atari
1.0.0

ملعب الأبحاث مبني على Atari Gym الخاص بـ OpenAI، وهو مُجهز لتنفيذ خوارزميات التعلم المعزز المختلفة.
يمكنه محاكاة أي من الألعاب التالية:
["أستريكس"، "الكويكبات"، "MsPacman"، "Kaboom"، "BankHeist"، "Kangaroo"، "Skiing"، "FishingDerby"، "Krull"، "Berzerk"، "Tutankham"، "Zaxxon"، " "مغامرة"، "Riverraid"، "حريش"، "مغامرة"، "BeamRider"، "CrazyClimber"، "TimePilot"، "Carnival"، "Tennis"، "Seaquest"، "Bowling"، "SpaceInvaders"، "Freeway"، "YarsRevenge"، "RoadRunner"، "JourneyEscape"، "WizardOfWor". ، "غوفر"، "الاختراق"، "ستار غونر"، "Atlantis"، "DoubleDunk"، "Hero"، "BattleZone"، "Solaris"، "UpNDown"، "Frostbite"، "KungFuMaster"، "Pooyan"، "Pitfall"، "MontezumaRevenge"، "PrivateEye"، "AirRaid" '، 'عميدار'، 'روبوتانك'، 'هجوم الشيطان'، "Defender"، "NameThisGame"، "Phoenix"، "Gravitar"، "ElevatorAction"، "Pong"، "VideoPinball"، "IceHockey"، "Boxing"، "Assault"، "Alien"، "Qbert"، "Enduro" "،"ChopperCommand"،"جيمسبوند"]
تحقق من المقالة المتوسطة المقابلة: أتاري - التعلم المعزز بعمق؟ (الجزء الأول: DDQN)
الهدف النهائي لهذا المشروع هو تنفيذ ومقارنة أساليب RL المختلفة مع ألعاب أتاري كقاسم مشترك.
pip install -r requirements.txt .python atari.py --help . * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
الشبكة العصبية التلافيفية العميقة بواسطة DeepMind
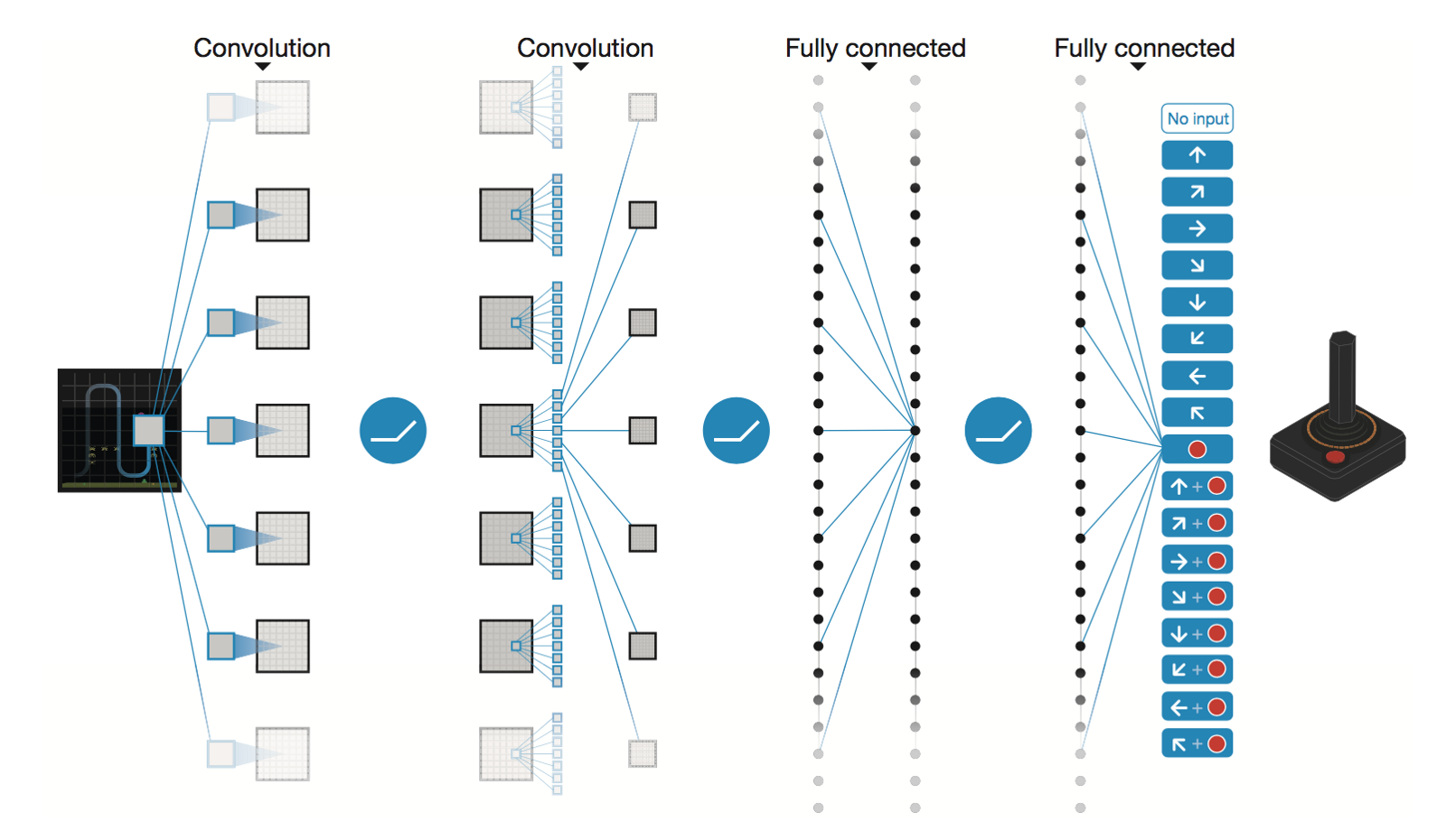
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
بعد 5 ملايين من الخطوات ( حوالي 40 ساعة على وحدة معالجة الرسومات Tesla K80 أو ~ 90 ساعة على وحدة المعالجة المركزية Intel i7 رباعية النواة بسرعة 2.9 جيجاهرتز):
تمرين:
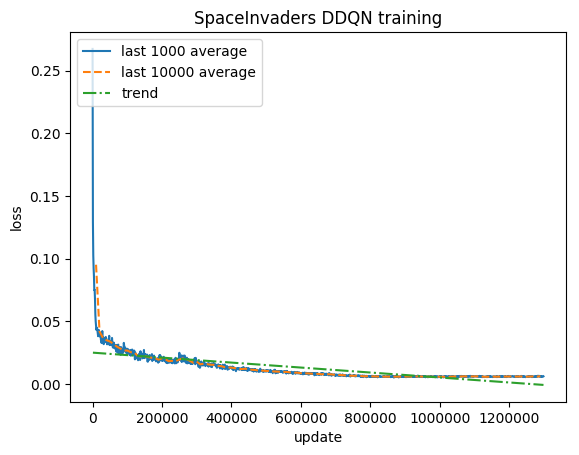
النتيجة الطبيعية - يتم قص كل مكافأة إلى (-1، 1)
