eye in the sky
1.0.0
تصنيف صور الأقمار الصناعية، InterIIT Techmeet 2018، IIT Bombay.
الفريق: مانديب كولا، أنيكيت ماندل، أبورفا كومار
يحتوي هذا المستودع على تنفيذ خوارزميتين هما U-Net: الشبكات التلافيفية لتجزئة الصور الطبية الحيوية وشبكة تحليل مشهد الهرم المعدلة لمشكلة تصنيف صور الأقمار الصناعية.
main_unet.py : كود بايثون لتدريب الخوارزمية باستخدام بنية U-Net بما في ذلك تشفير الحقائق الأرضية.unet.py : يحتوي على تطبيقنا لطبقات U-Net.test_unet.py : كود الاختبار وحساب الدقة وحساب مصفوفات الارتباك للتدريب والتحقق وحفظ التنبؤات بواسطة نموذج U-Net على صور التدريب والتحقق والاختبار.Inter-IIT-CSRE : يحتوي على جميع بيانات التدريب واختبار صحة الإعلانات.Comparison_Test.pdf : مقارنة بيانات الاختبار جنبًا إلى جنب مع توقعات نموذج U-Net على البيانات.train_predictions : تنبؤات نموذج U-Net بشأن صور التدريب والتحقق من الصحة.plots : مؤامرات الدقة والخسارة للتدريب والتحقق من صحة بنية U-Net.Test_images , Test_outputs : يحتوي على صور الاختبار وتوقعاتها بنموذج U-Net.class_masks و compare_pred_to_gt و images_for_doc : تحتوي على عدة صور للتوثيق.PSPNet : يحتوي على ملفات تدريبية لتطبيق خوارزمية PSPNet لتصنيف صور الأقمار الصناعية. قم باستنساخ المستودع، وقم بتغيير دليل العمل الحالي الخاص بك إلى الدليل المستنسخ. قم بإنشاء مجلدات بأسماء train_predictions و test_outputs لحفظ مخرجات النموذج المتوقعة في صور التدريب والاختبار (غير مطلوب الآن لأن الريبو يحتوي بالفعل على هذه المجلدات)
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
لتدريب نموذج U-Net وحفظ الأوزان، قم بتشغيل الأمر أدناه
$ python3 main_unet.py
لاختبار نموذج يو نت وحساب الدقة وحساب مصفوفات الارتباك للتدريب والتحقق وحفظ التنبؤات بواسطة النموذج على صور التدريب والتحقق والاختبار.
$ python3 test_unet.py
قد تحصل على خطأ xrange is not defined أثناء تشغيل التعليمات البرمجية الخاصة بنا. لا يرجع هذا الخطأ إلى أخطاء في الكود الخاص بنا ولكن بسبب عدم تحديث حزمة python المسماة libtiff (بعض أجزاء الكود المصدري للحزمة موجودة في python2 وبعضها موجود في python3) والتي استخدمناها لقراءة مجموعة البيانات التي الصور بتنسيق .tif. لم نتمكن من استخدام مكتبات أخرى مثل openCV أو PIL لقراءة الصور لأنها لا تدعم بشكل صحيح قراءة صور .tif ذات القنوات الأربع.
يمكن حل هذا الخطأ عن طريق تحرير الكود المصدري لمكتبة libtiff .
انتقل إلى الملف الموجود في الكود المصدري للمكتبة حيث ينشأ الخطأ (سيتم عرض اسم الملف في الجهاز عندما يظهر الخطأ) واستبدل جميع وظائف xrange() (python2) في الملف إلى range() (بيثون3).
نحن نقدم بعض الأوزان المدربة جيدًا بشكل معقول هنا حتى لا يحتاج المستخدمون إلى التدريب من الصفر.
| وصف | مهمة | مجموعة البيانات | نموذج |
|---|---|---|---|
| هندسة يونيت | تصنيف صور الأقمار الصناعية | مجموعة بيانات IITB (راجع مجلد Inter-IIT-CSRE ) | تنزيل (.h5) |
لاستخدام الأوزان المدربة مسبقًا، قم بتغيير اسم ملف .h5 (ملف الأوزان) المذكور في test_unet.py ليطابق اسم ملف الأوزان الذي قمت بتنزيله حيثما كان ذلك مطلوبًا.
