج إلى إعداد تدريب قائم على التكوين على أي حال.
السابق.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalحقا ينبغي أن يكون بهذه البساطة
يمكنك أيضًا تمرير ملف نقطة التفتيش هذا، ويمكن لأي شخص متابعة ضبط بياناته الخاصة
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning يتبع Inpainting الصيغة التي وضعتها ورقة إعادة الطلاء الأخيرة. ما عليك سوى تمرير inpaint_images و inpaint_masks إلى sample الوظيفة في Imagen أو ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) بالنسبة للفيديو، قم بتمرير مقاطع الفيديو الخاصة بك بالمثل إلى الكلمة الرئيسية inpaint_videos على .sample . يمكن أن يكون قناع الطلاء الداخلي هو نفسه في جميع الإطارات (batch, height, width) أو مختلفًا (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) كتب Tero Karras من موقع StyleGAN الشهير بحثًا جديدًا بنتائج تم تأكيدها من قبل عدد من الباحثين المستقلين وكذلك على جهازي الخاص. لقد قررت إنشاء نسخة من Imagen ، ElucidatedImagen ، بحيث يمكن للمرء استخدام DDPM الجديد الموضح للتوليد المتتالي الموجه بالنص.
ما عليك سوى استيراد ElucidatedImagen ، ثم إنشاء مثيل للمثيل كما فعلت من قبل. تختلف المعلمات الفائقة عن المعلمات المعتادة للانتشار الغاوسي المنفصل والمستمر، ويمكن تخصيصها لكل وحدة في السلسلة.
السابق.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above سيبدأ هذا المستودع أيضًا في تجميع أبحاث جديدة حول تركيب الفيديو الموجه بالنص. بالنسبة للمبتدئين، سوف تتبنى بنية unet ثلاثية الأبعاد التي وصفها جوناثان هو في نماذج نشر الفيديو
التحديث: تم التحقق من العمل بواسطة هادريان رينو!
السابق.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) يمكنك أيضًا التدرب على أزواج الصور والنص أولاً. سيقوم Unet3D بتحويلها تلقائيًا إلى مقاطع فيديو ذات إطار واحد والتعلم بدون المكونات المؤقتة (من خلال الإعداد التلقائي ignore_time = True )، سواء كان ذلك عبارة عن تلافيفات أحادية البعد أو انتباه سببي عبر الزمن.
هذا هو النهج الحالي الذي تتبعه جميع مختبرات الذكاء الاصطناعي الكبرى (Brain، MetaAI، Bytedance)
يستخدم Imagen خوارزمية تسمى Classifier Free Guidance. عند أخذ العينات، يمكنك تطبيق مقياس على التكييف (النص في هذه الحالة) أكبر من 1.0 .
أفاد الباحث Netruk44 أن 5-10 هو المستوى الأمثل، ولكن يجب كسر أي شيء أكبر من 10 .
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averageليس في الوقت الحالي، ولكن من المحتمل أن يتم تدريب أحدهم وفتح المصدر خلال العام، إن لم يكن قبل ذلك. إذا كنت ترغب في المشاركة، يمكنك الانضمام إلى مجتمع مدربي الشبكات العصبية الاصطناعية في Laion (رابط Discord موجود في المستند التمهيدي أعلاه) وبدء التعاون.
المزيد من الأسباب التي تجعلك تبدأ في تدريب النموذج الخاص بك، بدءًا من اليوم! آخر شيء نحتاجه هو أن تكون هذه التكنولوجيا في أيدي نخبة قليلة. نأمل أن يقلل هذا المستودع من العمل إلى مجرد العثور على الحوسبة اللازمة، وتعزيزها بمجموعة البيانات الخاصة بك.
أي شئ! وهو مرخص من معهد ماساتشوستس للتكنولوجيا. بمعنى آخر، يمكنك النسخ/اللصق بحرية لأبحاثك الخاصة، وإعادة مزجها بأي طريقة تخطر على بالك. قم بتدريب نماذج مذهلة من أجل الربح أو العلم أو ببساطة لإشباع متعتك الشخصية في مشاهدة شيء إلهي ينكشف أمامك.
