PaLM rlhf pytorch
0.3.9
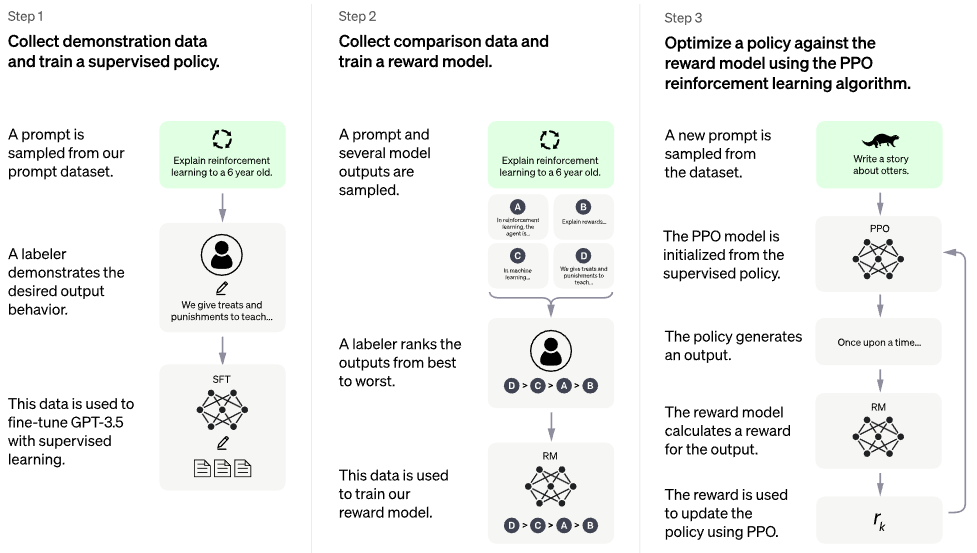
مدونة chatgpt الرسمية
تنفيذ RLHF (التعلم المعزز بالملاحظات البشرية) أعلى بنية PaLM. ربما سأضيف وظيفة الاسترجاع أيضًا، على غرار RETRO
إذا كنت مهتمًا بتكرار شيء مثل ChatGPT بشكل علني، فيرجى التفكير في الانضمام إلى Laion
الخلف المحتمل: تحسين التفضيل المباشر - تصبح جميع التعليمات البرمجية الموجودة في هذا الريبو ~ خسارة إنتروبيا ثنائية متقاطعة، <5 loc. الكثير بالنسبة لنماذج المكافآت وPPO
لا يوجد نموذج مدرب. هذه مجرد السفينة والخريطة الشاملة. ما زلنا بحاجة إلى ملايين الدولارات من البيانات الحسابية للإبحار إلى النقطة الصحيحة في مساحة المعلمات عالية الأبعاد. وحتى في هذه الحالة، تحتاج إلى بحارة محترفين (مثل Robin Rombach من شركة Stable Diffusion الشهيرة) لتوجيه السفينة فعليًا خلال الأوقات المضطربة إلى تلك النقطة.
كان CarperAI يعمل على إطار عمل RLHF لنماذج اللغات الكبيرة لعدة أشهر قبل إصدار ChatGPT.
يعمل يانيك كيلشر أيضًا على تطبيق مفتوح المصدر
استراحة القهوة بالذكاء الاصطناعي مع ليتيتيا | كود امبوريوم | رمز المتجر الجزء 2
Stability.ai على الرعاية السخية للعمل على أحدث أبحاث الذكاء الاصطناعي
؟ Hugging Face وCarperAI لكتابة منشور المدونة توضيح التعلم المعزز من ردود الفعل البشرية (RLHF)، والأول أيضًا لمكتبتهم السريعة
@kissetternity و@taynoel84 لمراجعة الكود والعثور على الأخطاء
إنريكو لدمج Flash Attention من Pytorch 2.0
$ pip install palm-rlhf-pytorch قم أولاً بتدريب PaLM ، مثل أي محول انحدار ذاتي آخر
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) ثم قم بتدريب نموذج المكافأة الخاص بك، باستخدام التعليقات البشرية المنسقة. في الورقة الأصلية، لم يتمكنوا من الحصول على نموذج المكافأة ليتم ضبطه من محول تم تدريبه مسبقًا دون التجهيز الزائد، لكنني أعطيت خيار الضبط مع LoRA على أي حال، لأنه لا يزال بحثًا مفتوحًا.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) ثم ستقوم بتمرير المحول الخاص بك ونموذج المكافآت إلى RLHFTrainer
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) محول قاعدة استنساخ مع لورا منفصلة للناقد
السماح أيضًا بالضبط الدقيق غير المعتمد على LoRA
قم بإعادة التطبيع لتتمكن من الحصول على نسخة مقنعة، ولست متأكدًا مما إذا كان أي شخص سيستخدم المكافآت/القيم لكل رمز مميز، ولكن يجب تنفيذ الممارسة الجيدة
تجهيز مع أفضل الاهتمام
قم بإضافة Hugging Face لتسريع واختبار أجهزة Wandb
ابحث في الأدبيات لمعرفة ما هو أحدث SOTA لـ PPO، على افتراض أن مجال RL لا يزال يحرز تقدمًا.
اختبر النظام باستخدام شبكة المشاعر المدربة مسبقًا كنموذج للمكافأة
اكتب الذاكرة في PPO إلى ملف numpy memmapped
الحصول على عينات باستخدام المطالبات ذات المدة المتغيرة، حتى لو لم تكن هناك حاجة إليها نظرًا لأن عنق الزجاجة هو ردود الفعل البشرية
السماح بضبط طبقات N قبل الأخيرة فقط في الممثل أو الناقد، على افتراض أنه تم تدريبه مسبقًا
دمج بعض نقاط التعلم من Sparrow، في ضوء فيديو Letitia
واجهة ويب بسيطة مع Django + htmx لجمع التعليقات البشرية
النظر في RLAIF
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

