rotary embedding torch
0.8.6
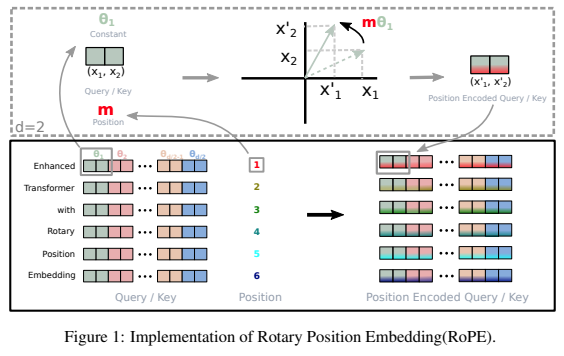
مكتبة مستقلة لإضافة التضمينات الدوارة إلى المحولات في Pytorch، بعد نجاحها كتشفير موضعي نسبي. على وجه التحديد، سيجعل تدوير المعلومات في أي محور للموتر أمرًا سهلاً وفعالاً، سواء كانت موضعية ثابتة أو مكتسبة. ستمنحك هذه المكتبة أحدث النتائج للتضمين الموضعي، بتكاليف قليلة.
يخبرني حدسي أيضًا أن هناك شيئًا أكثر في التدوير يمكن استغلاله في الشبكات العصبية الاصطناعية.
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usualإذا قمت بجميع الخطوات المذكورة أعلاه بشكل صحيح، فيجب أن ترى تحسنًا كبيرًا أثناء التدريب
عند التعامل مع ذاكرات التخزين المؤقت للمفتاح/القيمة عند الاستدلال، يجب إزاحة موضع الاستعلام باستخدام key_value_seq_length - query_seq_length
لتسهيل ذلك، استخدم طريقة rotate_queries_with_cached_keys
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )يمكنك أيضًا القيام بذلك يدويًا بهذه الطريقة
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])لسهولة استخدام التضمين الموضعي النسبي المحوري n الأبعاد، على سبيل المثال. محولات الفيديو
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k ) في هذه الورقة، تمكنوا من إصلاح مشكلة استقراء الطول مع التضمينات الدوارة من خلال إعطائها انحلالًا مشابهًا لـ ALiBi. لقد أطلقوا على هذه التقنية اسم XPos، ويمكنك استخدامها عن طريق تعيين use_xpos = True عند التهيئة.
لا يمكن استخدام هذا إلا لمحولات الانحدار الذاتي
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )تقترح ورقة MetaAI هذه ببساطة الضبط الدقيق على الاستيفاءات الخاصة بمواضع التسلسل للتمديد إلى طول سياق أطول للنماذج المدربة مسبقًا. لقد أظهروا أن هذا يؤدي بشكل أفضل بكثير من مجرد الضبط الدقيق على نفس مواضع التسلسل ولكن تم تمديده بشكل أكبر.
يمكنك استخدام هذا عن طريق تعيين interpolate_factor عند التهيئة إلى قيمة أكبر من 1. (على سبيل المثال، إذا تم تدريب النموذج المُدرب مسبقًا على 2048، فإن تعيين interpolate_factor = 2. سيسمح بالضبط الدقيق على 2048 x 2. = 4096 )
تحديث: أبلغ أحد الأشخاص في المجتمع أن الأمر لا يعمل بشكل جيد. يرجى مراسلتي عبر البريد الإلكتروني إذا رأيت نتيجة إيجابية أو سلبية
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