دعونا نناقش الآن
1. ما يدور حوله هذا المشروع،
2. البنى المعمارية التي استخدمناها وجربناها و
3. بعض استراتيجيات التدريب الجديدة التي استخدمناها في المشروع
الاستشعار عن بعد هو علم الحصول على معلومات حول الأشياء أو المناطق من مسافة بعيدة، عادة من الطائرات أو الأقمار الصناعية.
لقد أدركنا مشكلة تصنيف صور القمر الصناعي باعتبارها مشكلة تجزئة دلالية وقمنا ببناء خوارزميات تجزئة دلالية في التعلم العميق لمعالجة هذه المشكلة.
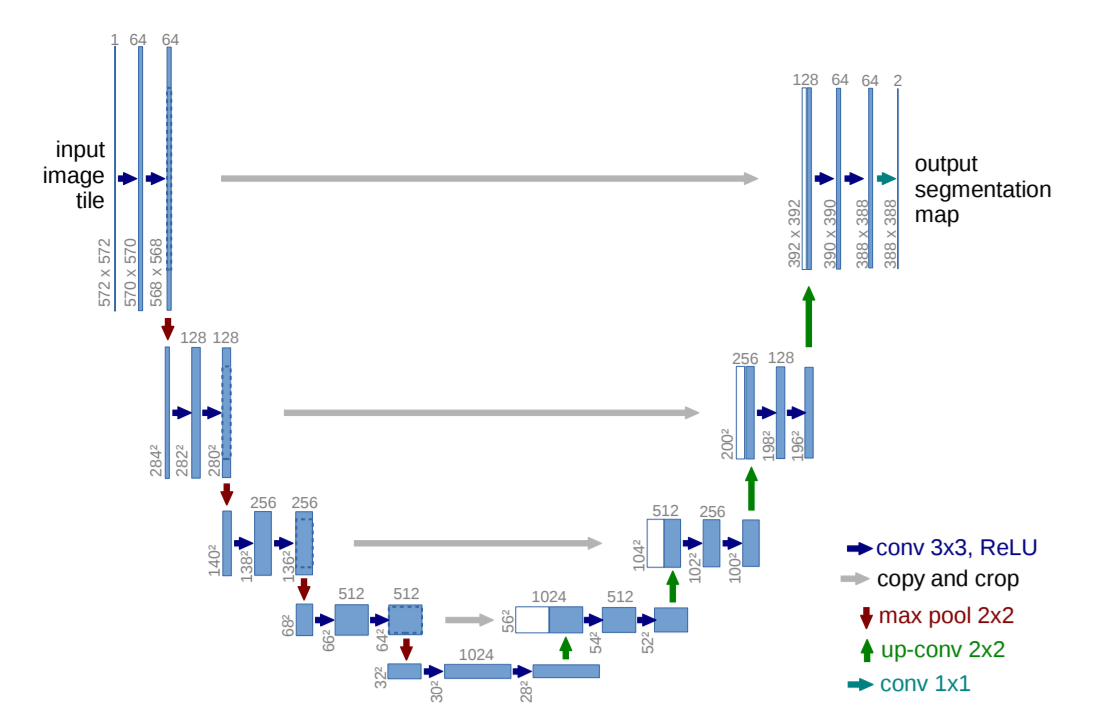
U-Net: الشبكات التلافيفية لتجزئة الصور الطبية الحيوية
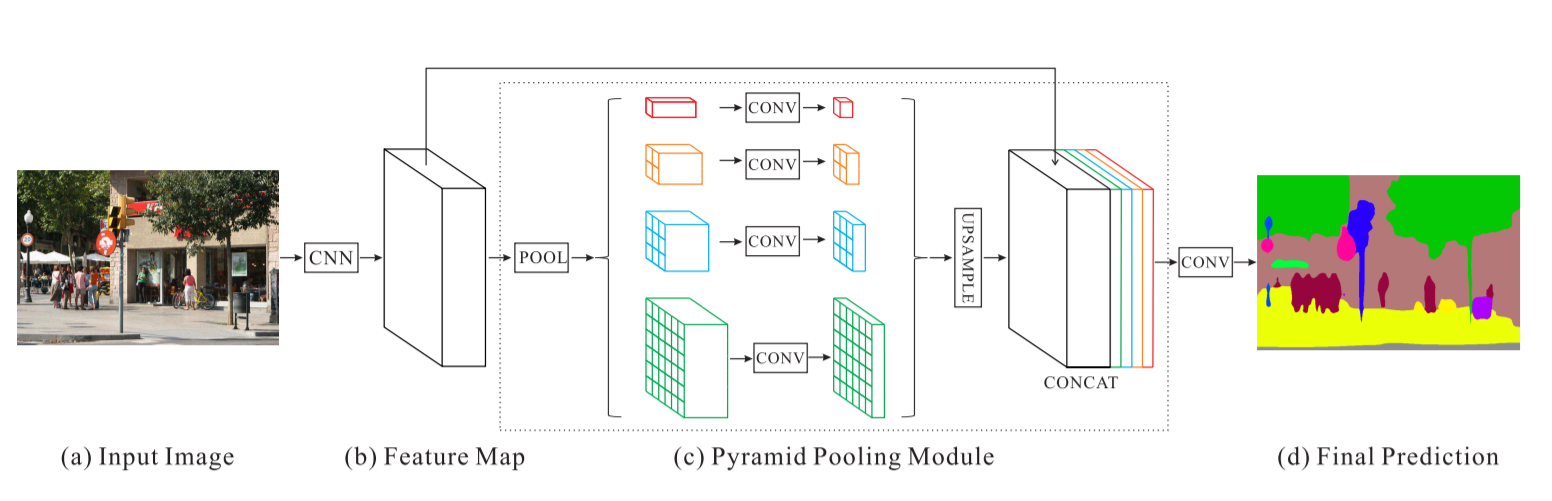
شبكة تحليل مشهد الهرم - شبكة PSPNet
الحقائق الأساسية المقدمة هي 3 صور RGB للقناة. في مجموعة البيانات الحالية، لا يوجد سوى 9 قيم RGB فريدة في الحقائق الأساسية حيث توجد 9 فئات سيتم تصنيفها. يتم تشفير قيم RGB التسعة المختلفة هذه بشكل ساخن واحد لإنشاء حقيقة أساسية مشفرة بـ 9 قنوات حيث تمثل كل قناة فئة معينة.
أدناه هو نظام الترميز
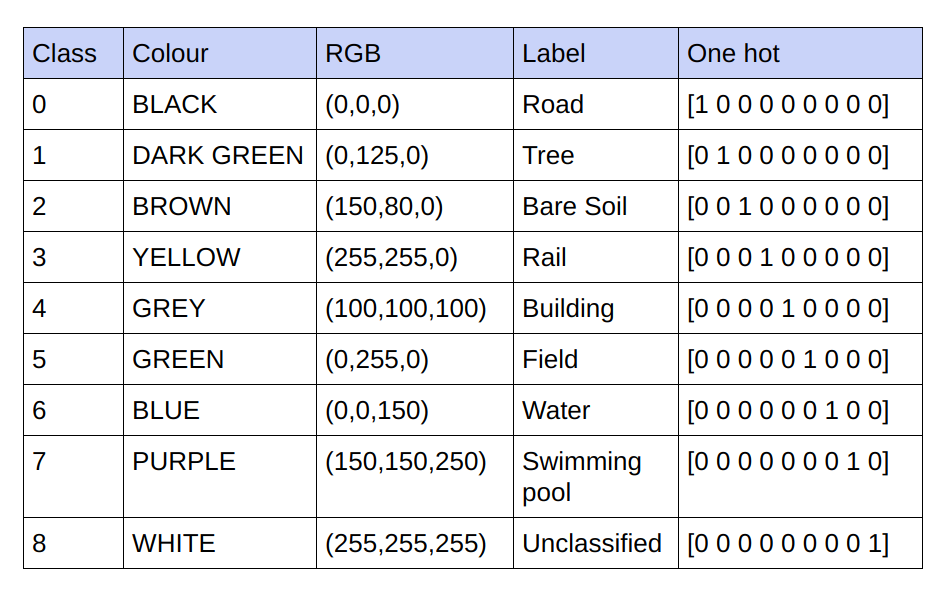
