minimind
V1

الصينية | انجليزية
يهدف هذا المشروع مفتوح المصدر إلى البدء من الصفر في أقل من 3 ساعات! يمكنك تدريب MiniMind، وهو نموذج لغة مصغر بحجم 26.88 ميجا فقط.
MiniMind خفيف الوزن للغاية، وأصغر إصدار له هو بحجم GPT3 تقريبًا
أصدرت MiniMind نموذجًا كبيرًا للهيكل البسيط، وتنظيف مجموعة البيانات ومعالجتها مسبقًا، والتدريب المسبق تحت الإشراف (Pretrain)، والضبط الدقيق للتعليمات الخاضعة للإشراف (SFT)، والضبط الدقيق للتكيف المنخفض (LoRA)، والتعلم المعزز بدون مكافأة، ومحاذاة التفضيلات المباشرة ( DPO) يتضمن كود المرحلة الكاملة أيضًا توسيع النموذج المتناثر للخبراء الهجين المشتركين (MoE)؛
هذا ليس مجرد تطبيق لنموذج مفتوح المصدر، ولكنه أيضًا برنامج تعليمي للبدء في استخدام نماذج اللغات الكبيرة (LLM).
نأمل أن يوفر هذا المشروع للباحثين مثالًا تمهيديًا لمساعدة الجميع على البدء بسرعة وتوليد المزيد من الاستكشاف والابتكار في مجال LLM.
لمنع سوء الفهم، تعني عبارة "ما يصل إلى 3 ساعات" أنك بحاجة إلى جهاز مزود بتكوين الأجهزة الخاص بي وسيتم توفيره أدناه.

اختبار ModelScope عبر الإنترنت | رابط فيديو بيليبيلي
في مجال نماذج اللغات الكبيرة (LLM)، مثل GPT وLLaMA وGLM وما إلى ذلك، على الرغم من أن تأثيراتها مذهلة، إلا أن معلمات النموذج الضخمة البالغة 10 مليار وذاكرة الأجهزة الشخصية بعيدة كل البعد عن أن تكون كافية للتدريب، وحتى الاستدلال صعب. الجميع تقريبًا غير راضين عن مجرد ضبط النماذج الكبيرة باستخدام برامج مثل Lora لتعلم بعض التعليمات الجديدة، وهذا يشبه تقريبًا تعليم نيوتن اللعب باستخدام هاتف ذكي في القرن الحادي والعشرين الفيزياء نفسها. بالإضافة إلى ذلك، فإن حسابات التسويق التي تبيع دورات الاشتراك المدفوعة مليئة بالثغرات والبرامج التعليمية التي تشرح الذكاء الاصطناعي بنصف المعرفة فقط، مما يجعل فهم المحتوى عالي الجودة لماجستير في القانون أكثر صعوبة ويعيق المتعلمين بشكل خطير.
ولذلك، فإن الهدف من هذا المشروع هو خفض الحد الأدنى لبدء دراسة LLM وتدريب نموذج لغة خفيف الوزن للغاية مباشرة من الصفر.
نصيحة
(اعتبارًا من 17 سبتمبر 2024) أكملت سلسلة MiniMind التدريب المسبق لثلاثة نماذج من النماذج. الحد الأدنى المطلوب هو 26 مليونًا فقط (0.02 بايت) للحصول على إمكانات محادثة سلسة!
| النموذج (الحجم) | طول الرمز المميز | شغل المنطق | يطلق | التقييم الذاتي (/100) |
|---|---|---|---|---|
| ميني مايند-v1-صغير (26 ميجا) | 6400 | 0.5 جيجابايت | 2024.08.28 | 50' |
| minimind-v1-moe (4 × 26 ميجا) | 6400 | 1.0 جيجابايت | 17.09.2024 | 55' |
| ميني مايند-v1 (108 ميجا) | 6400 | 1.0 جيجابايت | 2024.09.01 | 60' |
تم إجراء التحليل على وحدة معالجة الرسومات 2×RTX 3090 مع Torch 2.1.2 وCUDA 12.2 وFlash Attention 2.
يتضمن المشروع:
transformers ، accelerate ، trl ، peft ، وما إلى ذلك.آمل أن يساعد هذا المشروع مفتوح المصدر مبتدئي LLM على البدء بسرعة!
يوسع قدرات MiniMind المتعددة الوسائط - الرؤية
انتقل إلى المشروع المزدوج minimind-v لعرض التفاصيل!
09-27 تم تحديث طريقة المعالجة المسبقة لمجموعة بيانات التدريب المسبق من أجل ضمان سلامة النص، تم التخلي عن المعالجة المسبقة وتحويلها إلى تدريب .bin (التضحية قليلاً بسرعة التدريب).
يُسمى الملف الحالي بعد معالجة التدريب المسبق: pretrain_data.csv.
تمت إزالة بعض التعليمات البرمجية الزائدة عن الحاجة.
تحديث نموذج minimind-v1-moe
من أجل منع الغموض، لم يعد يتم استخدام Mistral_tokenizer كتجزئة للكلمات، ويتم استخدام كل minimind_tokenizer المخصص كتجزئة للكلمات.
تم تحديث نموذج minimind-v1 (108M)، باستخدام minimind_tokenizer، وجولات التدريب المسبق 3 + جولات SFT 10، وأداء أكثر تدريبًا وأقوى.
