linformer pytorch
version
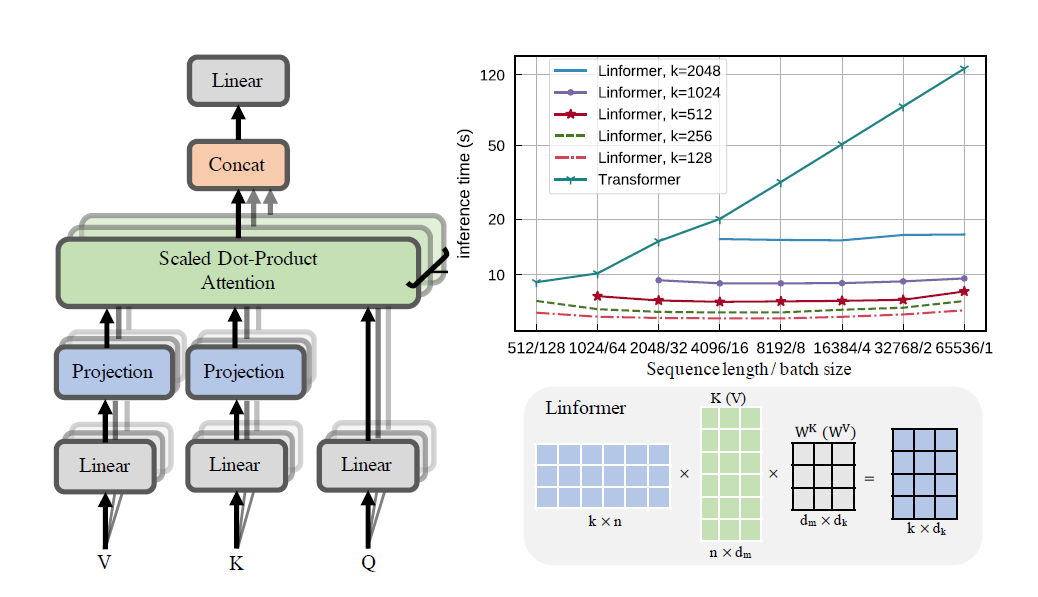
التطبيق العملي لورقة Linformer. هذا هو الاهتمام بالتعقيد الخطي فقط في n، مما يسمح بالاهتمام بأطوال تسلسلية طويلة جدًا (1mil+) على الأجهزة الحديثة.
هذا الريبو عبارة عن محول نمط "الانتباه هو كل ما تحتاجه"، مكتمل بوحدة التشفير ووحدة فك التشفير. الجديد هنا هو أنه الآن، يمكن للمرء أن يجعل رؤوس الانتباه خطية. تحقق من كيفية استخدامه أدناه.
هذا قيد التحقق من صحته على wikitext-2. حاليًا، يعمل بنفس مستوى آليات الانتباه المتناثر الأخرى، مثل محول Sinkhorn، ولكن لا يزال يتعين العثور على أفضل المعلمات الفائقة.
من الممكن أيضًا تصور الرؤوس. لرؤية المزيد من المعلومات، راجع قسم التصور أدناه.
أنا لست مؤلف هذه الورقة.
1.23 مليون رمز
pip install linformer-pytorch
بدلاً عن ذلك،
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
نموذج لغة لينفورمر
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer الاهتمام الذاتي، وأكوام من MHAttention و FeedForward s
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)اهتمام Linformer متعدد الرؤوس
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)رأس الاهتمام الخطي، حداثة الورقة
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)وحدة التشفير/فك التشفير.
ملاحظة: بالنسبة للتسلسلات السببية، يمكن للمرء تعيين العلامة causal=True في LinformerLM لإخفاء الجزء العلوي الأيمن من مصفوفة الانتباه (n,k) .
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) يمكن إجراء طريقة سهلة للحصول على المصفوفات E و F عن طريق استدعاء الدالة get_EF . على سبيل المثال، بالنسبة لـ n الذي يساوي 1000 و k الذي يساوي 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) باستخدام علامة method ، يمكن للمرء ضبط الطريقة التي يقوم بها جهاز linformer للاختزال. حاليًا، يتم دعم ثلاث طرق:
learnable : تنشئ طريقة الاختزال هذه وحدة نمطية n,k nn.Linear قابلة للتعلم.convolution : تنشئ طريقة الاختزال هذه التفافًا أحادي الأبعاد بطول الخطوة وحجم النواة n/k .no_params : يؤدي هذا إلى إنشاء مصفوفة n,k ثابتة ذات قيم fron N(0,1/k)في المستقبل، قد أقوم بتضمين التجميع أو أي شيء آخر. لكن في الوقت الحالي، هذه هي الخيارات الموجودة.
