q transformer
0.3.0
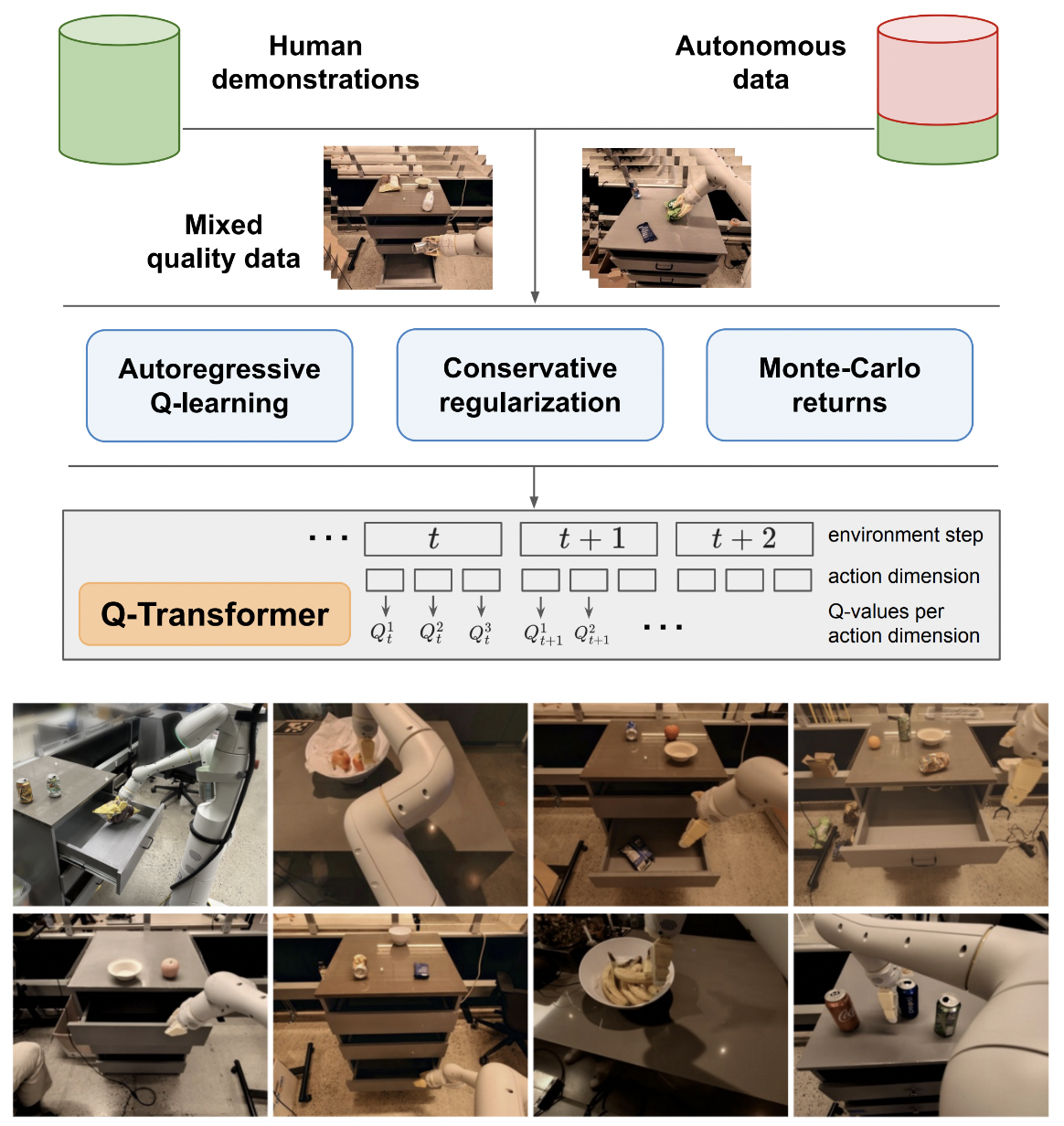
تنفيذ Q-Transformer، والتعلم المعزز القابل للتطوير دون الاتصال بالإنترنت عبر وظائف Q-Regressive، من Google Deepmind
سأظل ملتزمًا بمنطق التعلم Q على إجراء واحد فقط من أجل المقارنة النهائية مع التعلم Q الانحداري المقترح على إجراءات متعددة. أيضا لتكون بمثابة التعليم لنفسي وللجمهور.
تم إعادة إنتاج صيغة التعلم Q ذات الانحدار الذاتي بواسطة Kotb et al.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )طريقة العمل الأولى نحو دعم العمل الفردي
عرض متغير أقل من maxvit، كما هو الحال في نموذج الطقس SOTA metnet3
إضافة بنية مبارزة عميقة اختيارية
إضافة n-خطوة Q التعلم
بناء التنظيم المحافظ
بناء الاقتراح الرئيسي في الورق (الإجراءات المنفصلة ذات الانحدار التلقائي حتى الإجراء الأخير، يتم منح المكافأة فقط في الإجراء الأخير)
ارتجال متغير رأس وحدة فك التشفير، بدلاً من تسلسل الإجراءات السابقة في مرحلة الإطارات + الرموز المميزة المستفادة. وبعبارة أخرى، استخدم التشفير الكلاسيكي - وحدة فك التشفير
إعادة maxvit مع التضمينات الدوارة المحورية + البوابات السيني لعدم الاهتمام بأي شيء. تمكين انتباه الفلاش لـ maxvit مع هذا التغيير
أنشئ فئة منشئ مجموعة بيانات بسيطة، مع مراعاة البيئة والنموذج وإرجاع مجلد يمكن قبوله بواسطة ReplayDataset
ReplayDataset الذي يأخذ في المجلد التعامل مع تعليمات متعددة بشكل صحيح
اعرض مثالاً بسيطًا وشاملاً، بنفس أسلوب جميع اتفاقيات إعادة الشراء الأخرى
لا تتعامل مع أي تعليمات، استخدم المكيف الفارغ في مكتبة CFG
ذاكرة التخزين المؤقت كيلو فولت لفك تشفير العمل
للاستكشاف، اسمح بترتيب مجموعة فرعية من الإجراءات بشكل عشوائي، وليس كل الإجراءات في وقت واحد
استشر بعض خبراء RL واكتشف ما إذا كان هناك أي تقدم جديد في حل التحيز الوهمي
معرفة ما إذا كان يمكن للمرء أن يتدرب باستخدام أوامر عشوائية من الإجراءات - يمكن إرسال الأمر كشرط يتم تجميعه أو تجميعه قبل طبقات الانتباه
وظيفة بحث شعاع بسيطة لاتخاذ الإجراءات المثلى
ارتجال الانتباه المتبادل إلى الإجراءات السابقة وحالات الخطوات الزمنية، أزياء Transformer-XL (مع تسرب الذاكرة المنظمة)
معرفة ما إذا كانت الفكرة الرئيسية في هذه الورقة تنطبق على نماذج اللغة هنا
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