تم نشر المشروع في مساحة إنشاء ModelScope ويمكن تجربته على هذا الموقع:
?ModelScope تجربة على الانترنت؟
هذا هو مجرد تكوين بيئة البرامج والأجهزة الشخصية الخاصة بي، يرجى تغييره وفقًا لتقديرك الخاص:
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
内存:128 GB
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练MiniMind (معانقة الوجه)
ميني مايند (موديل سكوب)
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1 # step 2
python 2-eval.pyأو ابدأ البث المباشر وابدأ واجهة الدردشة عبر الويب
"ملاحظة" تتطلب python>=3.10، تثبيت
pip install streamlit==1.27.2
# or step 3, use streamlit
streamlit run fast_inference.py0. استنساخ رمز المشروع
git clone https://github.com/jingyaogong/minimind.git
cd minimind1. تركيب البيئة
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
إذا لم يكن متاحًا، فيرجى الانتقال إلى torch_stable لتنزيل ملف whl وتثبيته بنفسك. الرابط المرجعي
2. إذا كنت بحاجة إلى تدريب نفسك
2.1 قم بتنزيل عنوان تنزيل مجموعة البيانات ووضعه في الدليل ./dataset .
2.2 تقوم python data_process.py بمعالجة مجموعات البيانات، على سبيل المثال، يتم تشفير بيانات التدريب المسبق بالرمز المميز مسبقًا، ويتم استخراج مجموعات بيانات sft من qa إلى ملفات csv.
2.3 اضبط تكوين معلمة النموذج في ./model/LMConfig.py
هنا تحتاج فقط إلى ضبط معلمات dim وn_layers وuse_moe، وهي
(512+8)أو(768+16)على التوالي، والتي تتوافق معminimind-v1-smallوminimind-v1
2.4 python 1-pretrain.py ينفذ تدريبًا مسبقًا ويحصل على pretrain_*.pth كوزن الإخراج للتدريب المسبق
2.5 python 3-full_sft.py ينفذ الضبط الدقيق للتعليمات ويحصل على full_sft_*.pth كوزن الإخراج للضبط الدقيق للتعليمات
2.6 python 4-lora_sft.py يقوم بإجراء ضبط دقيق لورا (غير مطلوب)
2.7 python 5-dpo_train.py ينفذ محاذاة التعلم المعزز لتفضيلات الإنسان DPO (اختياري)
3. اختبار تأثير الاستدلال النموذجي
*.pth التي يجب استخدامها وإكمال التدريب موجودة في الدليل ./out/ .*.pth الخاص بي. minimind/out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
python 0-eval_pretrain.py تأثير السوليتير للنموذج المُدرب مسبقًاpython 2-eval.py يختبر تأثير حوار النموذج 
"نصيحة" التدريب المسبق والضبط الدقيق للمعلمات الكاملة والتدريب المسبق الكامل وfull_sft كلاهما يدعمان تسريع البطاقات المتعددة
على افتراض أن جهازك يحتوي على بطاقة رسومات واحدة فقط، فما عليك سوى استخدام لغة بايثون الأصلية لبدء التدريب:
python 1-pretrain.py
# and
python 3-full_sft.pyافترض أن جهازك يحتوي على بطاقات رسومات N (N>1):
التدريب على بدء تشغيل بطاقة N المستقلة (DDP)
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.pyالتدريب على بدء تشغيل بطاقة N المستقلة (DeepSpeed)
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.pyتمكين wandb لتسجيل عملية التدريب (اختياري)
torchrun --nproc_per_node N 1-pretrain.py --use_wandb
# and
python 1-pretrain.py --use_wandb عن طريق إضافة المعلمة --use_wandb ، يمكن تسجيل عملية التدريب، وبعد اكتمال التدريب، يمكن عرض عملية التدريب على موقع الويب الخاص بـ Wandb. من خلال تعديل معلمات wandb_project و wandb_run_name ، يمكنك تحديد اسم المشروع واسم التشغيل.
Tokenizer: يشبه Tokenizer في البرمجة اللغوية العصبية القاموس، فهو يقوم بتعيين الكلمات من اللغة الطبيعية إلى أرقام مثل 0 و1 و36 من خلال "القاموس". "القاموس". هناك طريقتان لإنشاء رمز مميز لـ LLM: إحداهما هي إنشاء قائمة كلمات بنفسك لتدريب رمز مميز، ويمكن العثور على الكود train_tokenizer.py والأخرى هي اختيار رمز مميز تم تدريبه بواسطة نموذج مفتوح المصدر. بالطبع، يمكنك اختيار قاموس شينهوا أو قاموس أكسفورد مباشرة لـ "القاموس". والميزة هي أن معدل ضغط تحويل الرمز جيد جدًا، ولكن العيب هو أن قائمة المفردات طويلة جدًا، وتحتوي على مئات الآلاف من عبارات المفردات. يمكنك أيضًا استخدام أداة تقطيع الكلمات المدربة الخاصة بك والميزة هي أنه يمكن التحكم في قائمة الكلمات حسب الرغبة. العيب هو أن معدل الضغط ليس مثاليًا بما فيه الكفاية، وليس من السهل تغطية جميع الكلمات النادرة. بالطبع، يعد اختيار "القاموس" أمرًا مهمًا. إن إخراج LLM هو في الأساس مشكلة متعددة التصنيفات لكلمات N من SoftMax إلى القاموس، ثم يتم فك تشفيرها إلى لغة طبيعية من خلال "القاموس". نظرًا لأن LLM صغير جدًا، لتجنب أن يكون النموذج ثقيلًا للغاية (نسبة معلمات طبقة تضمين الكلمات إلى LLM بأكملها مرتفعة جدًا)، يجب اختيار طول المفردات ليكون صغيرًا نسبيًا. تحتوي النماذج القوية مفتوحة المصدر مثل 01 Wanwu وQianwen وchatglm وmistral وLlama3 وما إلى ذلك على أطوال مفردات الرموز المميزة التالية:
| نموذج الرمز المميز | حجم المفردات | مصدر |
|---|---|---|
| يي رمزية | 64000 | 01 كل شيء (الصين) |
| رمز qwen2 | 151,643 | علي بابا كلاود (الصين) |
| رمز glm | 151,329 | الحكمة الذكاء الاصطناعي (الصين) |
| رمز ميسترال | 32000 | ميسترال إيه آي (فرنسا) |
| رمز اللاما3 | 128,000 | ميتا (الولايات المتحدة) |
| minimind tokenizer | 6400 | تخصيص |
التحديث 17-09-2024: من أجل منع الغموض والتحكم في مستوى الصوت في الإصدارات السابقة، تستخدم جميع نماذج minimind تجزئة الكلمات minimind_tokenizer ويتم التخلي عن جميع إصدارات Mistral_tokenizer.