كمحاولة لتقديم المزيد من توفير الذاكرة، تم تقديم مفهوم مستويات نقاط التفتيش. مستويات نقاط التفتيش الثلاثة الحالية هي C0 و C1 و C2 . عند الصعود إلى مستويات نقاط التفتيش، يضحي المرء بالسرعة من أجل توفير الذاكرة. أي أن مستوى نقطة التفتيش C0 هو الأسرع، ولكنه يشغل أكبر مساحة على وحدة معالجة الرسومات، بينما C2 هو الأبطأ، ولكنه يشغل أقل مساحة على وحدة معالجة الرسومات. تفاصيل كل مستوى نقطة تفتيش هي كما يلي:
C0 : لا يوجد نقاط تفتيش. تعمل النماذج مع الاحتفاظ بجميع رؤوس الانتباه وطبقات ff في ذاكرة GPU.C1 : نقطة تفتيش لكل انتباه MultiHead وكذلك كل طبقة وما يليها. وبهذا، فإن زيادة depth يجب أن يكون لها تأثير ضئيل على الذاكرة.C2 : إلى جانب التحسينات على المستوى C1 ، قم بفحص كل رأس في كل طبقة MultiHead Attention. مع هذا، فإن زيادة nhead يجب أن يكون لها تأثير أقل على الذاكرة. ومع ذلك، فإن ربط الرؤوس مع torch.cat لا يزال يستهلك قدرًا كبيرًا من الذاكرة، ونأمل أن يتم تحسين ذلك في المستقبل.ولا تزال تفاصيل الأداء غير معروفة، ولكن الخيار موجود للمستخدمين الذين يرغبون في تجربته.
كانت هناك محاولة أخرى لإدخال توفير الذاكرة في الورقة وهي تقديم مشاركة المعلمات بين الإسقاطات. وقد ذكر ذلك في القسم الرابع من الورقة؛ على وجه الخصوص، كان هناك 4 أنواع مختلفة من مشاركة المعلمات التي ناقشها المؤلفون، وتم تنفيذها جميعًا في هذا الريبو. يستهلك الخيار الأول معظم الذاكرة، وكل خيار إضافي يقلل من متطلبات الذاكرة الضرورية.
none : هذه ليست مشاركة المعلمات. لكل رأس ولكل طبقة، يتم حساب مصفوفة E و F جديدة لكل رأس في كل طبقة.headwise : تحتوي كل طبقة على مصفوفة E و F فريدة من نوعها. تشترك جميع الرؤوس في الطبقة في هذه المصفوفة.kv : تحتوي كل طبقة على مصفوفة إسقاط فريدة P ، و E = F = P لكل طبقة. تشترك جميع الرؤوس في مصفوفة الإسقاط هذه P .layerwise : هناك مصفوفة إسقاط واحدة P ، وكل رأس في كل طبقة يستخدم E = F = P كما بدأ في الورقة، هذا يعني أنه بالنسبة لشبكة مكونة من 12 طبقة و12 رأس، سيكون هناك 288 و 24 و 12 و 1 مصفوفة إسقاط مختلفة، على التوالي.
لاحظ أنه مع خيار k_reduce_by_layer ، لن يكون خيار layerwise فعالاً، لأنه سيستخدم البعد k للطبقة الأولى. لذلك، إذا كانت قيمة k_reduce_by_layer أكبر من 0 ، فمن المرجح عدم استخدام خيار المشاركة layerwise .
لاحظ أيضًا أنه وفقًا للمؤلفين، في الشكل 3، لا تؤثر مشاركة المعلمات هذه كثيرًا على النتيجة النهائية. لذلك قد يكون من الأفضل الالتزام بالمشاركة layerwise لكل شيء، ولكن الخيار موجود للمستخدمين لتجربته.