تركيب مخطط صدى القلب [الكود]
SOTA Hi-C توليف مصفوفة الاتصال [الكود]
توليد خطة الكلمة
شرائح التشريح المرضي عالية الدقة
الصور الاصطناعية بالمنظار
تصميم المواد الفوقية
نشر الصوت من فلافيو شنايدر
صورة مصغرة من Ryan O. | كتابة AssemblyAI
استخدم محولات المعانقة لتضمين النص الصغير T5
إضافة العتبة الديناميكية
أضف العتبة الديناميكية DALLE2 ومستودع نشر الفيديو أيضًا
اسمح لأحد بتعيين T5-large (وربما طريقة مصنع صغيرة لاستيعاب أي محول عناق)
أضف مستوى الضوضاء المنخفض مع الكود الكاذب في الملحق، واكتشف ما هو هذا المسح الذي يقومون به في وقت الاستدلال
المنفذ عبر بعض التعليمات البرمجية التدريبية من DALE2
يجب أن تكون قادرًا على استخدام جدول ضوضاء مختلف لكل وحدة (تم استخدام جيب التمام للقاعدة، ولكن خطي لـ SR)
ما عليك سوى إنشاء وحدة واحدة قابلة للتكوين بشكل رئيسي
كتلة ريسنيت كاملة (مستوحاة من Biggan؟ ولكن مع معيار المجموعة) - اهتمام كامل بالنفس
كتلة تضمين التكييف الكاملة (وجعلها قابلة للتكوين بالكامل، سواء كان ذلك اهتمامًا أو فيلمًا وما إلى ذلك)
فكر في استخدام أداة إعادة تشكيل أداة الإدراك من https://github.com/lucidrains/flamingo-pytorch بدلاً من تجميع الانتباه
إضافة خيار تجميع الانتباه، بالإضافة إلى تقاطع الانتباه والفيلم
أضف جدولًا اختياريًا لتحلل جيب التمام مع عملية الإحماء لكل وحدة للمدرب
قم بالتبديل إلى الخطوات الزمنية المستمرة بدلاً من المنفصلة، حيث يبدو أن هذا هو ما استخدموه في جميع المراحل - اكتشف أولاً حالة جدول الضوضاء الخطية من ورقة ddpm المتغيرة https://openreview.net/forum?id=2LdBqxc1Yv
اكتشف السجل (snr) لجدول ضوضاء ألفا جيب التمام.
قم بإلغاء تحذير المحولات لأنه يتم استخدام T5encoder فقط
السماح بالإعداد لاستخدام الانتباه الخطي على الطبقات التي لا يمكن فيها استخدام الاهتمام الكامل
إجبار الوحدات في حالة الوقت المستمر على استخدام شروط غير رباعية (فقط قم بتمرير السجل (snr) من خلال MLP مع معايير طبقات اختيارية)، لأن هذا هو ما أعمل عليه محليًا
إزالة التباين المستفادة
أضف ترجيح الخسارة P2 للوقت المستمر
تأكد من إمكانية تدريب ddpm المتتالي دون شرط نصي، وتأكد من أن النشر الغاوسي يعمل بشكل مستمر ومنفصل
استخدم التحويلات العميقة للكتاب التمهيدي على إسقاطات qkv في الاهتمام الخطي (أو استخدم تحويل الرمز المميز قبل الإسقاطات) - استخدم أيضًا التسرب الجديد الذي اقترحته bayesformer، حيث يبدو أنه يعمل بشكل جيد مع الاهتمام الخطي
استكشاف إثارة طبقة التخطي في وحدة فك ترميز UNET
تسريع التكامل
إنشاء أداة CLI وإنشاء صورة من سطر واحد
ضرب أي القضايا التي نشأت من تسريع
إضافة القدرة على الطلاء باستخدام أداة إعادة الرسم من ورق إعادة الطلاء https://arxiv.org/abs/2201.09865
بناء نظام بسيط لنقاط التفتيش، مدعومًا بمجلد
إضافة وصلة تخطي من مخرجات جميع الكتل النموذجية المستخدمة في ورق unet المربع وبعض أعمال unet السابقة
إضافة fsspec، الذي أوصى به Romain @rom1504، من أجل استمرار نقاط التفتيش في نظام الملفات السحابية/المحلية
اختبر الثبات في gcs باستخدام https://github.com/fsspec/gcsfs