على الرغم من أن طول minimind_tokenizer صغير جدًا، إلا أن كفاءة التشفير وفك التشفير أضعف من الرموز المميزة الصينية مثل qwen2 وglm. ومع ذلك، اختار نموذج minimind أداة minimind_tokenizer المدربة الخاصة به كمقطع للكلمات للحفاظ على المعلمات العامة خفيفة الوزن وتجنب عدم التوازن في نسبة طبقة التشفير وطبقة الحساب، وهي طبقة ثقيلة للغاية، لأن حجم مفردات minimind هو فقط 6400. بالإضافة إلى ذلك، لم يفشل minimind في فك رموز الكلمات النادرة في الاختبارات الفعلية، وكانت النتائج جيدة. نظرًا لأن قائمة الكلمات المخصصة مضغوطة إلى 6400 كلمة، فإن الحجم الإجمالي لمعلمة LLM يصل إلى 26 مليونًا.
?[بيانات التدريب المسبق]: يتم تجميع مجموعة البيانات النصية العالمية Seq-Monkey/قرص شبكة Seq-Monkey Baidu وتنظيفها من مجموعة متنوعة من بيانات المصادر العامة (مثل صفحات الويب والموسوعات والمدونات والأكواد مفتوحة المصدر والكتب وما إلى ذلك) . تم تنظيمها في تنسيق JSONL موحد وخضعت لفحص صارم وإلغاء البيانات المكررة لضمان شمولية البيانات وحجمها ومصداقيتها وجودتها العالية. المبلغ الإجمالي هو حوالي 10 مليار رمز، وهو مناسب للتدريب المسبق لنماذج اللغة الصينية الكبيرة.
الخيار 2: يحتوي الجزء المتاح للجمهور من مجموعة بيانات SkyPile-150B على ما يقرب من 233 مليون صفحة ويب فريدة، تحتوي كل منها على ما يزيد عن 1000 حرف صيني في المتوسط. تتضمن مجموعة البيانات ما يقرب من 150 مليار رمز مميز و620 جيجابايت من البيانات النصية العادية. إذا كنت في عجلة من أمرك ، فيمكنك محاولة تحديد جزء فقط من تنزيل jsonl لـ SkyPile-150B (وإنشاء ملف *.csv لرمز النص في ./data_process.py) للتشغيل بسرعة خلال عملية التدريب المسبق .
قم بالتنزيل إلى الدليل ./dataset/
| مجموعة بيانات تدريب MiniMind | عنوان التحميل |
|---|---|
| [مجموعة تدريب الرموز المميزة] | معانقة الوجه / بايدو Netdisk |
| 【بيانات ما قبل التدريب】 | مسؤول Seq-Monkey/قرص شبكة Baidu/HuggingFace |
| 【بيانات SFT】 | مجموعة بيانات Jiangshu ذات النموذج الكبير SFT |
| 【بيانات DPO】 | وجه يعانق |
يستخدم MiniMind-Dense (مثل Llama3.1) بنية وحدة فك التشفير فقط للمحول، والفرق عن GPT-3 هو:
نموذج MiniMind-MoE، يعتمد هيكله على Llama3 ووحدة الخبراء المختلطة MixFFN في Deepseek-V2.
