TimeSformer pytorch
0.4.1
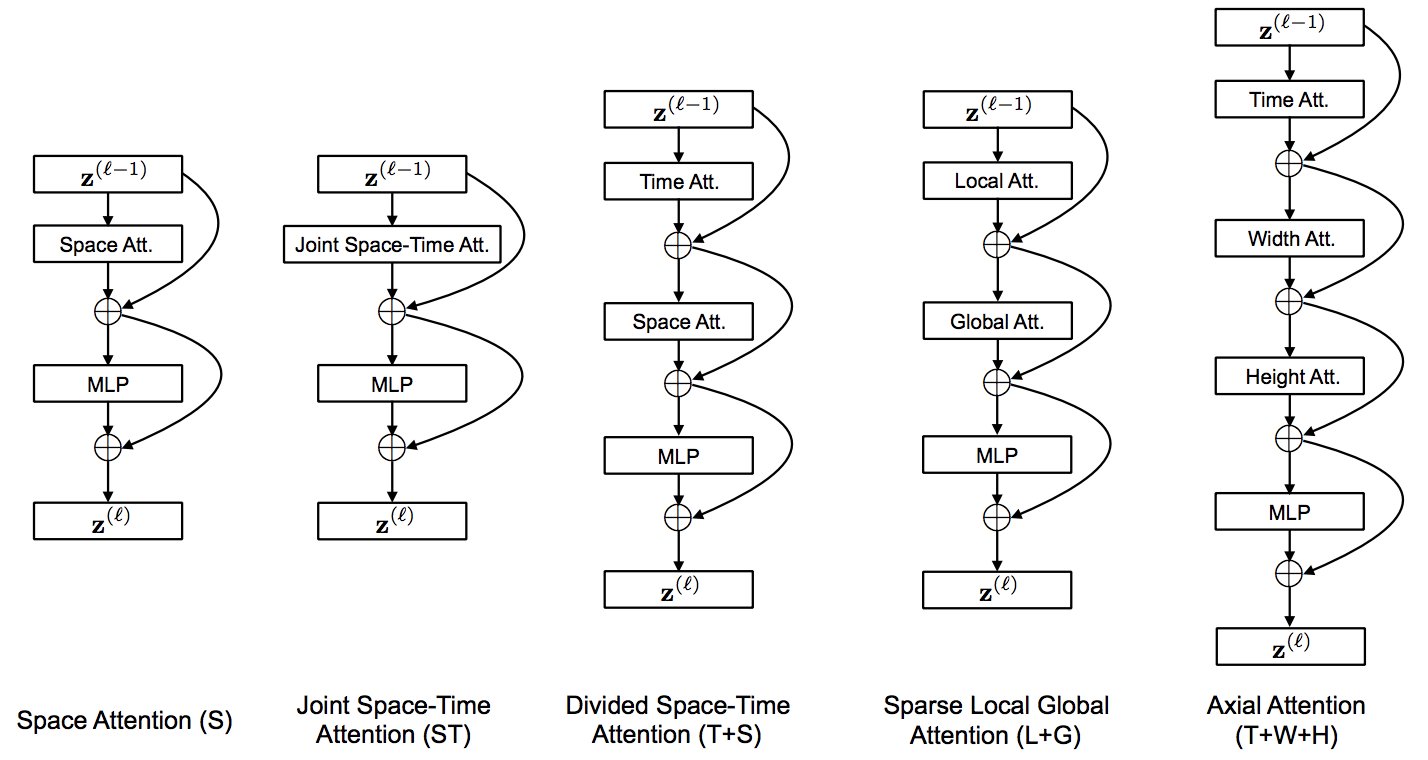
تنفيذ TimeSformer، من Facebook AI. حل خالص وبسيط يعتمد على الاهتمام للوصول إلى SOTA في تصنيف الفيديو. سيحتوي هذا المستودع فقط على البديل الأفضل أداءً، وهو "الانتباه المقسم للمكان والزمان"، والذي لا يعدو كونه مجرد انتباه على طول المحور الزمني قبل المكاني.
بيان صحفي
$ pip install timesformer-pytorch import torch
from timesformer_pytorch import TimeSformer
model = TimeSformer (
dim = 512 ,
image_size = 224 ,
patch_size = 16 ,
num_frames = 8 ,
num_classes = 10 ,
depth = 12 ,
heads = 8 ,
dim_head = 64 ,
attn_dropout = 0.1 ,
ff_dropout = 0.1
)
video = torch . randn ( 2 , 8 , 3 , 224 , 224 ) # (batch x frames x channels x height x width)
mask = torch . ones ( 2 , 8 ). bool () # (batch x frame) - use a mask if there are variable length videos in the same batch
pred = model ( video , mask = mask ) # (2, 10) @misc { bertasius2021spacetime ,
title = { Is Space-Time Attention All You Need for Video Understanding? } ,
author = { Gedas Bertasius and Heng Wang and Lorenzo Torresani } ,
year = { 2021 } ,
eprint = { 2102.05095 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { tokshift2021 ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang, Yanbin Hao, Chong-Wah Ngo } ,
journal = { ACM Multimedia 2021 } ,
}

