sinkhorn transformer
0.11.4
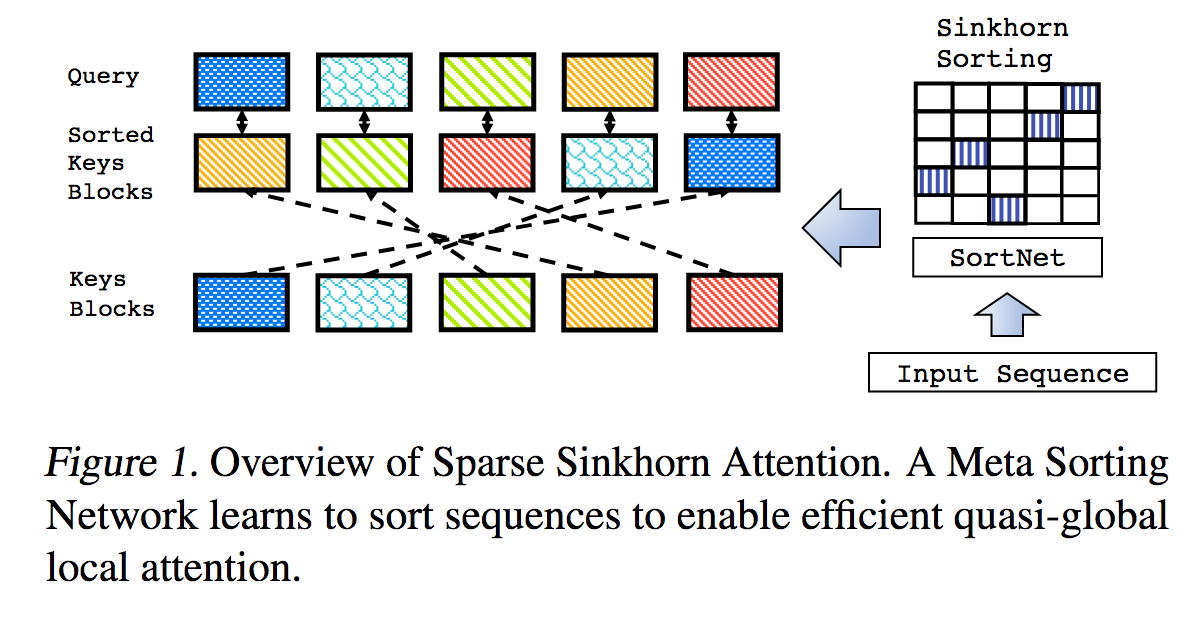
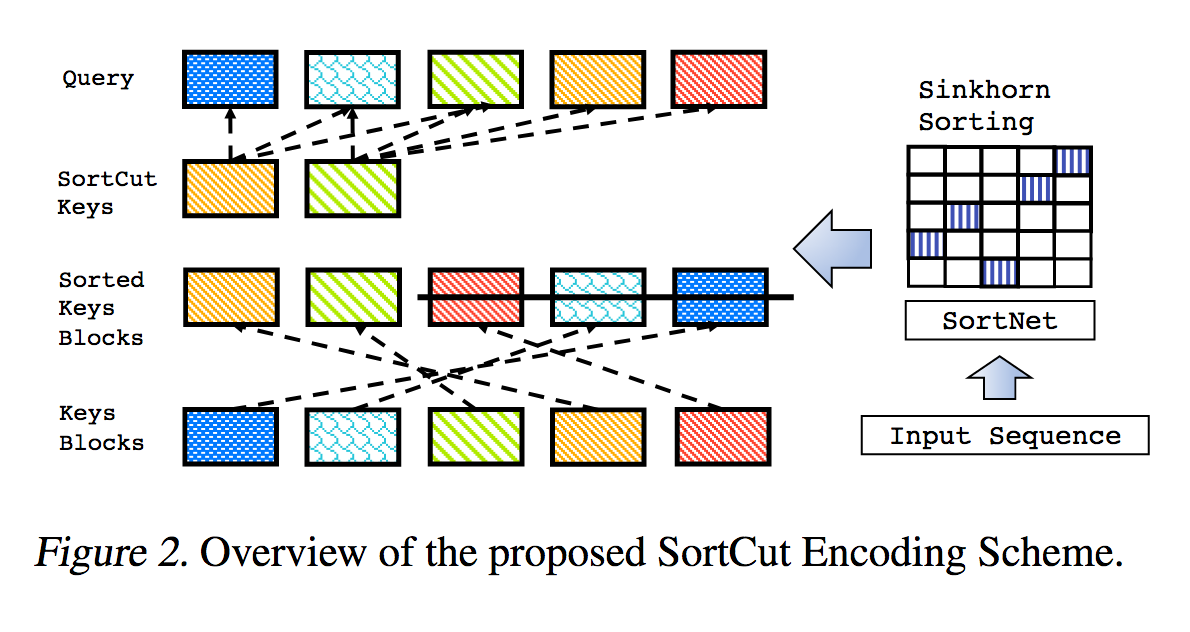
هذه نسخة طبق الأصل من العمل الموضح في Sparse Sinkhorn Attention، مع تحسينات إضافية.
يتضمن شبكة فرز ذات معلمات، باستخدام تطبيع البوق لأخذ عينات من مصفوفة التقليب التي تطابق مجموعات المفاتيح الأكثر صلة بمجموعات الاستعلامات.
يجلب هذا العمل أيضًا شبكات عكسية وتقسيمًا للأمام (المفاهيم المقدمة من Reformer) لتحقيق المزيد من توفير الذاكرة.
204 ألف رمز (لأغراض العرض التوضيحي)
$ pip install sinkhorn_transformerنموذج لغة يعتمد على محولات Sinkhorn
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
bucket_size = 128 , # size of the buckets
causal = False , # auto-regressive or not
n_sortcut = 2 , # use sortcut to reduce memory complexity to linear
n_top_buckets = 2 , # sort specified number of key/value buckets to one query bucket. paper is at 1, defaults to 2
ff_chunks = 10 , # feedforward chunking, from Reformer paper
reversible = True , # make network reversible, from Reformer paper
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post attention dropout
attn_layer_dropout = 0.1 , # post attention layer dropout
layer_dropout = 0.1 , # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True , # tie layer parameters, from Albert paper
emb_dim = 128 , # embedding factorization, from Albert paper
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_glu = True , # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 2 , # replace N heads with local attention, suggested to work well from Routing Transformer paper
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
model ( x ) # (1, 2048, 20000)محول عادي للقرن المغرق، طبقات من الاهتمام بالقرن المغرق
import torch
from sinkhorn_transformer import SinkhornTransformer
model = SinkhornTransformer (
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128
)
x = torch . randn ( 1 , 2048 , 1024 )
model ( x ) # (1, 2048, 1024)التشفير Sinkhorn / محول فك التشفير
import torch
from sinkhorn_transformer import SinkhornTransformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
