perfusion pytorch
0.1.23
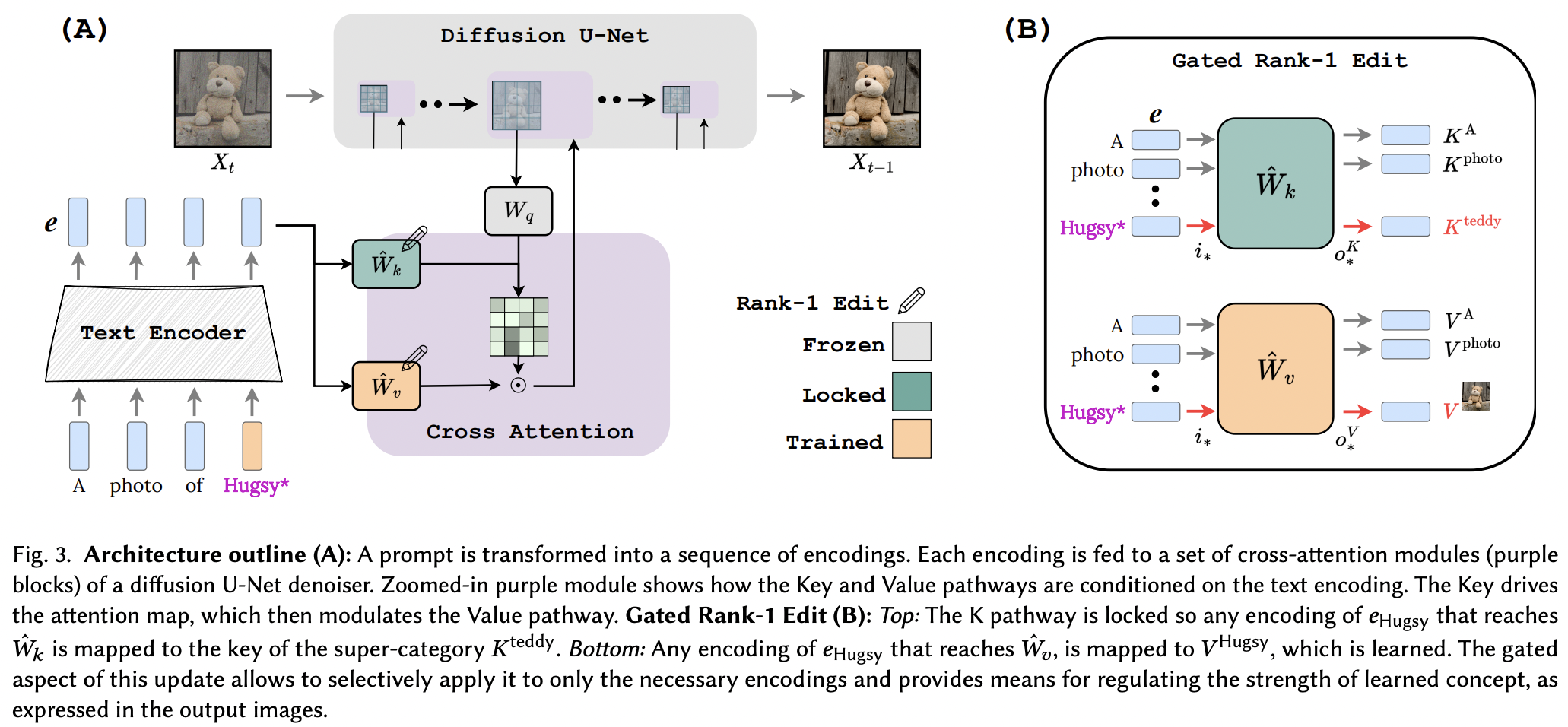
تنفيذ تحرير الرتبة الأولى بمفتاح مقفل. صفحة المشروع
إن نقطة البيع في هذه الورقة هي المعلمات الإضافية المنخفضة للغاية لكل مفهوم مضاف، وصولاً إلى 100 كيلو بايت.
يبدو أنهم نجحوا في تطبيق تقنية التحرير Rank-1 من ورقة تحرير الذاكرة لـ LLM، مع بعض التحسينات. لقد حددوا أيضًا أن المفاتيح تحدد "أين" المفهوم الجديد، بينما تحدد القيم "ماذا"، وتقترح قفل المفتاح المحلي/العالمي لمفهوم الطبقة الفائقة (أثناء تعلم القيم).
بالنسبة للباحثين هناك، إذا تم التحقق من هذه الورقة، فإن الأدوات الموجودة في هذا المستودع يجب أن تعمل مع أي شبكة أخرى لتحويل النص إلى <insert modality> باستخدام تكييف الانتباه المتقاطع. مجرد فكرة
StabilityAI على الرعاية السخية، وكذلك الرعاة الآخرين هناك
Yoad Tewel لمراجعة الأكواد المتعددة وتوضيح رسائل البريد الإلكتروني
براد فيدلر للحساب المسبق لمصفوفة التغاير لـ CLIP المستخدمة في Stable Diffusion 1.5!
جميع المشرفين في OpenClip، لنماذج الصور النصية والتعلمية المتباينة مفتوحة المصدر الخاصة بـ SOTA
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) يحتوي المستودع أيضًا على EmbeddingWrapper الذي يجعل من السهل التدريب على مفهوم جديد (والاستدلال النهائي بمفاهيم متعددة)
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask إذا كان بإمكانك تحديد مثيل CLIP داخل مثيل الانتشار المستقر، فيمكنك أيضًا تمريره مباشرة إلى OpenClipEmbedWrapper للحصول على كل ما تحتاجه للمضي قدمًا لطبقات الانتباه المتقاطع
السابق.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) قم بتوصيل SD 1.5، بدءًا من xiao's Dreambooth-sd
إظهار المثال في الملف التمهيدي للاستدلال بمفاهيم متعددة
يستنتج تلقائيًا مكان إسقاط المفاتيح والقيم إذا لم يتم تحديده لوظيفة make_key_value_proj_rank1_edit_modules_
يجب أن يعتني غلاف التضمين بالاستبدال بمعرف الرمز المميز للفئة الفائقة وإرجاع التضمين بالفئة الفائقة
مراجعة مفاهيم متعددة - بفضل Yoad
تقدم وظيفة تجذب الانتباه المتقاطع
التعامل مع مفاهيم متعددة في موجه واحد للاستدلال - جمع المصطلح السيني + المخرجات
تقدم طريقة لدمج المفاهيم التي تم تعلمها بشكل منفصل من Rank1EditModule المتعددة في واحدة للاستدلال
Rank1EditModule s أضف إخفاء المفهوم المقترح في الورق
اعتني بالوظيفة التي تستوعب مجموعة البيانات وبرنامج تشفير النص وتحسب مسبقًا مصفوفة التباين اللازمة لتحديث المرتبة الأولى
بدلاً من أن يقلق الباحث بشأن معدلات التعلم المختلفة، قدم خدعة التدرج الجزئي من ورقة بحثية أخرى (لتعلم مفهوم تضمين المفهوم)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

