byol pytorch
0.8.2
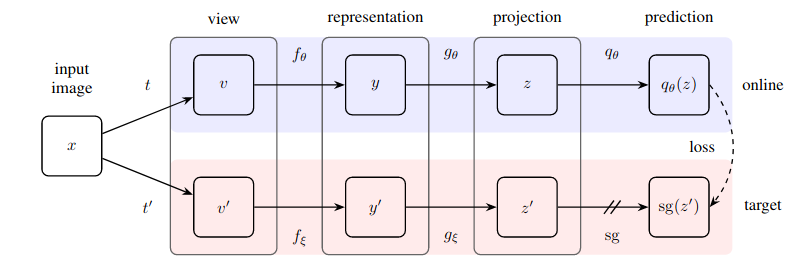
التنفيذ العملي لطريقة بسيطة بشكل مذهل للتعلم الخاضع للإشراف الذاتي والتي تحقق حالة جديدة من التقدم (تتجاوز SimCLR) دون التعلم المتباين والحاجة إلى تعيين أزواج سلبية.
يقدم هذا المستودع وحدة يمكن من خلالها بسهولة تغليف أي شبكة عصبية قائمة على الصور (الشبكة المتبقية، شبكة التمييز، شبكة السياسة) للبدء فورًا في الاستفادة من بيانات الصور غير المُصنفة.
التحديث 1: يوجد الآن دليل جديد على أن تسوية الدُفعات هي المفتاح لجعل هذه التقنية تعمل بشكل جيد
التحديث 2: نجحت ورقة جديدة في استبدال معيار الدُفعة بمعيار المجموعة + توحيد الوزن، مما يدحض الحاجة إلى إحصائيات الدُفعات لكي يعمل BYOL
التحديث 3: أخيرًا، لدينا بعض التحليلات حول سبب نجاح ذلك
شرح يانيك كيلشر الممتاز
اذهب الآن وأنقذ مؤسستك من الاضطرار إلى الدفع مقابل التصنيفات :)
$ pip install byol-pytorchما عليك سوى توصيل شبكتك العصبية، وتحديد (1) أبعاد الصورة بالإضافة إلى (2) اسم (أو فهرس) الطبقة المخفية، والتي يتم استخدام مخرجاتها كتمثيل كامن يستخدم للتدريب الخاضع للإشراف الذاتي.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )هذا إلى حد كبير. وبعد الكثير من التدريب، من المفترض أن تؤدي الشبكة المتبقية الآن أداءً أفضل في مهامها الخاضعة للإشراف.
تشير ورقة بحثية جديدة من Kaiming إلى أن BYOL لا يحتاج حتى إلى برنامج التشفير المستهدف ليكون متوسطًا متحركًا أسيًا لبرنامج التشفير عبر الإنترنت. لقد قررت إنشاء هذا الخيار بحيث يمكنك بسهولة استخدام هذا المتغير للتدريب، وذلك ببساطة عن طريق تعيين علامة use_momentum على False . لن تحتاج بعد الآن إلى استدعاء update_moving_average إذا سلكت هذا المسار كما هو موضح في المثال أدناه.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )على الرغم من أنه تم بالفعل تعيين المعلمات الفائقة على ما وجدته الورقة هو الأمثل، يمكنك تغييرها باستخدام وسيطات كلمات رئيسية إضافية لفئة الغلاف الأساسية.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) افتراضيًا، ستستخدم هذه المكتبة التعزيزات من ورقة SimCLR (والتي تُستخدم أيضًا في ورقة BYOL). ومع ذلك، إذا كنت ترغب في تحديد مسار التعزيز الخاص بك، فيمكنك ببساطة تمرير وظيفة التعزيز المخصصة الخاصة بك باستخدام الكلمة الأساسية augment_fn .
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)في هذه الورقة، يبدو أنهم يؤكدون أن إحدى التعزيزات لها احتمالية ضبابية أعلى من الأخرى. يمكنك أيضًا تعديل هذا بما يرضي قلبك.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) لجلب التضمينات أو الإسقاطات، عليك ببساطة تمرير إشارة return_embeddings = True إلى مثيل المتعلم BYOL
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) يقدم المستودع الآن تدريبًا موزعًا باستخدام ? تسريع معانقة الوجه. كل ما عليك فعله هو تمرير Dataset الخاصة بك إلى BYOLTrainer المستورد
قم أولاً بإعداد التكوين للتدريب الموزع عن طريق استدعاء سطر الأوامر المتسارع
$ accelerate config ثم قم بصياغة نص التدريب الخاص بك كما هو موضح أدناه، على سبيل المثال في ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()ثم استخدم تسريع CLI مرة أخرى لتشغيل البرنامج النصي
$ accelerate launch ./train.pyإذا كانت مهمتك النهائية تتضمن التجزئة، فيرجى الاطلاع على المستودع التالي، والذي يمتد BYOL إلى التعلم على مستوى "البكسل".
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