تحقيق كل قناة في الحقيقة الأرضية المشفرة كفئة

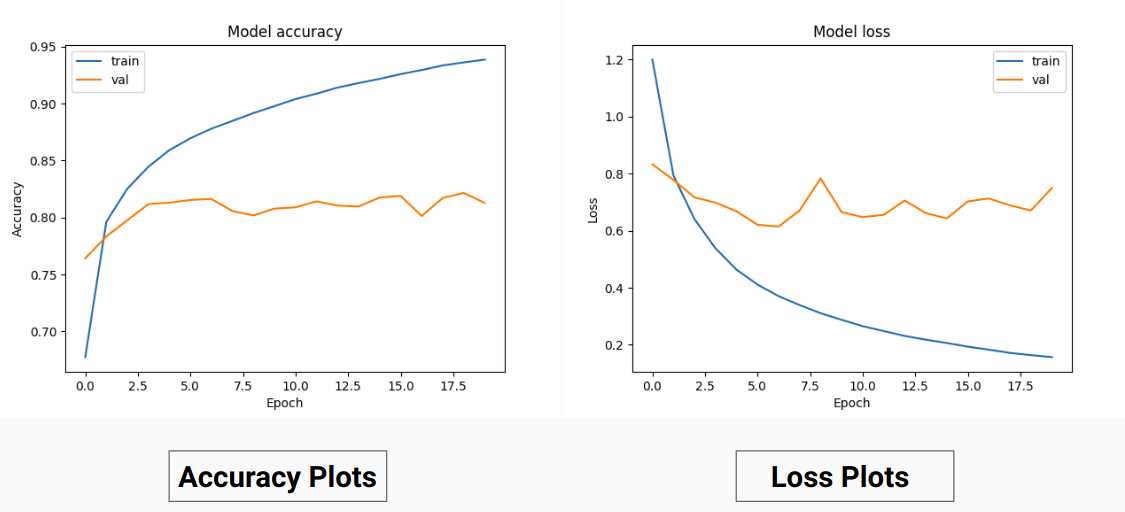
لذلك بدلاً من التدريب على قيم RGB للحقيقة الأرضية قمنا بتحويلها إلى قيم واحدة ساخنة لفئات مختلفة. لقد أتاح لنا هذا النهج دقة تحقق بنسبة 85% ودقة تدريب بنسبة 92% مقارنة بدقة التحقق البالغة 71% ودقة التدريب بنسبة 65% عندما كنا نستخدم قيم الحقيقة الأرضية RGB للتدريب.
قد يكون هذا بسبب انخفاض التباين ومتوسط الحقيقة الأساسية لبيانات التدريب لأنها تعمل كتقنية تطبيع فعالة. الأداء الأفضل لتقنية التدريب هذه يرجع أيضًا إلى أن النموذج يعطي مخرجات بـ 9 خرائط ميزات تشير كل خريطة إلى فئة ما، أي أن تقنية التدريب هذه تعمل كما لو أن النموذج قد تم تدريبه على كل فئة من الفئات الـ 9 بشكل منفصل إلى حد ما ( ولكن هنا بالتأكيد التنبؤ على قناة واحدة والتي تقابل فئة معينة يعتمد على القنوات الأخرى) .
نتائجنا على PSPNet لتصنيف صور الأقمار الصناعية:
دقة التدريب - 49% دقة التحقق - 60%
الأسباب:
يو نت:
تعديل يو نت:
للتدريب والتحقق من الصحة، استخدمنا 14 صورة '.tif' في المجلد Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset .
