antialiased cnns
v0.3
جعل الشبكات التلافيفية متغيرة التحول مرة أخرى
ريتشارد تشانغ. في ICML، 2019.
قم بتشغيل pip install antialiased-cnns
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True ) إذا كان لديك نموذج بالفعل وترغب في تحسين الحواف ومواصلة التدريب، فانسخ أوزانك القديمة فوق:
import torchvision . models as models
old_model = models . resnet50 ( pretrained = True ) # old (aliased) model
antialiased_cnns . copy_params_buffers ( old_model , model ) # copy the weights overإذا كنت تريد تعديل النموذج الخاص بك، فاستخدم طبقة BlurPool. مزيد من المعلومات حول النماذج المقدمة لدينا وكيفية استخدام BlurPool أدناه.
C = 10 # example feature channel size
blurpool = antialiased_cnns . BlurPool ( C , stride = 2 ) # BlurPool layer; use to downsample a feature map
ex_tens = torch . Tensor ( 1 , C , 128 , 128 )
print ( blurpool ( ex_tens ). shape ) # 1xCx64x64 tensorالتحديثات
pip install antialiased-cnns وتحميل النماذج باستخدام العلامة pretrained=True .BlurPoolبيب تثبيت هذه الحزمة
pip install antialiased-cnnsأو قم باستنساخ هذا المستودع وتثبيت المتطلبات (خاصة PyTorch)
https://github.com/adobe/antialiased-cnns.git
cd antialiased-cnns
pip install -r requirements.txtيقوم ما يلي بتحميل نموذج حواف مُدرب مسبقًا، ربما كعمود فقري لتطبيقك.
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True , filter_size = 4 ) نوفر أيضًا أوزانًا لـ AlexNet و VGG16(bn) و Resnet18,34,50,101 و Densenet121 و MobileNetv2 (راجع example_usage.py).
تحتوي وحدة antialiased_cnns على فئة BlurPool ، التي تعمل على التمويه + أخذ العينات الفرعية. قم بتشغيل pip install antialiased-cnns أو انسخ الدليل الفرعي antialiased_cnns .
المنهجية المنهجية بسيطة - قم أولاً بالتقييم باستخدام الخطوة 1، ثم استخدم طبقة BlurPool الخاصة بنا لإجراء الاختزال المتعرج. قم بإجراء التغييرات المعمارية التالية.
import antialiased_cnns
# MaxPool --> MaxBlurPool
baseline = nn . MaxPool2d ( kernel_size = 2 , stride = 2 )
antialiased = [ nn . MaxPool2d ( kernel_size = 2 , stride = 1 ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# Conv --> ConvBlurPool
baseline = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 2 , padding = 1 ),
nn . ReLU ( inplace = True )]
antialiased = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 1 , padding = 1 ),
nn . ReLU ( inplace = True ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# AvgPool --> BlurPool
baseline = nn . AvgPool2d ( kernel_size = 2 , stride = 2 )
antialiased = antialiased_cnns . BlurPool ( C , stride = 2 ) نحن نفترض أن الموتر الوارد لديه قنوات C يؤدي حساب الطبقة عند الخطوة 1 بدلاً من الخطوة 2 إلى إضافة الذاكرة ووقت التشغيل. على هذا النحو، فإننا عادةً ما نتخطى الحواف بأعلى دقة (في وقت مبكر من الشبكة)، لمنع الزيادات الكبيرة.
إضافة الحواف ثم مواصلة التدريب إذا قمت بالفعل بتدريب نموذج، ثم قمت بإضافة الحواف، فيمكنك الضبط الدقيق من هذا النموذج القديم:
antialiased_cnns . copy_params_buffers ( old_model , antialiased_model )إذا لم ينجح هذا، يمكنك فقط نسخ المعلمات (وليس المخازن المؤقتة). لا تؤدي إضافة الحواف إلى إضافة أي معلمات، لذا فإن قوائم المعلمات متطابقة. (إنها تضيف مخازن مؤقتة، لذلك يتم استخدام بعض الأساليب الإرشادية لمطابقة المخازن المؤقتة، مما قد يؤدي إلى حدوث خطأ.)
antialiased_cnns . copy_params ( old_model , antialiased_model )نلاحظ تحسينات في كل من الدقة (عدد المرات التي يتم فيها تصنيف الصورة بشكل صحيح) والاتساق (عدد المرات التي يتم فيها تصنيف نوبتين لنفس الصورة بنفس الطريقة).