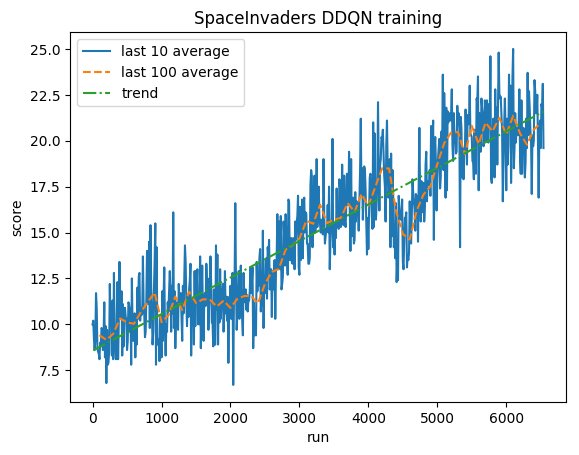
الاختبار:
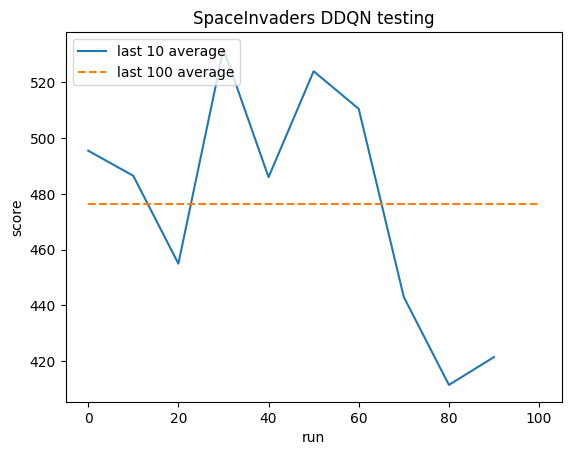
المتوسط البشري: ~372
متوسط DDQN: ~479 (128%)
تمرين:
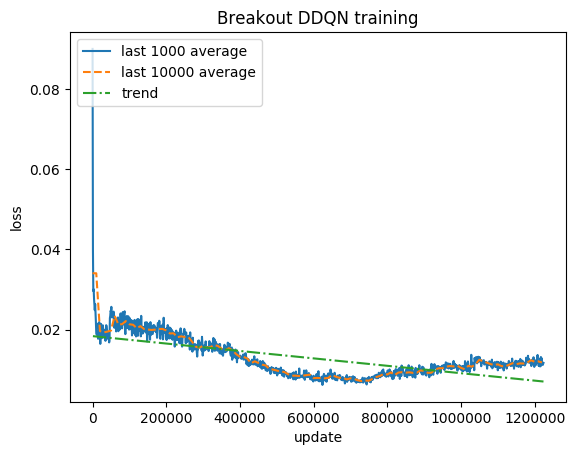
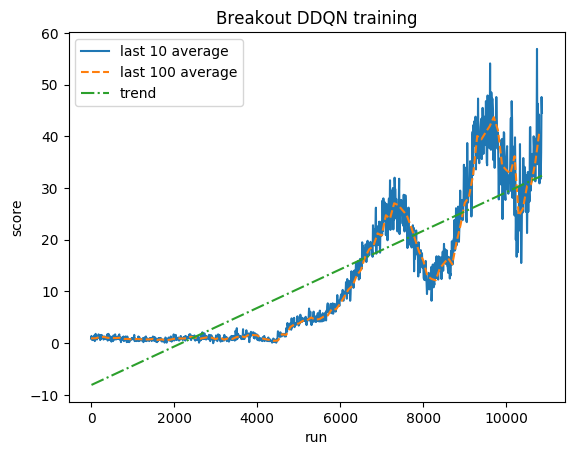
النتيجة الطبيعية - يتم قص كل مكافأة إلى (-1، 1)
الاختبار:
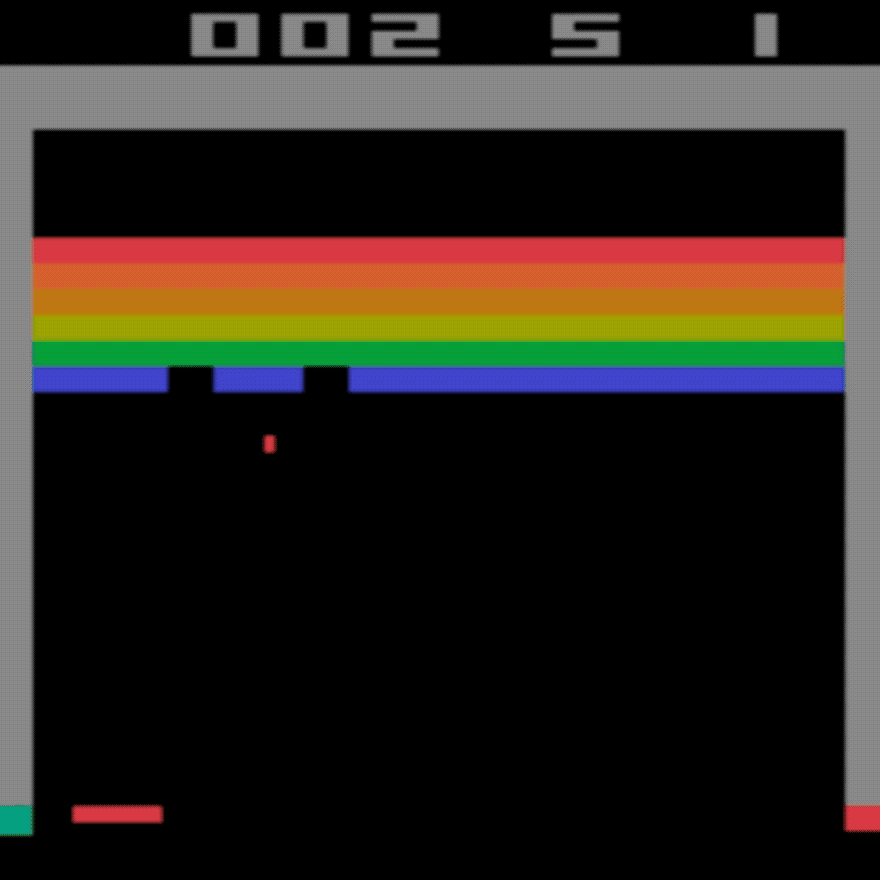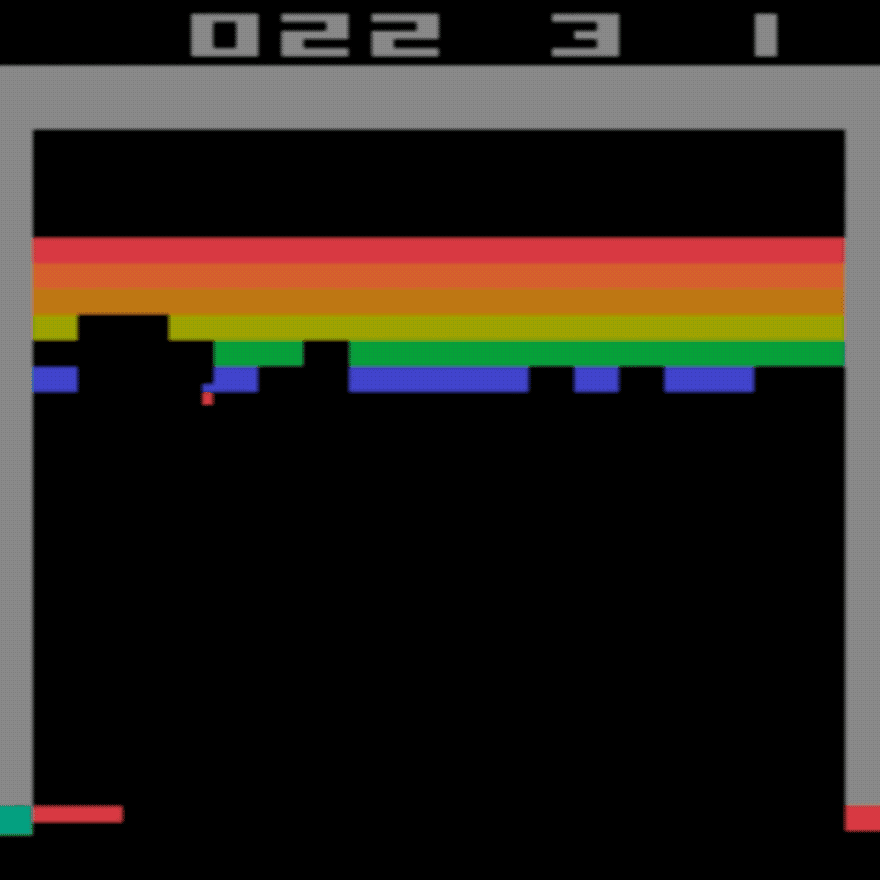