للتدريب استخدمنا أول 13 صورة في مجموعة البيانات وللتحقق من الصحة، تم استخدام الصورة الرابعة عشرة .
تحتوي كل صور الأقمار الصناعية الموجودة في sat على 4 قنوات وهي R (النطاق 1)، وG (النطاق 2)، وB (النطاق 3)، وNIR (النطاق 4).
صور الحقيقة الأرضية في دليل gt هي صور RGB وتصور 8 فئات - الطرق والمباني والأشجار والعشب والتربة العارية والمياه والسكك الحديدية وحمامات السباحة
السبب وراء اعتبارنا صورة واحدة فقط (الصورة الرابعة عشرة) كمجموعة تحقق هو أنها واحدة من أصغر الصور في مجموعة البيانات ولا نريد ترك بيانات أقل للتدريب لأن مجموعة البيانات صغيرة جدًا. مجموعة التحقق (الصورة الرابعة عشرة) التي درسناها لا تحتوي على 3 فئات (التربة العارية، والسكك الحديدية، واستطلاع Swimmimg) والتي تتمتع بدقة تدريب عالية جدًا. كانت دقة التحقق من الصحة أفضل لو أخذنا في الاعتبار صورة تحتوي على جميع الفئات (لا توجد صورة في مجموعة البيانات تحتوي على جميع الفئات، هناك فئة واحدة على الأقل مفقودة في جميع الصور).