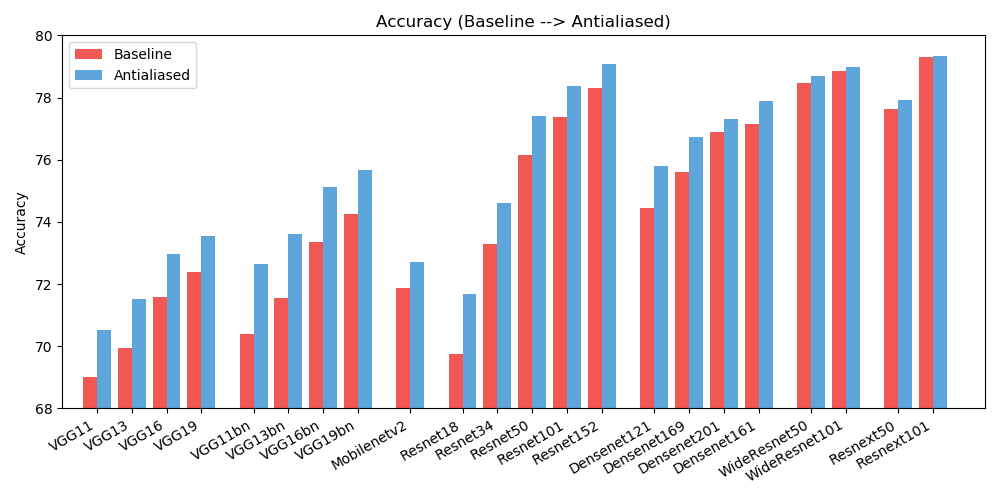
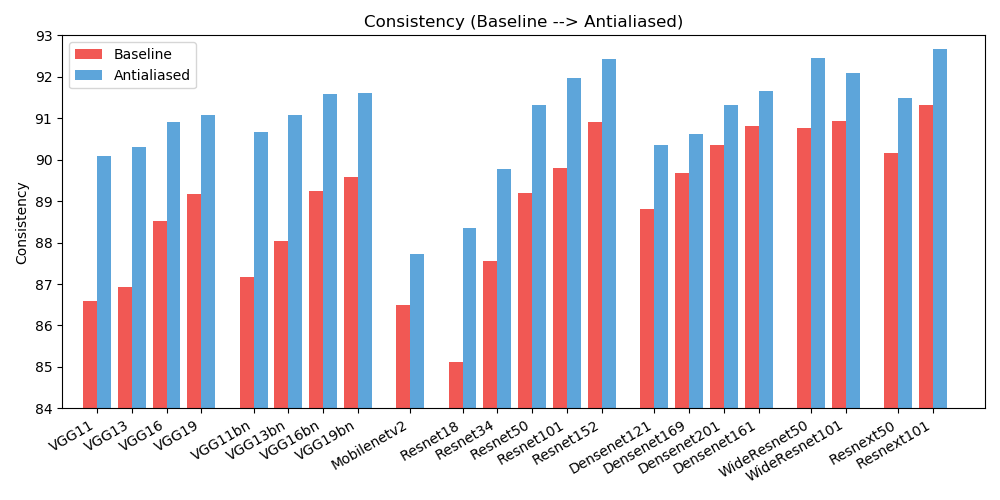
| دقة | خط الأساس | الحواف | دلتا |
|---|---|---|---|
| alexnet | 56.55 | 56.94 | +0.39 |
| vgg11 | 69.02 | 70.51 | +1.49 |
| vgg13 | 69.93 | 71.52 | +1.59 |
| vgg16 | 71.59 | 72.96 | +1.37 |
| vgg19 | 72.38 | 73.54 | +1.16 |
| vgg11_bn | 70.38 | 72.63 | +2.25 |
| vgg13_bn | 71.55 | 73.61 | +2.06 |
| vgg16_bn | 73.36 | 75.13 | +1.77 |
| vgg19_bn | 74.24 | 75.68 | +1.44 |
| ريسنيت18 | 69.74 | 71.67 | +1.93 |
| ريسنيت34 | 73.30 | 74.60 | +1.30 |
| ريسنيت50 | 76.16 | 77.41 | +1.25 |
| resnet101 | 77.37 | 78.38 | +1.01 |
| ريسنيت152 | 78.31 | 79.07 | +0.76 |
| resnext50_32x4d | 77.62 | 77.93 | +0.31 |
| resnext101_32x8d | 79.31 | 79.33 | +0.02 |
| Wide_resnet50_2 | 78.47 | 78.70 | +0.23 |
| Wide_resnet101_2 | 78.85 | 78.99 | +0.14 |
| كثيفة121 | 74.43 | 75.79 | +1.36 |
| كثيفة169 | 75.60 | 76.73 | +1.13 |
| كثيفة201 | 76.90 | 77.31 | +0.41 |
| كثيفة161 | 77.14 | 77.88 | +0.74 |
| mobilenet_v2 | 71.88 | 72.72 | +0.84 |
| تناسق | خط الأساس | الحواف | دلتا |
|---|---|---|---|
| alexnet | 78.18 | 83.31 | +5.13 |
| vgg11 | 86.58 | 90.09 | +3.51 |
| vgg13 | 86.92 | 90.31 | +3.39 |
| vgg16 | 88.52 | 90.91 | +2.39 |
| vgg19 | 89.17 | 91.08 | +1.91 |
| vgg11_bn | 87.16 | 90.67 | +3.51 |
| vgg13_bn | 88.03 | 91.09 | +3.06 |