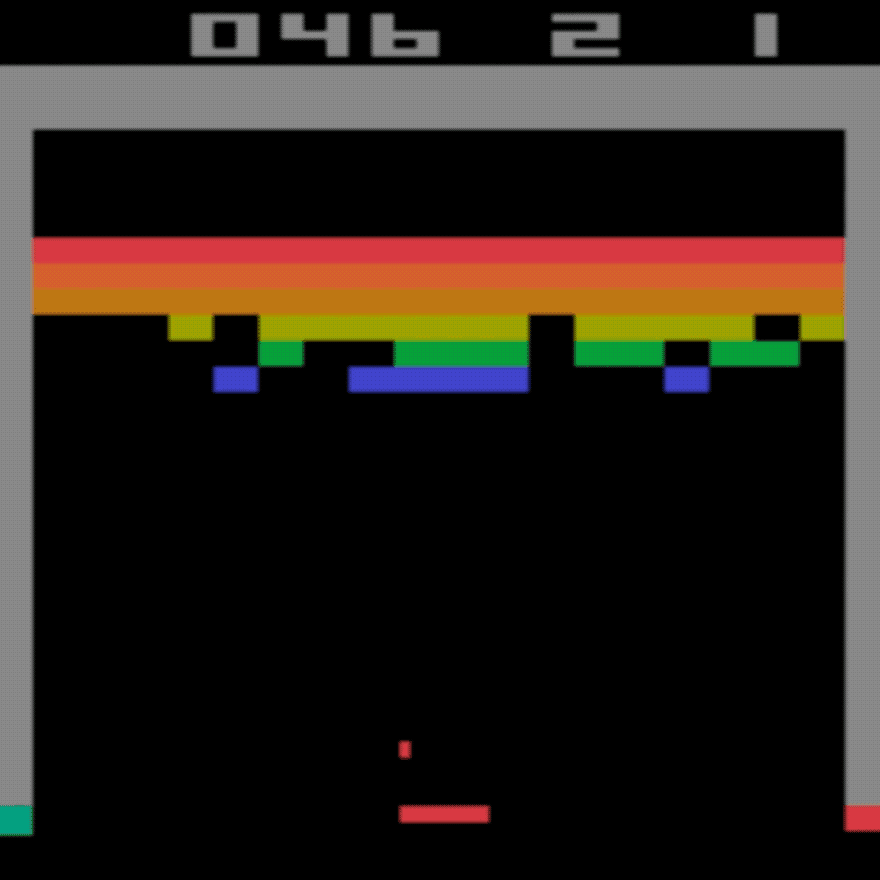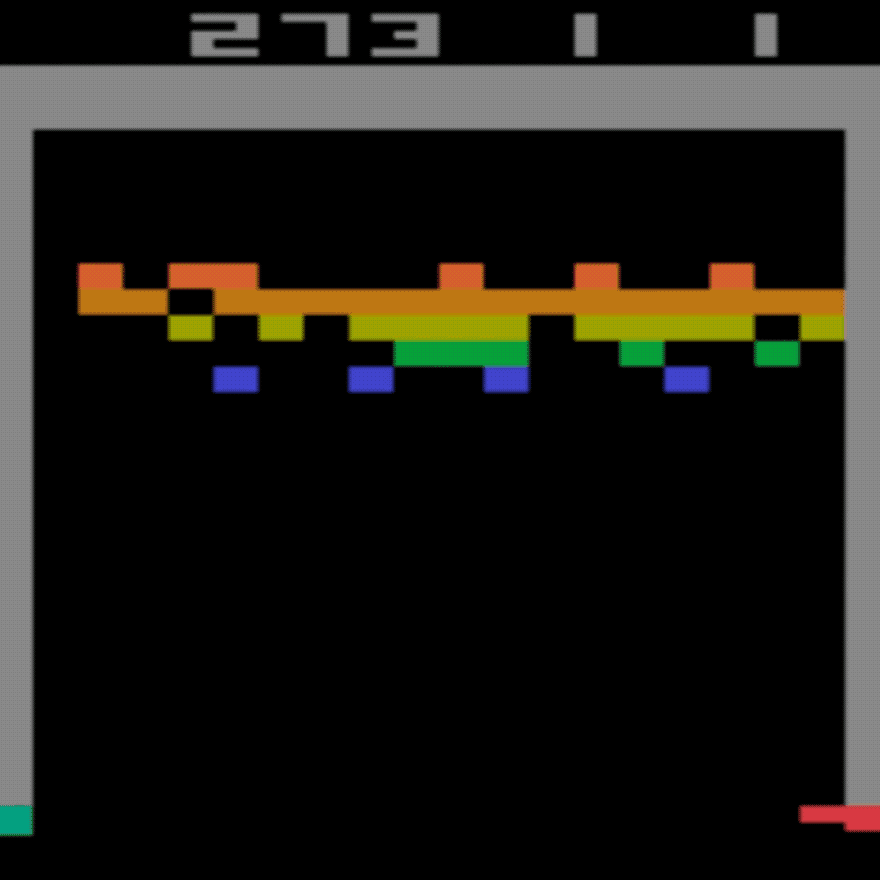
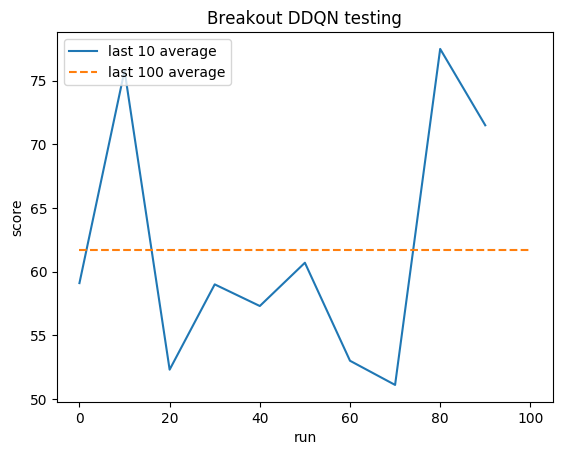
المتوسط البشري: ~28
متوسط DDQN: ~62 (221%)
تمرين:
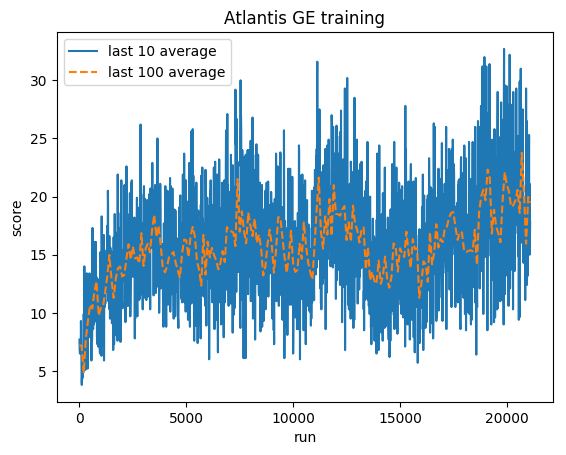
النتيجة الطبيعية - يتم قص كل مكافأة إلى (-1، 1)
الاختبار:

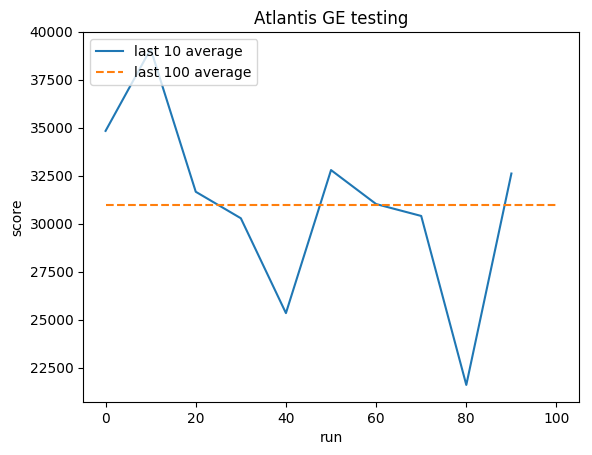
المتوسط البشري: ~29,000
متوسط جنرال إلكتريك: 31000 (106%)
جريج (جرزيجورز) سورما
مَلَفّ
جيثب
مدونة