الاقتصاص المتعرج:
للحصول على بيانات تدريب كافية من الصور عالية الوضوح المحددة، يلزم اقتصاصها لتدريب المصنف الذي يحتوي على حوالي 31 مليون معلمة لتطبيق U-Net الخاص بنا. حجم الاقتصاص 64x64 نجد تمثيلًا ناقصًا للفئات الفردية ويتم فقدان هندسة واستمرارية الكائنات، مما يقلل من مجال رؤية التلافيف.
استخدام نافذة اقتصاص بحجم 128 × 128 بكسل مع خطوة 32 ناتجة عن 15887 تدريبًا و414 صورة للتحقق.
أبعاد الصورة:
قبل الاقتصاص، يتم تحويل أبعاد صور التدريب إلى مضاعفات الخطوات لتوفير الراحة أثناء الاقتصاص الممتد.
بالنسبة للحالات التي لا. المحاصيل ليست مضاعف أبعاد الصورة التي جربناها في البداية بدون حشوة، أدركنا أن إضافة الحشوة ستضيف عناصر غير مرغوب فيها على شكل بكسلات سوداء في تدريب واختبار الصور مما يؤدي إلى التدريب على البيانات الخاطئة وحدود الصورة.
وبدلاً من ذلك، قمنا بتغيير أبعاد الصورة بشكل صحيح عن طريق إضافة وحدات بكسل إضافية في الجانب الأيمن من الصورة وأسفلها. لذلك قمنا بتغطية الفرق من الجزء الأيسر من الصورة إلى نهاية العجز الأيمن، وبالمثل بالنسبة لأعلى وأسفل الصورة.
مثال التدريب 1: الصورة "2.tif" من بيانات التدريب
مثال التدريب 2: الصورة "4.tif" من بيانات التدريب
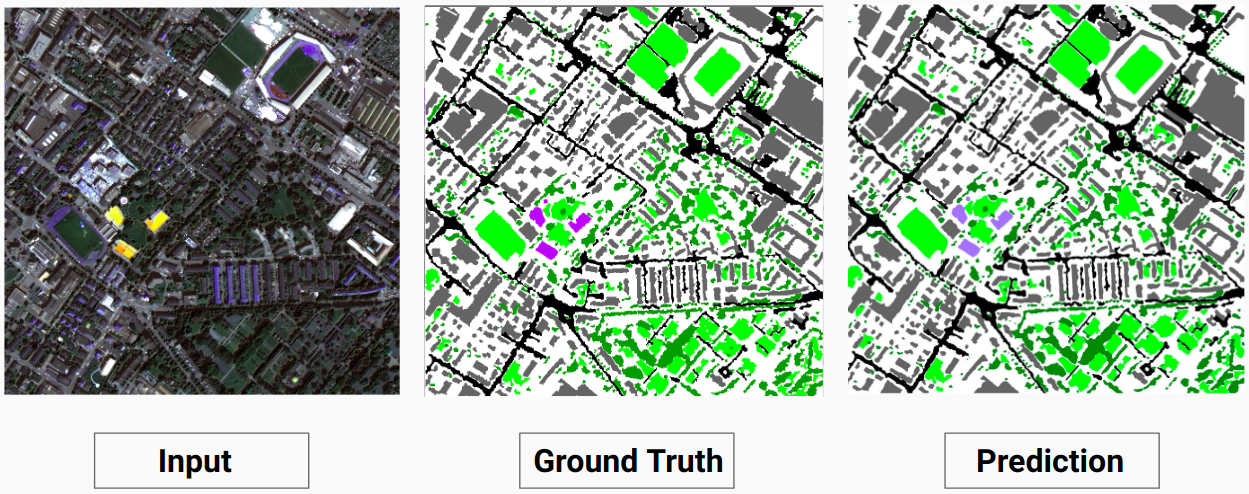
مثال للتحقق من الصحة: الصورة "14.tif" من مجموعة البيانات

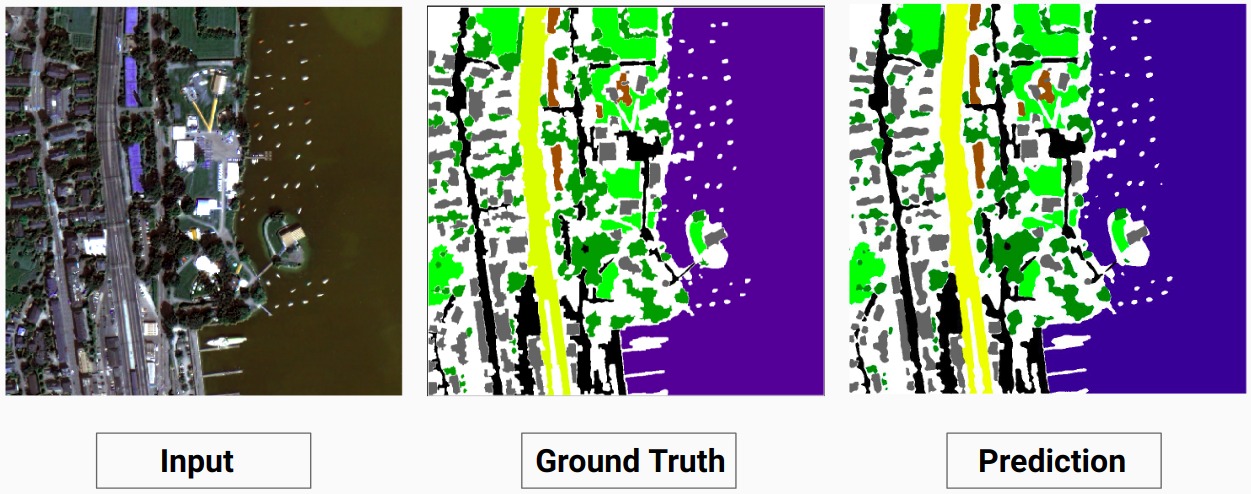
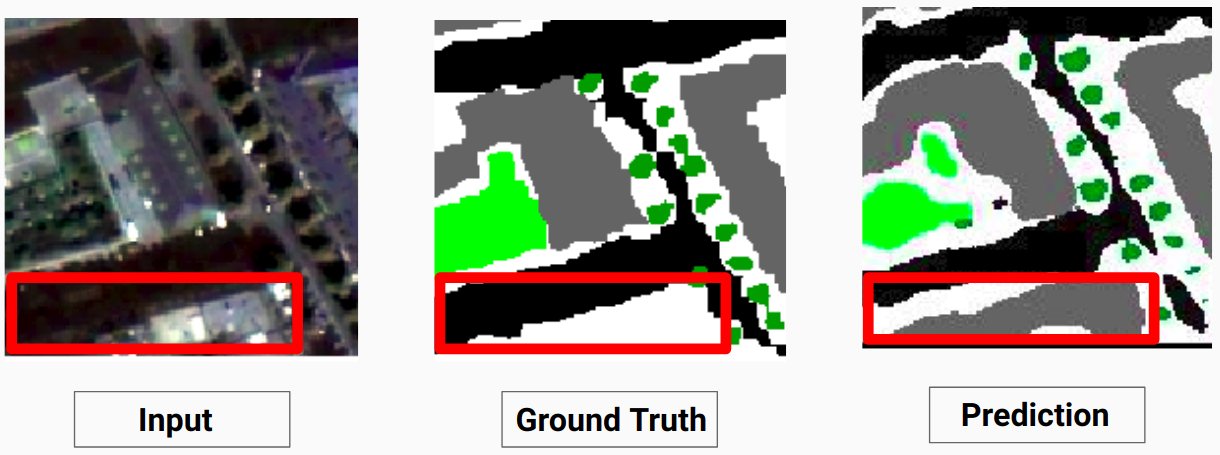
نموذجنا قادر على التنبؤ ببعض الفئات التي لم يتمكن المفسر البشري من التنبؤ بها. يتم تصنيف الفئات غير القابلة للتعريف في الصور على أنها وحدات بكسل بيضاء بواسطة المعلق البشري. نموذجنا قادر على التنبؤ ببعض هذه البكسلات البيضاء بشكل صحيح مثل بعض الفئات، ولكن هذا تسبب في انخفاض في الدقة الإجمالية حيث تعتبر البيكسلات البيضاء فئة منفصلة حسب النموذج.