الهيكل العام لـ MiniMind هو نفسه، باستثناء بعض التعديلات الطفيفة في كود حساب RoPE ووظيفة الاستدلال وطبقة FFN. هيكلها كما يلي (النسخة المعاد رسمها):
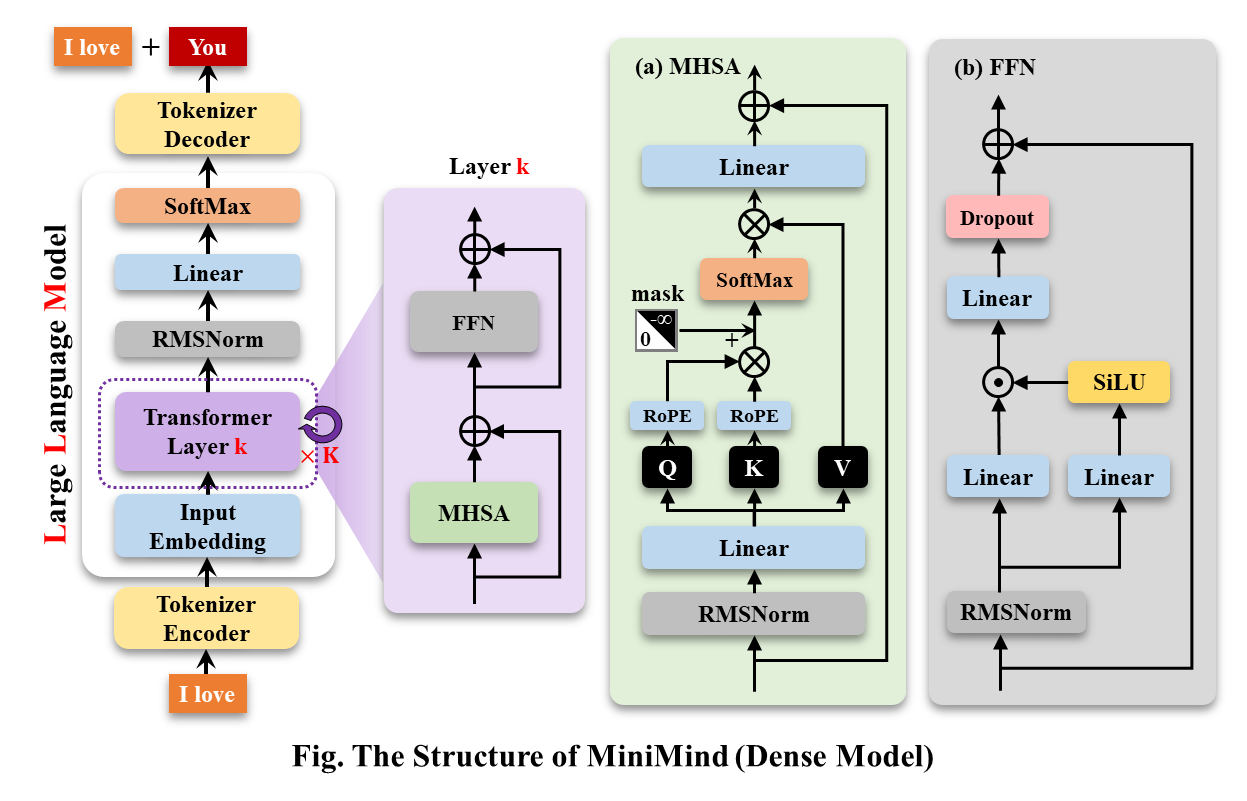
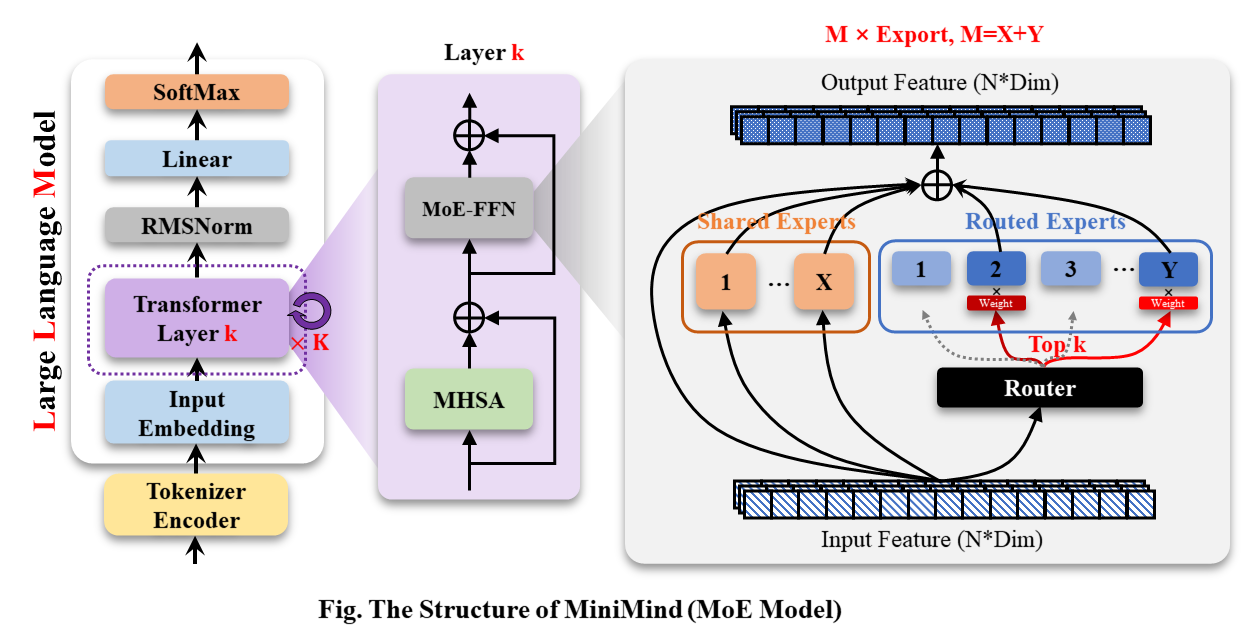
لتعديل تكوين النموذج، راجع ./model/LMConfig.py. يتم عرض إصدارات النماذج التي تم تدريبها حاليًا بواسطة minimind في الجدول أدناه:
| اسم النموذج | المعلمات | len_vocab | n_layers | d_model | kv_heads | q_heads | حصة + الطريق | توبك |
|---|---|---|---|---|---|---|---|---|
| minimind-v1-small | 26 م | 6400 | 8 | 512 | 8 | 16 | - | - |
| minimind-v1-moe | 4 × 26 م | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| minimind-v1 | 108 م | 6400 | 16 | 768 | 8 | 16 | - | - |
| اسم النموذج | المعلمات | len_vocab | Batch_size | pretrain_time | sft_single_time | sft_multi_time |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26 م | 6400 | 64 | ≈2 ساعة (1 عصر) | ≈2 ساعة (1 عصر) | ≈0.5 ساعة (عصر واحد) |
| minimind-v1-moe | 4 × 26 م | 6400 | 40 | ≈6 ساعات (1 عصر) | ≈5 ساعات (1 عصر) | ≈1 ساعة (1 عصر) |
| minimind-v1 | 108 م | 6400 | 16 | ≈6 ساعات (1 عصر) | ≈4 ساعات (1 عصر) | ≈1 ساعة (1 عصر) |
التدريب المسبق (تحويل النص إلى نص) :
يتم تعيين معدل التعلم للتدريب المسبق على معدل التعلم الديناميكي من 1e-4 إلى 1e-5، ويتم تعيين عدد فترات التدريب المسبق على 5.
