LongNet
0.4.8

هذا تطبيق مفتوح المصدر للورقة LongNet: Scaling Transformers to 1,000,000,000 Tokens بواسطة Jiayu Ding، Shuming Ma، Li Dong، Xingxing Zhang، Shaohan Huang، Wenhui Wang، Furu Wei. LongNet عبارة عن متغير محول مصمم لزيادة طول التسلسل إلى أكثر من مليار رمز دون التضحية بالأداء في التسلسلات الأقصر.
pip install longnet بمجرد تثبيت LongNet، يمكنك استخدام فئة DilatedAttention كما يلي:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerنموذج محول جاهز تمامًا لتدريب كتل المحولات المتوسعة مع Feedforwards مع Layernorm وSWIGLU وكتلة محولات متوازية
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
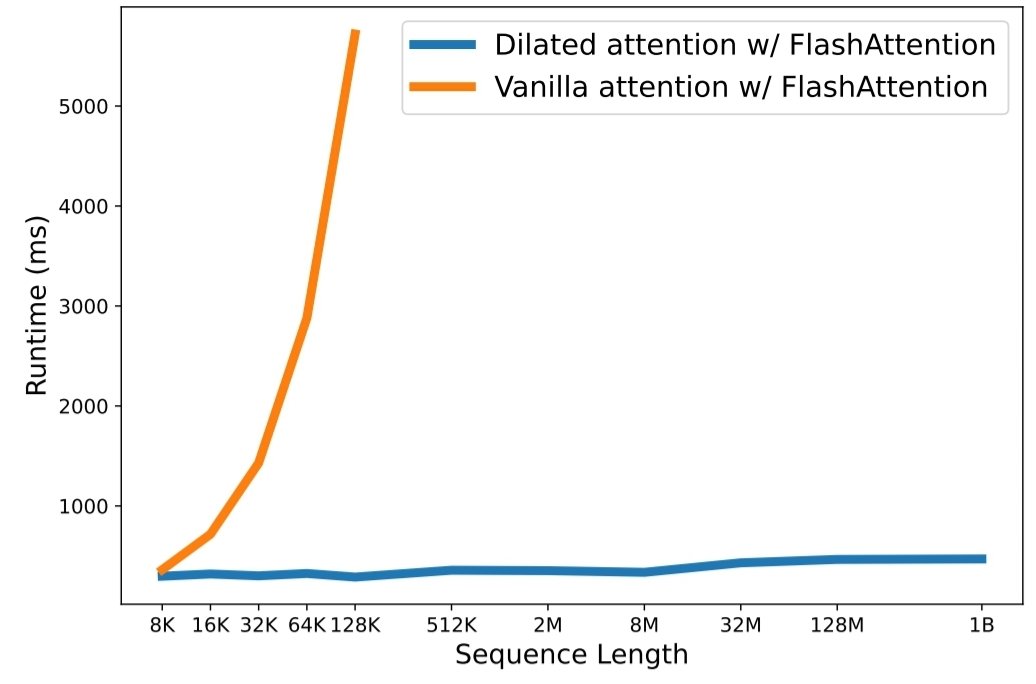
python3 train.py لقد أصبح قياس طول التسلسل بمثابة عنق الزجاجة الحاسم في عصر نماذج اللغات الكبيرة. ومع ذلك، فإن الأساليب الحالية تعاني إما من التعقيد الحسابي أو تعبير النموذج، مما يجعل الحد الأقصى لطول التسلسل مقيدًا. في هذه الورقة، يقدمون LongNet، وهو متغير Transformer يمكنه زيادة طول التسلسل إلى أكثر من مليار رمز، دون التضحية بالأداء في التسلسلات الأقصر. على وجه التحديد، يقترحون الاهتمام المتوسع، الذي يوسع مجال الانتباه بشكل كبير مع نمو المسافة.
تتمتع LongNet بمزايا كبيرة:
توضح نتائج التجربة أن LongNet يحقق أداءً قويًا في كل من نماذج التسلسل الطويل ومهام اللغة العامة. يفتح عملهم إمكانيات جديدة لنمذجة تسلسلات طويلة جدًا، على سبيل المثال، التعامل مع مجموعة كاملة أو حتى الإنترنت بالكامل كتسلسل.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