تمتد إلى توليد الفيديو، وذلك باستخدام الاهتمام بالوقت المحوري كما هو الحال في ورقة الفيديو ddpm الخاصة بـ Ho
السماح للصورة الموضحة بالتعميم على أي شكل
السماح للصورة بالتعميم على أي شكل
أضف انحيازًا موضعيًا ديناميكيًا للحصول على أفضل نوع من استقراء الطول عبر وقت الفيديو
انقل إطارات الفيديو إلى وظيفة العينة، حيث سنحاول استقراء الوقت
يجب أن يكون انحياز الانتباه إلى المفتاح/القيم الفارغة بمثابة مقياس مكتسب لبعد الرأس
أضف التكييف الذاتي من ورق نشر البتات، المشفر بالفعل في ddpm-pytorch
إضافة معلمة v (https://arxiv.org/abs/2202.00512) من ورق فيديو imagen، الشيء الوحيد الجديد
دمج جميع الدروس المستفادة من إنشاء فيديو (https://makeavideo.studio/)
إنشاء أداة CLI للتدريب واستئناف التدريب من ملف التكوين
السماح للاستيفاء الزمني في مراحل محددة
تأكد من أن الاستيفاء الزمني يعمل مع inpainting
تأكد من إمكانية تخصيص جميع أوضاع الاستيفاء (يجد بعض الباحثين نتائج أفضل مع الخطوط الثلاثية)
imagen-video : السماح بالتكييف على إطارات مقاطع الفيديو السابقة (وربما المستقبلية). لا ينبغي السماح بتجاهل الوقت في هذا السيناريو
تأكد من الاهتمام تلقائيًا بالتخفيض/التكبير المؤقت لإطارات الفيديو التكييفية، ولكن اسمح بخيار إيقاف تشغيله
تأكد من أن الرسم يعمل مع الفيديو
تأكد من إمكانية قبول قناع الرسم للفيديو لكل إطار
إضافة انتباه فلاش
أعد قراءة cogvideo واكتشف كيف يمكن استخدام تكييف معدل الإطارات
جلب خبرة الانتباه لطبقات الاهتمام الذاتي في unet3d
فكر في جذب الاهتمام التلافيفي ثلاثي الأبعاد لـ NUWA
ضع في اعتبارك ذكريات Transformer-XL في كتل الانتباه الزمنية
النظر في نهج المدرك لحضور الوقت الماضي
يتسرب الإطار أثناء الانتباه لتحقيق تأثير التنظيم بالإضافة إلى تقصير وقت التدريب
التحقيق في ادعاءات فرانك وود https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch وإما إضافة تقنية أخذ العينات الهرمية، أو السماح للناس بمعرفة أوجه القصور فيها
تقديم mnist متحرك صعب (مع كائنات مشتتة للانتباه) كخط أساس قابل للتدريب من سطر واحد للباحثين للتفرع من النص إلى الفيديو
الترميز المسبق للنص إلى التضمينات المضمنة
تكون قادرًا على إنشاء تكرارات أداة تحميل البيانات استنادًا إلى نمط العصر القديم، وكذلك تكوين الخلط وما إلى ذلك
تكون قادرًا أيضًا على تمرير الوسائط (بدلاً من المطالبة بإعادة التوجيه لتكون جميع وسائط الكلمات الرئيسية في النموذج)
قم بإحضار كتل قابلة للعكس من revnets لـ 3d unet لتقليل عبء الذاكرة
إضافة القدرة على تدريب الشبكة فائقة الدقة فقط
اقرأ dpm-solver لمعرفة ما إذا كان قابلاً للتطبيق على الانتشار الغوسي المستمر
السماح بتكييف إطارات الفيديو بأوقات مطلقة عشوائية (احسب RPE أثناء الاهتمام الزمني)
استيعاب كشك الأحلام الضبط الدقيق
إضافة انعكاس النص
تنظيف التكييف الذاتي ليتم استخراجه عند إنشاء مثيل للصورة
تأكد من أن Dreambooth النهائي يعمل مع imagen-video
إضافة تكييف معدل الإطارات لنشر الفيديو
تأكد من إمكانية تكييف إطارات الفيديو بشكل متزامن كمطالبة، بالإضافة إلى بعض صور التكييف عبر جميع الإطارات
اختبار وإضافة تقنية التقطير من نماذج الاتساق
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

