rtdl num embeddings
v0.0.11
مهم
تحقق من نموذج DL الجدولي الجديد: TabM
أرخايف؟ حزمة بايثون مشاريع DL الجدولية الأخرى
هذا هو التنفيذ الرسمي للورقة "حول تضمين الميزات العددية في التعلم العميق الجدولي".
في جملة واحدة: تحويل الميزات العددية المستمرة الأصلية إلى متجهات قبل مزجها في العمود الفقري الرئيسي (على سبيل المثال في MLP، Transformer، وما إلى ذلك) يؤدي إلى تحسين الأداء النهائي للشبكات العصبية الجدولية.
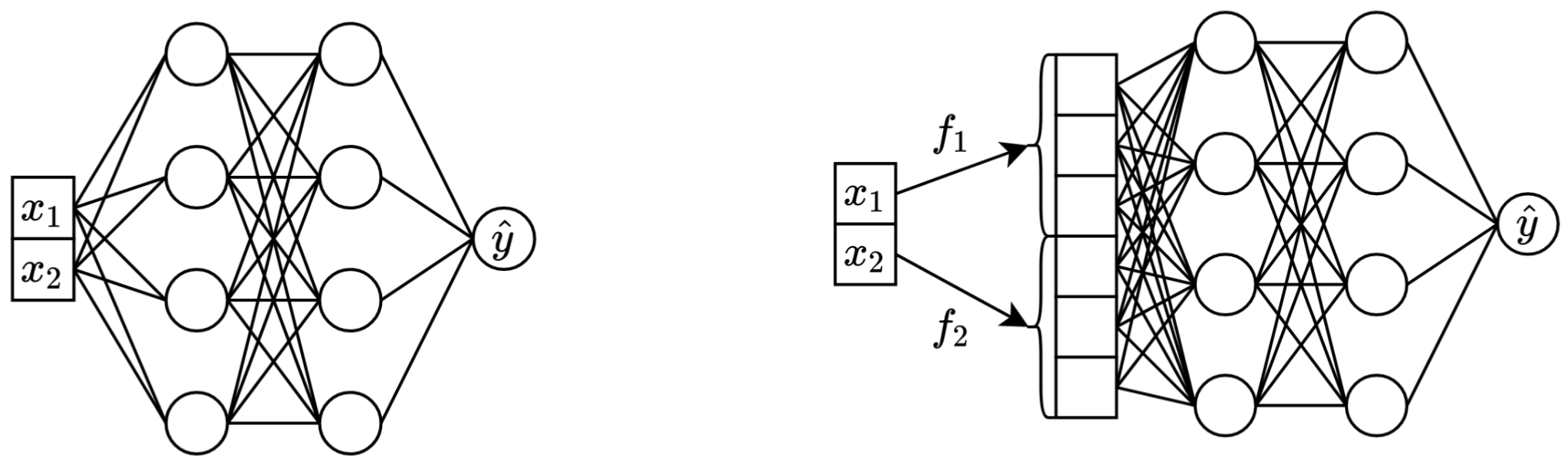
على اليسار: تأخذ Vanilla MLP ميزتين متواصلتين كمدخلات.
على اليمين: نفس MLP، ولكن الآن مع تضمينات للميزات المستمرة.
بمزيد من التفاصيل:
بالمعنى الدقيق للكلمة، لا يوجد تفسير واحد. من الواضح أن التضمينات تساعد في التعامل مع التحديات المختلفة المرتبطة بالميزات المستمرة وتحسين خصائص التحسين الشاملة للنماذج.
على وجه الخصوص، تعد السمات المستمرة الموزعة بشكل غير منتظم (وتوزيعاتها المشتركة غير المنتظمة مع التسميات) أمرًا معتادًا في البيانات الجدولية في العالم الحقيقي، وهي تشكل تحديًا أساسيًا كبيرًا للتحسين لنماذج DL الجدولية التقليدية. مرجع رائع لفهم هذا التحدي (ومثال رائع لمعالجة تلك التحديات عن طريق تحويل مساحة الإدخال) هو الورقة البحثية "ميزات فورييه تسمح للشبكات بتعلم وظائف التردد العالي في المجالات منخفضة الأبعاد".
ومع ذلك، فمن غير الواضح ما إذا كانت التوزيعات غير المنتظمة هي السبب الوحيد الذي يجعل التضمينات مفيدة.
تعد حزمة Python الموجودة في package/ الحزمة هي الطريقة الموصى بها لاستخدام الورقة في الممارسة العملية وفي العمل المستقبلي.
بقية الوثيقة :
يحتوي دليل exp/ على نتائج عديدة ومعلمات تشعبية (مضبوطة) لمختلف النماذج ومجموعات البيانات المستخدمة في الورقة.