bucket_size = 128 ,
max_seq_len = DE_SEQ_LEN ,
reversible = True ,
return_embeddings = True
). cuda ()
dec = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
causal = True ,
bucket_size = 128 ,
max_seq_len = EN_SEQ_LEN ,
receives_context = True ,
context_bucket_size = 128 , # context key / values can be bucketed differently
reversible = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). cuda ()
y = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). cuda ()
x_mask = torch . ones_like ( x ). bool (). cuda ()
y_mask = torch . ones_like ( y ). bool (). cuda ()
context = enc ( x , input_mask = x_mask )
dec ( y , context = context , input_mask = y_mask , context_mask = x_mask ) # (1, 4096, 20000) افتراضيًا، سوف يشكو النموذج إذا تم إعطاؤه مدخلات ليست من مضاعفات حجم المجموعة. لتجنب الاضطرار إلى إجراء نفس حسابات الحشو في كل مرة، يمكنك استخدام فئة Autopadder المساعدة. وسوف يعتني بقناع input_mask نيابةً عنك أيضًا، إذا تم توفيره. يتم أيضًا دعم المفتاح/القيم والقناع السياقي.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
from sinkhorn_transformer import Autopadder
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 2048 ,
bucket_size = 128 ,
causal = True
)
model = Autopadder ( model , pad_left = True ) # autopadder will fetch the bucket size and autopad input
x = torch . randint ( 0 , 20000 , ( 1 , 1117 )) # odd sequence length
model ( x ) # (1, 1117, 20000) لقد انحرف هذا المستودع عن الورق وهو الآن يستخدم الاهتمام بدلاً من شبكة الفرز الأصلية + أخذ عينات القرن المغوص. لم أجد فرقًا ملحوظًا في الأداء حتى الآن، ويتيح لي المخطط الجديد تعميم الشبكة على أطوال تسلسلية مرنة. إذا كنت ترغب في تجربة Sinkhorn، فيرجى استخدام الإعدادات التالية، والتي تعمل فقط مع الشبكات غير السببية.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128 ,
max_seq_len = 8192 ,
use_simple_sort_net = True , # turn off attention sort net
sinkhorn_iter = 7 , # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2 , # use sortcut to reduce complexity to linear time