torchrun --nproc_per_node 2 1-pretrain.pyضبط الحوار الفردي :
من خلال ضبط الفرق الخطي للحبل أثناء الاستدلال، يكون من المناسب استقراء الطول إلى 1024 أو 2048 وما فوق. يتم ضبط معدل التعلم على معدل تعلم ديناميكي من 1e-5 إلى 1e-6، وعدد عصور الضبط الدقيق هو 6.
# 3-full_sft.py中设置数据集为sft_data_single.csv
torchrun --nproc_per_node 2 3-full_sft.pyضبط الحوار المتعدد :
يتم ضبط معدل التعلم على معدل تعلم ديناميكي من 1e-5 إلى 1e-6، وعدد عصور الضبط الدقيق هو 5.
# 3-full_sft.py中设置数据集为sft_data.csv
torchrun --nproc_per_node 2 3-full_sft.pyالتعلم المعزز بالتغذية الراجعة البشرية (RLHF) - تحسين التفضيلات المباشرة (DPO) :
مجموعة بيانات ثلاثية من النوع المتحرك (q، اختر، رفض)، معدل التعلم le-5، نصف الدقة fp16، إجمالي فترة واحدة، ويستغرق ساعة واحدة.
python 5-dpo_train.py فيما يتعلق بتكوين معلمات LLM، هناك ورقة بحثية مثيرة للاهتمام للغاية بعنوان MobileLLM تقوم بإجراء أبحاث وتجارب مفصلة. قانون القياس له قواعده الفريدة في النماذج الصغيرة. تعتمد المعلمات التي تتسبب في تغيير حجم معلمات المحول بشكل حصري تقريبًا على d_model و n_layers .
d_model ↑+ n_layers ↓->هامبتي دمبتيd_model ↓+ n_layers ↑->نحيف وطويل القامة تعتقد الورقة التي تقترح قانون القياس في عام 2020 أن كمية بيانات التدريب، وكمية المعلمات، وعدد تكرارات التدريب هي العوامل الرئيسية التي تحدد الأداء، ويمكن تجاهل تأثير بنية النموذج تقريبًا. ومع ذلك، يبدو أن هذا القانون لا ينطبق بشكل كامل على النماذج الصغيرة. يقترح MobileLLM أن عمق البنية أكثر أهمية من العرض. يمكن للنموذج "النحيف" "العميق والضيق" أن يتعلم مفاهيم أكثر تجريدًا من النموذج "الواسع والسطحي". على سبيل المثال، عندما تكون معلمات النموذج ثابتة عند 125 مترًا أو 350 مترًا، فإن النموذج "الضيق" الذي يحتوي على 30 إلى 42 طبقة يتمتع بأداء أفضل بكثير من النموذج "القصير والسمين" الذي يحتوي على حوالي 12 طبقة، في 8 اختبارات مرجعية مثل المنطق السليم والسؤال والجواب، وفهم القراءة هناك اتجاهات مماثلة. يعد هذا في الواقع اكتشافًا مثيرًا للاهتمام للغاية، لأنه في الماضي، عند تصميم بنيات لنماذج صغيرة يبلغ حجمها حوالي 100 مليون، لم يحاول أحد تقريبًا تكديس أكثر من 12 طبقة. يتوافق هذا مع التأثير الذي تمت ملاحظته تجريبيًا لـ MiniMind الذي يقوم بضبط معلمات النموذج بين d_model و n_layers أثناء عملية التدريب. ومع ذلك، فإن "العمق والضيق" له أيضًا حد للبعد عندما يكون d_model<512، يكون عيب انهيار أبعاد تضمين الكلمات واضحًا جدًا، ولا يمكن للطبقات المضافة تعويض عيب d_head غير الكافي الناتج عن تضمين الكلمات في q_head ثابت. عندما d_model>1536، يبدو أن زيادة الطبقات لها أولوية أعلى من d_model، ويمكن أن تجلب المزيد من المعلمات "الفعالة من حيث التكلفة" -> زيادة التأثير. لذلك، يقوم MiniMind بتعيين d_model=512 وn_layers=8 للنموذج الصغير للحصول على توازن "الحجم الصغير جدًا <-> تأثير أفضل". قم بتعيين d_model=768, n_layers=16 للحصول على فوائد أكبر من التأثير، والذي يتماشى أكثر مع المنحنى المتغير لقانون القياس للنماذج الصغيرة.
