gigagan pytorch
0.2.20

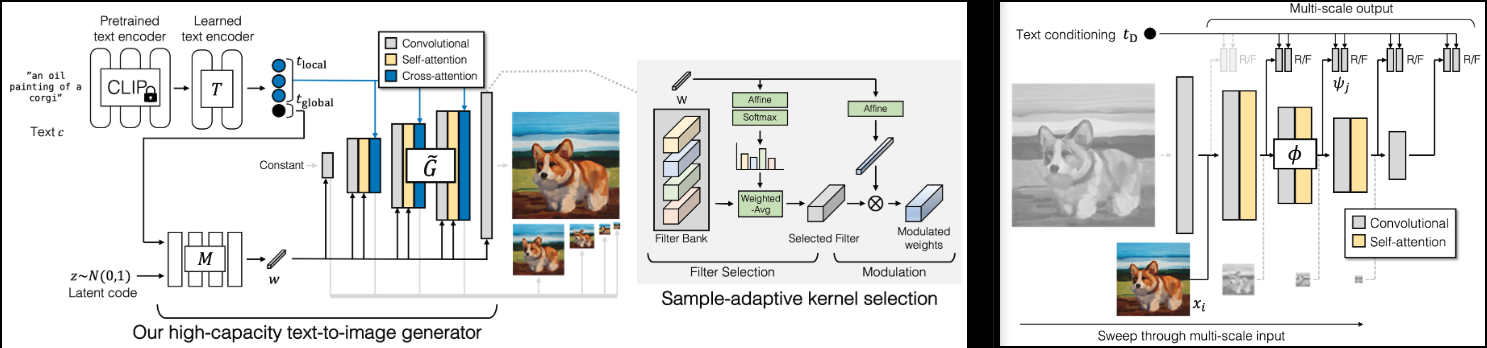
تنفيذ GigaGAN (صفحة المشروع)، SOTA GAN الجديد من Adobe.
سأضيف أيضًا بعض النتائج من غان خفيف الوزن، من أجل تقارب أسرع (إثارة طبقة التخطي) واستقرار أفضل (الخسارة المساعدة لإعادة البناء في المُميِّز)
وسيحتوي أيضًا على الكود الخاص بمضخمات العينات 1k - 4k، والذي أجده أهم ما يميز هذه الورقة.
يرجى الانضمام إذا كنت مهتمًا بالمساعدة في النسخ المتماثل مع مجتمع LAION
الاستقرار AI و؟ أتقدم بالشكر على الرعاية السخية، وكذلك الرعاة الآخرين، لمنحني الاستقلالية في استخدام الذكاء الاصطناعي مفتوح المصدر.
؟ Huggingface لمكتبتهم السريعة
جميع المشرفين في OpenClip، لنماذج الصور النصية والتعلمية المتباينة مفتوحة المصدر الخاصة بـ SOTA
Xavier على مراجعة التعليمات البرمجية المفيدة جدًا، وعلى المناقشات حول كيفية بناء مقياس الثبات في أداة التمييز!
@CerebralSeed للسحب الذي يطلب رمز أخذ العينات الأولي لكل من المولد وجهاز رفع العينات!
كيرث لمراجعة الكود والإشارة إلى بعض التناقضات مع الورقة!
$ pip install gigagan-pytorchGAN بسيطة وغير مشروطة، للمبتدئين
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)من أجل Unet Upsampler غير المشروط
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - المولدMSG - مولد متعدد النطاقاتD – التمييزMSD - التمييز متعدد النطاقاتGP - عقوبة التدرجSSL - إعادة البناء المساعدة في أداة التمييز (من شبكة GAN خفيفة الوزن)VD - التمييز بمساعدة الرؤيةVG - مولد بمساعدة الرؤيةCL - خسارة المولدات التفاضليةMAL - مطابقة الخسارة المدركة سيكون للتشغيل الصحي G و MSG و D و MSD بقيم تتراوح بين 0 إلى 10 ، وعادةً ما يظل ثابتًا إلى حد ما. إذا استمرت هذه القيم في أي وقت بعد ألف خطوة تدريب عند ثلاثة أرقام، فهذا يعني أن هناك خطأ ما. من المقبول أن تنخفض قيم المولد والمميز أحيانًا بشكل سلبي، ولكن يجب أن تتأرجح مرة أخرى إلى النطاق أعلاه.
ينبغي دفع GP و SSL نحو 0 . يمكن أن يرتفع GP في بعض الأحيان. أحب أن أتخيلها على أنها شبكات تمر ببعض عيد الغطاس
فئة GigaGAN مجهزة الآن بـ؟ مسرع. يمكنك بسهولة إجراء تدريب على وحدات معالجة الرسومات المتعددة في خطوتين باستخدام سطر الأوامر accelerate
في الدليل الجذر للمشروع، حيث يوجد البرنامج النصي للتدريب، قم بتشغيله
$ accelerate configثم في نفس الدليل
$ accelerate launch train . py تأكد من أنه يمكن تدريبه دون قيد أو شرط
اقرأ الأوراق ذات الصلة وقم بحذف جميع الخسائر الإضافية الثلاثة
unet upsampler
احصل على مراجعة التعليمات البرمجية للمدخلات والمخرجات متعددة النطاق، حيث كانت الورقة غامضة بعض الشيء
إضافة بنية الشبكة الاختزالية
القيام بعمل غير مشروط لكل من المولد الأساسي ومضخم العينات
جعل التدريب المشروط على النص يعمل لكل من القاعدة والمضخم
جعل عملية إعادة الاستطلاع أكثر كفاءة من خلال تصحيحات أخذ العينات العشوائية
تأكد من أن المولد والمميز يمكنهم أيضًا قبول ترميزات نص CLIP المشفرة مسبقًا
قم بمراجعة الخسائر المساعدة
أضف بعض التعزيزات القابلة للتمييز، وهي تقنية مجربة من أيام GAN القديمة
انقل جميع توقعات التعديل إلى فئة conv2d التكيفية
إضافة تسريع
يجب أن يكون المقطع اختياريًا لجميع الوحدات، وأن تتم إدارته بواسطة GigaGAN ، مع معالجة النص -> تضمينات النص مرة واحدة
إضافة القدرة على تحديد مجموعة فرعية عشوائية من البعد متعدد المقاييس لتحقيق الكفاءة
المنفذ عبر CLI من Lightweight|stylegan2-pytorch
ربط مجموعة بيانات laion للصورة النصية
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