temperature = 0.75 , # gumbel temperature - default is set at reported best in paper
non_permutative = False , # allow buckets of keys to be sorted to queries more than once
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
model ( x ) # (1, 8192, 20000) لمعرفة فوائد استخدام PKM، يجب تعيين معدل التعلم للقيم أعلى من بقية المعلمات. (يوصى به ليكون 1e-2 )
يمكنك اتباع التعليمات الواردة هنا لتعيينها بشكل صحيح https://github.com/lucidrains/product-key-memory#learning-rates
يبدو أن Sinkhorn، عند تدريبه على تسلسلات ذات طول ثابت، يواجه مشكلة في فك تشفير التسلسلات من الصفر، ويرجع ذلك أساسًا إلى حقيقة أن شبكة الفرز تواجه مشكلة في التعميم عندما تكون الدلاء مملوءة جزئيًا برموز الحشو.
ولحسن الحظ، أعتقد أنني وجدت حلاً بسيطًا. أثناء التدريب، بالنسبة للشبكات السببية، قم باقتطاع التسلسلات بشكل عشوائي وإجبار شبكة الفرز على التعميم. لقد قدمت علامة ( randomly_truncate_sequence ) لمثيل AutoregressiveWrapper لتسهيل ذلك.
import torch
from sinkhorn_transformer import SinkhornTransformerLM , AutoregressiveWrapper
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 75 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000)أنا منفتح على الاقتراحات إذا وجد شخص ما حلاً أفضل.
هناك مشكلة محتملة في شبكة الفرز السببي، حيث يعتمد قرار مجموعات المفاتيح/القيمة التي تم فرزها في الماضي إلى المجموعة على الرمز المميز الأول فقط وليس الباقي (بسبب نظام التجميع ومنع تسرب المستقبل إلى ماضي).
لقد حاولت التخفيف من هذه المشكلة عن طريق تدوير نصف الرؤوس إلى اليسار بحجم الجرافة - 1، وبالتالي تعزيز الرمز المميز الأخير ليكون الأول. وهذا أيضًا هو السبب وراء تعيين AutoregressiveWrapper افتراضيًا على المساحة اليسرى أثناء التدريب، للتأكد دائمًا من أن الرمز المميز الأخير في التسلسل له رأي في ما يجب استرداده.
إذا وجد أي شخص حلاً أنظف، فيرجى إبلاغي بهذه المشكلات.
@misc { tay2020sparse ,
title = { Sparse Sinkhorn Attention } ,
author = { Yi Tay and Dara Bahri and Liu Yang and Donald Metzler and Da-Cheng Juan } ,
year = { 2020 } ,
url. = { https://arxiv.org/abs/2002.11296 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
}