كمرجع، تظهر إعدادات معلمات GPT3 في الجدول أدناه:
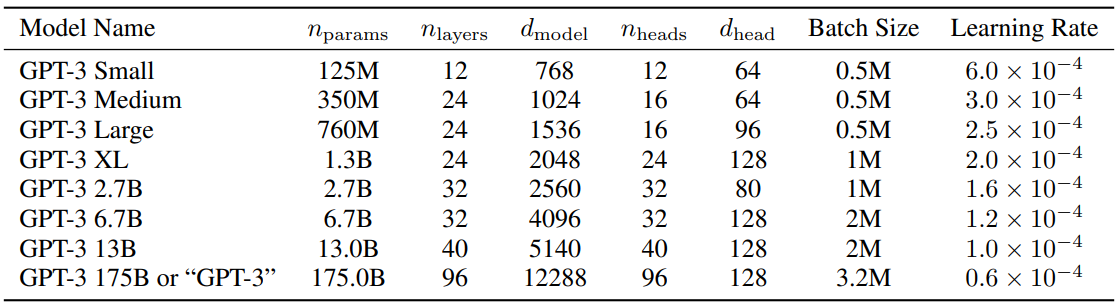
?بايدو نت ديسك
| اسم النموذج | المعلمات | التكوين | pretrain_model | Single_sft_model | multi_sft_model | rl_model |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26 م | d_model=512 n_layers=8 | pretrain_512.pth | single_chat/full_sft_512.pth | multi_chat/full_sft_512.pth | rl_512.pth |
| minimind-v1-moe | 4 × 26 م | d_model=512 n_layers=8 | pretrain_512_moe.pth | single_chat/full_sft_512_moe.pth | multi_chat/full_sft_512_moe.pth | - |
| minimind-v1 | 108 م | d_model=768 n_layers=16 | pretrain_768.pth | single_chat/full_sft_768.pth | multi_chat/full_sft_768.pth | rl_768.pth |
نصيحة
اختبر مقارنة نموذج minimind استنادًا إلى "الحوار أحادي الجولة full_sft" و"محاذاة التعلم المعزز DPO".
ملف النموذج Baidu Netdisk، حيث rl_<dim>.pth هو وزن نموذج minimind بعد "محاذاة التعلم المعزز DPO".
[Q]: 你叫什么名字?
[ft_768]: 我是一款人工智能语言模型,可以回答您的问题和提供帮助。您有什么需要我帮忙的吗?
[rl_768]: 我是一款基于人工智能技术的自然语言处理系统,主要用于处理和生成人类语言的任务。我可以帮助用户进行文本处理、语音识别、文本生成等任务,同时也可以帮助用户进行智能聊天、翻译、翻译等多种应用。如果您需要更多关于该项目的信息,请告诉我。
[ft_512]: 我很高兴能够帮助你。你有什么其他问题需要我帮忙解答吗?
[rl_512]: 我是一款基于自然语言处理技术的聊天机器人,能够理解和回复用户的问题和指令,并进行相应的回复和回复。我被训练为能够与人类进行交互和回答各种问题和任务。请问有什么需要吗?
[Q]: 你是谁?
[ft_768]: 我是一个人工智能语言模型,没有个人身份和身份。我只是根据输入的指令和文本信息生成响应。
[rl_768]: 我是一个计算机程序,没有个人身份或身份。我被设计来回答各种问题和提供帮助,包括回答问题、提供建议、进行实验、提供信息等等。我被广泛应用于各种领域,例如自然语言处理、计算机视觉、人工智能等等。如果您需要更多的帮助或信息,请随时与我联系。我会尽我所能来帮助您的工作和生活。
[ft_512]: 我是一个大型语言模型,可以回答各种各样的问题,包括科学、历史、文化和技术方面的问题。您有什么需要我回答的问题吗?
[rl_512]: 我是一个计算机程序,没有具体的身世和人物。如果您可以告诉我您想知道的具体信息,我会尽力回答您的问题。
[Q]: 中国有哪些比较好的大学?
[ft_768]: 中国有很多著名的大学,其中包括北京大学、上海交通大学、复兴中医药学院、浙江大学等。这些大学在不同的领域都有着自己的标志性建筑和研究方向,值得一提的是,它们在中国的顶尖教育资源中享有很高的声誉。
[rl_768]: 中国的大学有很多,具体情况还要根据你的需求来决定。如果你需要更详细的信息,建议可以去咨询一下你所在城市的大学排名和政策法规,从而选择一个合适的大学。同时,你可以在网上查阅相关信息,或者去咨询一些大学相关机构,如中国人民大学、中国人民大学等,以获得更为详细和专业的指导和建议。
[ft_512]: 中国有很多优秀的大学,比如麻省理工学院、北京大学、上海大学等等。这些大学在中国教育事业的发展和成就都非常突出。
[rl_512]: 中国教育局、中国大学、中国大陆大学和中国大陆大学均有优秀的教育体裁,但各地教育水平和专业要求都可能存在差异。中国教育局的学历要求、教学方法、师资力量等因素都各具特点,而大学的学历要求也各有千秋。中国大陆大学生的学历要求也各有不同,需要根据自己的实际情况进行选择。如果您对中国大陆大学生的专业要求有更具体需求,建议您可以通过互联网、国内外的各类机构和机构进行比较和交流。同时,您也可以向身边的人或朋友、老师、家长等人士寻求帮助和建议。希望以上回答对您有帮助。
[Q]: 你知道光速是多少吗?