على سبيل المثال، دعنا نستكشف مقاييس نموذج MLP. لنقم أولاً بتحميل التقارير (ملفات report.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])الآن، لكل مجموعة بيانات، دعونا نحسب متوسط درجات الاختبار على جميع البذور العشوائية:
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))يتطابق الإخراج تمامًا مع الجدول 3 من الورقة:
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
يمكن أيضًا استخدام الطريقة المذكورة أعلاه لاستكشاف المعلمات الفائقة للتعرف على قيم المعلمات الفائقة النموذجية للخوارزميات المختلفة. على سبيل المثال، هذه هي الطريقة التي يمكن بها حساب متوسط معدل التعلم المضبوط لنموذج MLP:
ملحوظة
بالنسبة لبعض الخوارزميات (مثل MLP، MLP-LR، MLP-PLR)، تقدم المشاريع الأحدث المزيد من النتائج التي يمكن استكشافها بطريقة مماثلة. على سبيل المثال، راجع هذه الورقة على TabR.
تحذير
استخدم هذا النهج بحذر. عند دراسة قيم المعلمات الفائقة:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358مهم
هذا القسم طويل. استخدم ميزة "المخطط التفصيلي" على GitHub في محرر النصوص الخاص بك للحصول على نظرة عامة على هذا القسم.
التصفيات:
/usr/local/cuda-11.1/bin موجود دائمًا في متغير بيئة PATH الخاص بك export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddingsالترخيص: من خلال تنزيل مجموعة البيانات الخاصة بنا، فإنك توافق على تراخيص جميع مكوناتها. ولا نفرض أي قيود جديدة بالإضافة إلى تلك التراخيص. يمكنك العثور على قائمة المصادر في الورقة.
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tarيستنسخ الكود أدناه نتائج MLP في مجموعة بيانات الإسكان في كاليفورنيا. إن خط الأنابيب للخوارزميات ومجموعات البيانات الأخرى هو نفسه تمامًا.
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
يوضح قسم "المقاييس" كيفية تلخيص النتائج التي تم الحصول عليها.
يتم تنظيم الكود على النحو التالي:
bintrain4.py للشبكات العصبية (ينفذ جميع التضمينات والأعمدة الأساسية من الورقة)xgboost_.py لـ XGBoostcatboost_.py لـ CatBoosttune.py للضبطevaluate.py للتقييمensemble.py للتجميعdatasets.py لإنشاء تقسيمات مجموعة البياناتsynthetic.py لإنشاء مجموعات البيانات الاصطناعية الصديقة لـ GBDTtrain1_synthetic.py للتجارب مع البيانات الاصطناعيةlib على الأدوات الشائعة التي تستخدمها البرامج الموجودة في binexp على تكوينات التجربة ونتائجها (المقاييس والتكوينات المضبوطة وما إلى ذلك). تتبع أسماء المجلدات المتداخلة الأسماء الموجودة في الورقة (على سبيل المثال: يتوافق exp/mlp-plr مع نموذج MLP-PLR من الورقة).package على حزمة بايثون لهذه الورقةCUDA_VISIBLE_DEVICES بشكل صريح عند تشغيل البرامج النصيةlib.dump_config و lib.load_config بدلاً من مكتبات TOML العاريةالنمط الشائع لتشغيل البرامج النصية هو:
python bin/my_script.py a/b/c.toml حيث a/b/c.toml هو ملف تكوين الإدخال (config). سيكون الإخراج موجودًا في a/b/c . تتبع بنية التكوين عادةً فئة Config من bin/my_script.py .
هناك أيضًا نصوص برمجية تأخذ وسيطات سطر الأوامر بدلاً من التكوينات (على سبيل المثال bin/{evaluate.py,ensemble.py} ).
أنت بحاجة إليها جميعًا لإعادة إنتاج النتائج، لكنك تحتاج فقط إلى train4.py للعمل المستقبلي، للأسباب التالية:
bin/train1.py مجموعة شاملة من الميزات من bin/train0.pybin/train3.py مجموعة شاملة من الميزات من bin/train1.pybin/train4.py مجموعة شاملة من الميزات من bin/train3.py لمعرفة أي واحد من البرامج النصية الأربعة تم استخدامه لتشغيل تجربة معينة، تحقق من حقل "البرنامج" لتكوين الضبط المقابل. على سبيل المثال، إليك تكوين الضبط لـ MLP في مجموعة بيانات California Housing: exp/mlp/california/0_tuning.toml . يشير التكوين إلى أنه تم استخدام bin/train0.py . هذا يعني أن التكوينات الموجودة في exp/mlp/california/0_evaluation متوافقة بشكل خاص مع bin/train0.py . للتحقق من ذلك، يمكنك نسخ أحدهما إلى موقع منفصل وتمريره إلى bin/train0.py :
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