هنا يكون النموذج قادرًا على التنبؤ بالبكسلات البيضاء كمبنى صحيح ويمكن رؤيته بوضوح في الصورة المدخلة
قم بمراجعة Comparison_Test.pdf للمقارنة بين صور الاختبار ومخرجاتها المتوقعة بواسطة النموذج
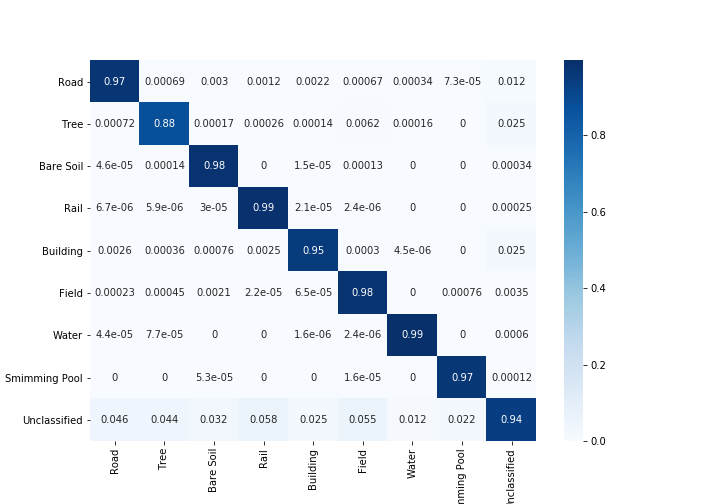
معاملات كابا مع وبدون النظر إلى وحدات البكسل غير المصنفة
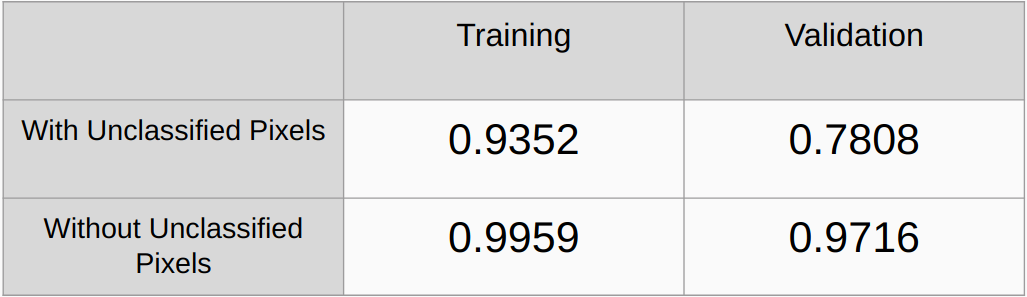
الدقة الشاملة مع وبدون النظر إلى وحدات البكسل غير المصنفة
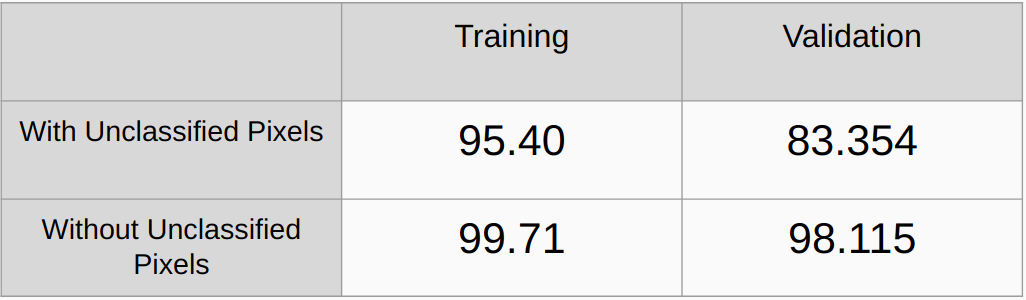
تحتاج إلى إضافة أساليب التنظيم مثل تسوية L2 والتسرب والتحقق من الأداء
قم بتنفيذ خوارزمية للكشف تلقائيًا عن جميع قيم RGB الفريدة في الحقائق الأساسية وترميزها بواسطة Onehot بدلاً من العثور على قيم RGB يدويًا.
[1] يو نت: الشبكات التلافيفية لتجزئة الصور الطبية الحيوية، أولاف رونبيرجر، فيليب فيشر، وتوماس بروكس
[2] شبكة تحليل المشهد الهرمي، هنغشوانغ تشاو، جيان بينغ شي، شياوجوان تشي، شياو قانغ وانغ، جيايا جيا
[3] دليل 2017 للتجزئة الدلالية باستخدام التعلم العميق، ساسانك تشيلامكورثي