[ft_768]: 光速是一个物理常数,表示光在真空中传播的速度,大约是每秒299792458米。光速是物理学中最基本的物理常数之一,也是相对论的重要基础之一。
[rl_768]: 当然知道,光速是光在真空中传播的速度,通常用c来表示。它是宇宙物理学中非常重要的理论之一。在物理学中,光速被认为是宇宙中最重要的速度之一。它代表着光在真空中传播的速度,这也是许多重要公式和公式的基础。
[ft_512]: 光速是光在真空中传播的速度,约为每秒299,792,458米。它是几乎所有的物理学概念,也是宇宙中最神秘和最重要的物理概念之一。
[rl_512]: 光速是光在真空中传播的速度,是自然界中不可逆转的速度。光源是由光的原子、分子、固体和光的组成,其速度约为每秒平方。光的速度是每秒约1个英亞或光年,这个数字是根据相对论、量子力学和引力理论来计算的。光速是相对的概念之一,它代表着我们对自然界中任何事件的理解和解释。
نصيحة
تم الانتهاء من الاختبار التالي بتاريخ 17-09-2024 ولن يتم تضمين الموديلات الجديدة التي تم إصدارها بعد هذا التاريخ في الاختبار ما لم تكن هناك احتياجات خاصة. اختبر نموذج العقل المصغر استنادًا إلى حوار أحادي الجولة full_sft (بدون ضبط دقيق متعدد الجولات وضبط التعلم المعزز).
[أ] minimind-v1-small(0.02B)
[B] minimind-v1-moe(0.1B)
[C] minimind-v1(0.1B)
[D] لاما صغير 2 صيني (0.2ب)
[E] chatlm-mini-chinese(0.2B)
[Q]: 你知道长江吗?
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
[B]: 长江是中国最长的河流,总长度约为6300公里。它发源于青藏高原的青海湖,流经青海、四川、甘肃、宁夏、内蒙古、陕西和山西。长江流域是中国最大的农业区之一,也是中国的文化和经济中心。
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
[Q]: 第一颗人造卫星是哪个国家发射的?
[A]: 第一颗人造卫星是斯普特尼克1号。
[B]: 第一颗人造卫星是俄罗斯的国际卫星,于1957年发射。
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
[Q]: 你知道泰山在哪里吗?
[A]: 泰山位于中国东部地区,是中国五岳之一。
[B]: 泰山位于山东省泰安市泰安市。泰安市是中国五岳之一,也是世界文化遗产和中国历史文化名山之一。泰安市有许多著名的景点,如五岳之一、玉皇顶、南天门、玉皇阁等。
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
[Q]: 世界上最高的山峰是什么?
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
[B]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848米。
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
[Q]: 万有引力是谁提出的?
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
[B]: 万有引力是由牛顿在1687年提出的。它是宇宙中一个基本的物理现象,它描述了物体之间的相互作用。这个力被称为万有引力,它在所有物体之间都存在,这种力与物体的质量和距离有关。万有引力是自然界中最基本的力量之一,它不仅影响着物体的运动和变化,还对宇宙的结构和演化产生着重要的影响。
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
[Q]: 你知道大熊猫的主要食物是什么吗?
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
[B]: 是的,大熊猫主要以竹子为食。它们每天需要吃掉大量的竹子来维持生命,每天需要吃掉40至80公斤的竹子。此外,它们也会吃一些其他的植物,如草、果实、坚果和小型哺乳动物。
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
[D]: 大熊猫的主要食物是竹子。
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
[Q]: 海水为什么是咸的?
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
[B]: 海水是咸的,这是因为它含有大量的盐分,其中包括氯离子和氯离子。这些离子在海洋中形成了大量的盐,这些盐分被称为盐分。海水中含有许多溶解在水中的盐,这些盐分会随着海水的升高而逐渐蒸发,最终导致海水中盐分的蒸发。这些盐分在海水中被完全消耗,然后被排除在海水中。此外,海水中还含有许多其他的盐分,但这些盐分是不同的,因为它们在水中的浮起和下降过程是不同的。海水中的盐分是从海底的岩石中提取出来的,这些盐分在海水中可以被利用。总的来说,海水是咸的,这也是为什么海水中含有许多盐分和盐分的原因。
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
ملحوظة
♂️ قم بإلقاء إجابة النموذج أعلاه مباشرة إلى GPT-4o ودعها تساعد في النتيجة:
النموذج أ :
النموذج ب :
الموديل ج :
الموديل د :
الموديل ه :
| نموذج | ج | ه | ب | أ | د |
|---|---|---|---|---|---|
| جزء | 75 | 70 | 65 | 60 | 50 |
يتماشى فرز سلسلة minimind (ABC) مع الحدس، وحصل minimind-v1 (0.1B) على أعلى الدرجات. الإجابات على الأسئلة المنطقية خالية بشكل أساسي من الأخطاء والأوهام.
epochs minimind-v1 (0.1B) أقل من 2. أنا كسول جدًا بحيث لا يمكنني القتل مقدمًا لتحرير الموارد للنموذج الصغير 0.1B لا يزال يحقق أقوى أداء على الرغم من أنه لم يكن كاملاً في الواقع، لا يزال مستوى أعلى من المستوى السابق.تبدو إجابة النموذج E جيدة جدًا للعين المجردة، على الرغم من وجود بعض الهلوسة والافتراءات. ومع ذلك، فقد اتفق تقييم كل من GPT-4o و Deepseek على أنه يحتوي على "معلومات طويلة جدًا، ومحتوى متكرر، وأوهام". في الواقع، هذا النوع من التقييم صارم بعض الشيء. حتى لو كانت 10 كلمات من أصل 100 عبارة عن هلوسة، فمن السهل أن يتم منحها درجة منخفضة. نظرًا لأن طول نص التدريب المسبق للنموذج E أطول ومجموعة البيانات أكبر بكثير، فإن الإجابات تبدو كاملة. في حالة تقريب الحجم، تعتبر كمية ونوعية البيانات مهمة.
♂️التقييم الشخصي الشخصي: E>C>B≈A>D
تصنيف GPT-4o: C>E>B>A>D
قانون القياس: كلما كانت معلمات النموذج أكبر وزادت بيانات التدريب، كان أداء النموذج أقوى.
