local attention
1.9.15
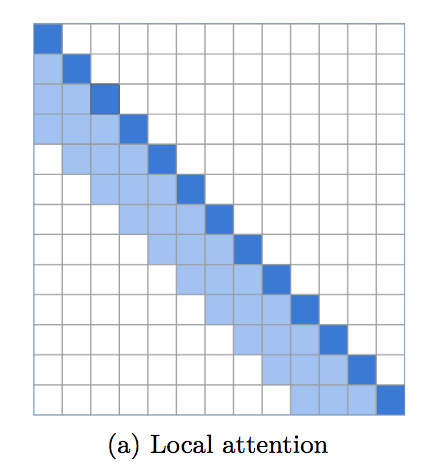
تنفيذ الاهتمام بالنوافذ المحلية، والذي يضع خط أساس قويًا بشكل لا يصدق لنمذجة اللغة. لقد أصبح من الواضح أن المحول يحتاج إلى اهتمام محلي في الطبقات السفلية، مع حجز الطبقات العليا للاهتمام العالمي لدمج نتائج الطبقات السابقة. يجعل هذا المستودع من السهل توظيف انتباه النافذة المحلية على الفور.
لقد تم اختبار هذا الكود بالفعل في مستودعات متعددة، جنبًا إلى جنب مع تطبيقات مختلفة للاهتمام المتناثر طويل المدى.
$ pip install local-attention import torch
from local_attention import LocalAttention
q = torch . randn ( 2 , 8 , 2048 , 64 )
k = torch . randn ( 2 , 8 , 2048 , 64 )
v = torch . randn ( 2 , 8 , 2048 , 64 )
attn = LocalAttention (
dim = 64 , # dimension of each head (you need to pass this in for relative positional encoding)
window_size = 512 , # window size. 512 is optimal, but 256 or 128 yields good enough results
causal = True , # auto-regressive or not
look_backward = 1 , # each window looks at the window before
look_forward = 0 , # for non-auto-regressive case, will default to 1, so each window looks at the window before and after it
dropout = 0.1 , # post-attention dropout
exact_windowsize = False # if this is set to true, in the causal setting, each query will see at maximum the number of keys equal to the window size
)
mask = torch . ones ( 2 , 2048 ). bool ()
out = attn ( q , k , v , mask = mask ) # (2, 8, 2048, 64)تسمح هذه المكتبة أيضًا بالاهتمام المحلي في إعداد مساحة الاستعلام/المفتاح المشتركة (هندسة الإصلاح). سيتم الاهتمام بتطبيع المفاتيح، بالإضافة إلى إخفاء الرموز المميزة لنفسها.
import torch
from local_attention import LocalAttention
qk = torch . randn ( 2 , 8 , 2048 , 64 )
v = torch . randn ( 2 , 8 , 2048 , 64 )
attn = LocalAttention (
dim = 64 ,
window_size = 512 ,
shared_qk = True ,
causal = True
)
mask = torch . ones ( 2 , 2048 ). bool ()
out = attn ( qk , qk , v , mask = mask ) # (2, 8, 2048, 64) إذا كنت ترغب في أن تقوم الوحدة بتضمين استعلامك / مفتاحك / قيمك بالإضافة إلى القناع تلقائيًا، فما عليك سوى تعيين الكلمة الأساسية autopad على True
import torch
from local_attention import LocalAttention
q = torch . randn ( 8 , 2057 , 64 )
k = torch . randn ( 8 , 2057 , 64 )
v = torch . randn ( 8 , 2057 , 64 )
attn = LocalAttention (
window_size = 512 ,
causal = True ,
autopad = True # auto pads both inputs and mask, then truncates output appropriately
)
mask = torch . ones ( 1 , 2057 ). bool ()
out = attn ( q , k , v , mask = mask ) # (8, 2057, 64)محول الاهتمام المحلي الكامل
import torch
from local_attention import LocalTransformer
model = LocalTransformer (
num_tokens = 256 ,
dim = 512 ,
depth = 6 ,
max_seq_len = 8192 ,
causal = True ,
local_attn_window_size = 256
). cuda ()
x = torch . randint ( 0 , 256 , ( 1 , 8192 )). cuda ()
logits = model ( x ) # (1, 8192, 256)حجم النافذة 256، الاسترجاع 1، إجمالي مجال الاستقبال 512
$ python train.py @inproceedings { rae-razavi-2020-transformers ,
title = " Do Transformers Need Deep Long-Range Memory? " ,
author = " Rae, Jack and Razavi, Ali " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics " ,
month = jul,
year = " 2020 " ,
address = " Online " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-main.672 "
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://arxiv.org/pdf/2003.05997.pdf }
} @misc { beltagy2020longformer ,
title = { Longformer: The Long-Document Transformer } ,
author = { Iz Beltagy and Matthew E. Peters and Arman Cohan } ,
year = { 2020 } ,
eprint = { 2004.05150 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @article { Bondarenko2023QuantizableTR ,
title = { Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing } ,
author = { Yelysei Bondarenko and Markus Nagel and Tijmen Blankevoort } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2306.12929 } ,
url = { https://api.semanticscholar.org/CorpusID:259224568 }
}