إحدى المشاكل البسيطة في التنفيذ الحالي لـ Linformer هي أن طول التسلسل الخاص بك يجب أن يتطابق مع علامة input_size الخاصة بالنموذج. يقوم Padder بتبطين حجم الإدخال بحيث يمكن تغذية الموتر في الشبكة. مثال:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 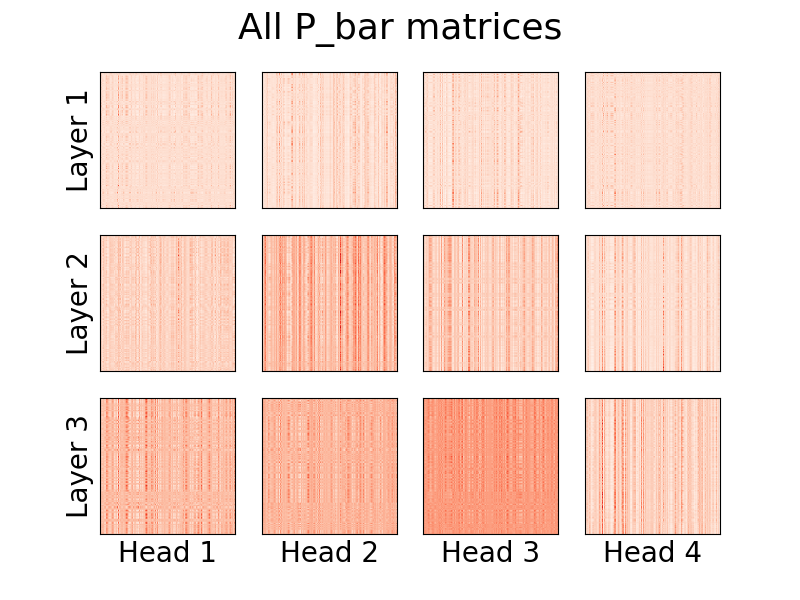
بدءًا من الإصدار 0.8.0 ، يمكن للمرء الآن تصور رؤوس الانتباه في linformer! لرؤية ذلك عمليًا، ما عليك سوى استيراد فئة Visualizer ، وتشغيل وظيفة plot_all_heads() لرؤية صورة لجميع رؤوس الانتباه في كل مستوى، بالحجم (n،k). تأكد من تحديد visualize=True في التمرير الأمامي، حيث يؤدي ذلك إلى حفظ مصفوفة P_bar بحيث تتمكن فئة Visualizer من تصور الرأس بشكل صحيح.
يمكن العثور على مثال عملي للكود أدناه، ويمكن العثور على نفس الكود في ./examples/example_vis.py :
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)ويمكن الاطلاع على شرح مفصل لما تعنيه هذه الرؤوس في رقم 15.
على غرار Reformer، سأحاول إنشاء وحدة التشفير/فك التشفير، بحيث يمكن تبسيط التدريب. يعمل هذا مثل فئتين LinformerLM . يمكن ضبط المعلمات بشكل فردي لكل واحدة، حيث يحتوي جهاز التشفير على البادئة enc_ لجميع المعلمات الفائقة، ويشتمل جهاز فك التشفير على البادئة dec_ بطريقة مماثلة. وما تم تنفيذه حتى الآن هو:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )أخطط للحصول على طريقة لإنشاء تسلسل نصي لهذا الغرض.
ff_intermediate الآن، يمكن أن يكون بُعد النموذج مختلفًا في الطبقات المتوسطة. ينطبق هذا التغيير على وحدة ff، وفقط في برنامج التشفير. الآن، إذا لم تكن العلامة ff_intermediate بلا، فستبدو الطبقات كما يلي:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
على عكس
channels -> ff_dim -> channels (For all layers)
input_size و dim_k على التوالي.apex مع هذا، ولكن في الممارسة العملية، لم يتم اختباره.input_size و k= dim_k و d= dim_d . LinformerEncDec هذه هي المرة الأولى التي أقوم فيها بإعادة إنتاج نتيجة من ورقة، لذلك قد تكون بعض الأشياء خاطئة. إذا رأيت مشكلة، يرجى فتح مشكلة، وسأحاول العمل على حلها.
شكرًا لشركة lucidrains، التي ساعدتني مستودعاتها الأخرى ذات الاهتمام المتناثر في تصميم Linformer Repo.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}"استمع باهتمام..."