راجع رمز تقييم C-Eval: ./eval_ceval.py لتجنب صعوبة تثبيت تنسيق الرد، عادةً ما يحدد تقييم النماذج الصغيرة بشكل مباشر احتمال التنبؤ بالرمز المميز المطابق للأحرف الأربعة A و B و C و D ، ويأخذ الإجابة الأكبر ويحسب معدل الدقة مع الإجابة القياسية. لم يستخدم نموذج minimind نفسه مجموعة بيانات أكبر للتدريب، كما أنه لم يضبط التعليمات للإجابة على أسئلة الاختيار من متعدد. ويمكن استخدام نتائج التقييم كمرجع.
على سبيل المثال، تفاصيل نتيجة minimind-small:
| يكتب | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | واحد وعشرون | إثنان وعشرون | ثلاثة وعشرين | أربعة وعشرون | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| بيانات | احتمال_والإحصائيات | قانون | middle_school_biology | كيمياء_الثانوية_الثانوية | فيزياء_الثانوية_الثانوية | legal_professional | ثانوية_الصينية | High_school_history | Tax_accountant | Modern_chines_history | #فيزياء_المدرسة_المتوسطة | middle_school_history | basic_medicine | نظام التشغيل | منطق | electric_engineer | Civil_servant | اللغة الصينية والأدب | College_programming | محاسب | حماية النبات | #كيمياء_المدرسة_المتوسطة | مهندس_قياسي | veterinary_medicine | الماركسية | Advanced_mathematics | ثانوية_الرياضيات | إدارة الأعمال | mao_zedong_thinkt | الثقافة_الإيديولوجية_والأخلاقية | كلية_الاقتصاد | Professional_tour_guide | مهندس_تقييم_الأثر_البيئي | Computer_architecture | Urban_and_rural_planner | College_physics | middle_school_mathematics | سياسة_المدرسة_الثانوية | طبيب | College_chemistry | High_school_biology | ثانوية_الجغرافيا | middle_school_politics | Clinical_medicine | Computer_network | sports_science | art_studies | teacher_qualification | الرياضيات المنفصلة | education_science | fire_engineer | #جغرافيا_المدرسة_المتوسطة |
| يكتب | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | واحد وعشرون | إثنان وعشرون | ثلاثة وعشرين | أربعة وعشرون | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| تي/أ | 3/18 | 24/05 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 7/31 | 21/06 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 21/06 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 31/09 | 1/12 |
| دقة | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
总题数: 1346
总正确数: 316
总正确率: 23.48%
| فئة | صحيح | question_count | دقة |
|---|---|---|---|
| minimind-v1-small | 344 | 1346 | 25.56% |
| minimind-v1 | 351 | 1346 | 26.08% |
### 模型擅长的领域:
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
### 模型不擅长的领域:
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体系结构(9.52%),在这些计算机专业课程上的表现也不够好。
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
### 总结:
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
يمكن لـ ./export_model.py تصدير النموذج إلى تنسيق المحولات ودفعه إلى Huggingface
عنوان مجموعة MiniMind المعانقة: MiniMind
يكمل my_openai_api.py واجهة الدردشة الخاصة بـ openai_api، مما يجعل من السهل توصيل النماذج الخاصة بك بواجهات مستخدم خارجية مثل fastgpt، وOpenWebUI، وما إلى ذلك.
قم بتنزيل ملف وزن النموذج من Huggingface
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
ابدأ تشغيل خادم الدردشة
python my_openai_api.pyواجهة خدمة الاختبار
python chat_openai_api.pyمثال على واجهة API، متوافقة مع تنسيق openai API
curl http://ip:port/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "世界上最高的山是什么?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
} ' 
نصيحة
إذا كنت تشعر أن MiniMind مفيد لك، يمكنك إضافة مقال على GitHub. الطول ليس قصيرًا والمستوى محدود، فنحن نرحب بك لتبادل التصحيحات في المشكلات أو تقديم مشاريع تحسين العلاقات العامة القوة الدافعة للتحسين المستمر للمشروع.
ملحوظة
الجميع يضيف الوقود إلى النيران إذا حاولت تدريب نموذج MiniMind جديد، فنحن نرحب بمشاركة أوزان النموذج الخاص بك في المناقشات أو المشكلات، ويمكن أن يكون ذلك في مهام فرعية محددة أو مجالات رأسية (مثل التعرف على المشاعر، أو المجال الطبي، أو النفسي). ، أسئلة وأجوبة مالية وقانونية، وما إلى ذلك.) إصدار نموذج MiniMind الجديد ويمكن أيضًا أن يكون إصدارًا جديدًا لنموذج MiniMind بعد تدريب ممتد (مثل استكشاف تسلسلات نصية أطول، أو أحجام أكبر (0.1B+)، أو مجموعات بيانات أكبر. تعتبر أي مشاركة فريدة من نوعها، وستكون جميع المحاولات ذات قيمة ويتم تشجيعها سيتم اكتشافها في الوقت المناسب وتنظيمها في قائمة الشكر مرة أخرى على كل دعمكم.
@ipfgao : سجل خطوات التدريب
@chuanzhubin : ? قم بكتابة التعليقات سطرًا تلو الآخر
@WangRongsheng : المعالجة المسبقة لمجموعات البيانات الكبيرة
@pengqianhan : برنامج تعليمي موجز
@RyanSunn : سجل التعلم لعملية التفكير
تم ترخيص هذا المستودع بموجب ترخيص Apache-2.0.