| vgg16_bn | 89.24 | 91.58 | +2.34 |
| vgg19_bn | 89.59 | 91.60 | +2.01 |
| ريسنيت18 | 85.11 | 88.36 | +3.25 |
| ريسنيت34 | 87.56 | 89.77 | +2.21 |
| resnet50 | 89.20 | 91.32 | +2.12 |
| resnet101 | 89.81 | 91.97 | +2.16 |
| ريسنيت152 | 90.92 | 92.42 | +1.50 |
| resnext50_32x4d | 90.17 | 91.48 | +1.31 |
| resnext101_32x8d | 91.33 | 92.67 | +1.34 |
| Wide_resnet50_2 | 90.77 | 92.46 | +1.69 |
| Wide_resnet101_2 | 90.93 | 92.10 | +1.17 |
| كثيفة121 | 88.81 | 90.35 | +1.54 |
| كثيفة169 | 89.68 | 90.61 | +0.93 |
| كثيفة201 | 90.36 | 91.32 | +0.96 |
| كثيفة161 | 90.82 | 91.66 | +0.84 |
| mobilenet_v2 | 86.50 | 87.73 | +1.23 |
لتقليل الفوضى، توجد هنا نتائج موسعة (أحجام مرشحات مختلفة). ساعد في تحسين النتائج!
تم ترخيص هذا العمل بموجب ترخيص Creative Commons Attribution-NonCommercial-ShareAlike 4.0 الدولي.
جميع المواد متاحة بموجب ترخيص Creative Commons BY-NC-SA 4.0 من شركة Adobe Inc. ويمكنك استخدام المواد وإعادة توزيعها وتكييفها لأغراض غير تجارية ، طالما أنك تمنح الاعتماد المناسب من خلال الاستشهاد بأبحاثنا والإشارة إلى أي تغييرات التي قمت بها.
يبني المستودع مستودع أمثلة PyTorch ومستودع نماذج torchvision. هذه مرخصة على طراز BSD.
إذا وجدت هذا مفيدًا لبحثك، فيرجى التفكير في الاستشهاد بهذا البيبتكس. يرجى الاتصال بـ Richard Zhang <rizhang at adobe dot com> بخصوص أية تعليقات أو تعليقات.


