audiolm pytorch
2.2.3
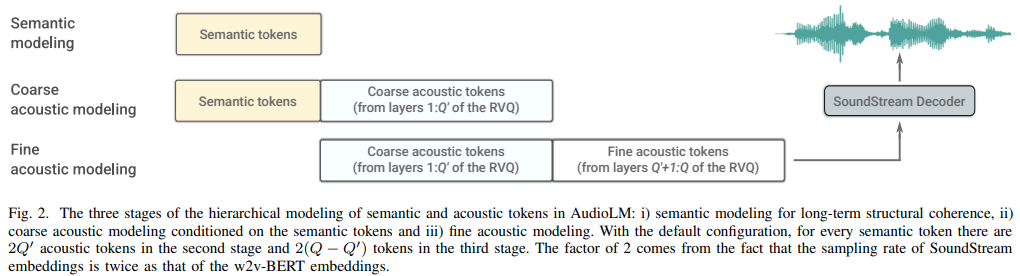
تنفيذ AudioLM، وهو نهج لنمذجة اللغة لتوليد الصوت من خلال أبحاث Google، في Pytorch
كما أنه يمتد العمل للتكييف مع التوجيه المجاني للمصنف مع T5. يسمح هذا للشخص بإجراء تحويل النص إلى صوت أو تحويل النص إلى كلام (TTS)، وهو أمر غير متوفر في الورقة. نعم، هذا يعني أنه يمكن تدريب VALL-E من هذا المستودع. هو في الأساس نفس الشيء.
يرجى الانضمام إذا كنت مهتمًا بتكرار هذا العمل في العلن
يحتوي هذا المستودع الآن أيضًا على إصدار مرخص من معهد ماساتشوستس للتكنولوجيا SoundStream. وهو متوافق أيضًا مع EnCodec، المرخص أيضًا من معهد ماساتشوستس للتكنولوجيا (MIT) في وقت كتابة هذا التقرير.
التحديث: تم استخدام AudioLM بشكل أساسي "لحل" عملية إنشاء الموسيقى في MusicLM الجديد
في المستقبل، لن يكون لمقطع الفيلم هذا أي معنى. يمكنك فقط مطالبة الذكاء الاصطناعي بدلاً من ذلك.
Stability.ai للرعاية السخية للعمل وأبحاث الذكاء الاصطناعي المتطورة مفتوحة المصدر
؟ Huggingface لمكتباتهم المذهلة للتسريع والمحولات
MetaAI لـ Fairseq والرخصة الليبرالية
@eonglints وجوزيف لتقديم نصائحهم وخبراتهم المهنية بالإضافة إلى طلبات السحب!
@djqualia و@yigityu و@inspirit و@BlackFox1197 للمساعدة في تصحيح أخطاء البث الصوتي
برمجة Allen وLW لمراجعة الكود وإرسال إصلاحات الأخطاء!
إيليا لإيجاد مشكلة في الاختزال التمييزي متعدد النطاق ولتحسينات مدرب الصوت
أندريه على تحديد الخسارة المفقودة في تدفق الصوت وتوجيهي خلال المعلمات الفائقة للطيف الطيفي المناسب
أليخاندرو وإيليا لمشاركة نتائجهما مع البث الصوتي للتدريب، ولعملهما على حل بعض المشكلات المتعلقة بالتضمين الموضعي للانتباه المحلي
برمجة LW لإضافة توافق التشفير!
برمجة LW للعثور على مشكلة في التعامل مع رمز EOS المميز عند أخذ العينات من FineTransformer !
@YoungloLee لتحديد الخلل الكبير في الالتواء السببي أحادي الأبعاد للتدفق الصوتي المتعلق بالحشو وليس حساب الخطوات!
هايدن للإشارة إلى بعض التناقضات في أداة التمييز متعددة النطاقات لـ Soundstream
$ pip install audiolm-pytorchهناك خياران لبرنامج الترميز العصبي. إذا كنت تريد استخدام برنامج الترميز 24 كيلو هرتز المُدرب مسبقًا، فما عليك سوى إنشاء كائن التشفير كما يلي:
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. بخلاف ذلك، للبقاء أكثر التزامًا بالورقة الأصلية، يمكنك استخدام SoundStream . أولاً، يحتاج SoundStream إلى التدريب على مجموعة كبيرة من البيانات الصوتية
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel يمكن بعد ذلك استخدام SoundStream المُدرَّب الخاص بك كأداة رمزية عامة للصوت
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) يمكنك أيضًا استخدام مسارات الصوت الخاصة بـ AudioLM و MusicLM عن طريق استيراد AudioLMSoundStream و MusicLMSoundStream على التوالي.
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above اعتبارًا من الإصدار 0.17.0 ، يمكنك الآن استدعاء أسلوب الفئة على SoundStream للتحميل من ملفات نقاط التفتيش، دون الحاجة إلى تذكر التكوينات الخاصة بك.
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) لاستخدام تتبع الأوزان والتحيزات، قم أولاً بتعيين use_wandb_tracking = True على SoundStreamTrainer ، ثم قم بما يلي
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () ثم يجب تدريب ثلاثة محولات منفصلة ( SemanticTransformer ، CoarseTransformer ، FineTransformer )
السابق. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () السابق. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () السابق. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()كل ذلك معًا الآن
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])تحديث: يبدو أن هذا سيعمل، نظرًا لـ "VALL-E"
السابق. المحول الدلالي
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] لأن جميع فئات المدرب تستخدم؟ Accelerator، يمكنك بسهولة إجراء تدريب على وحدات معالجة الرسومات المتعددة باستخدام أمر accelerate
في جذر المشروع
$ accelerate configثم في نفس الدليل
$ accelerate launch train . py محول خشن كامل
استخدم fairseq vq-wav2vec للتضمين
إضافة تكييف
إضافة إرشادات مجانية للمصنف
إضافة فريدة متتالية ل
دمج القدرة على استخدام ميزات Hubert الوسيطة كرموز دلالية، موصى بها من قبل eonglints
استيعاب الصوت المتغير الطول، وإحضار رمز eos
تأكد من العمل المتتالي الفريد مع المحول الخشن
طباعة جميلة جميع خسائر التمييز لتسجيل الدخول
التعامل معها عند إنشاء الرموز الدلالية، قد لا تكون هذه السجلات الأخيرة بالضرورة هي الأخيرة في التسلسل نظرًا للمعالجة المتتالية الفريدة
أكمل رمز أخذ العينات لكل من المحولات الخشنة والدقيقة، الأمر الذي سيكون أمرًا صعبًا
تأكد من أن الاستدلال الكامل مع أو بدون المطالبة يعمل على فئة AudioLM
أكمل كود التدريب الكامل لتدفق الصوت، مع الاهتمام بالتدريب على التمييز
إضافة عقوبة متدرجة فعالة للتمييزات لتدفق الصوت
قم بتوصيل عينة هرتز من مجموعة بيانات الصوت -> المحولات، واحصل على إعادة تشكيل مناسبة أثناء التدريب - فكر في ما إذا كان سيتم السماح لمجموعة البيانات بالحصول على ملفات صوت متفاوتة أو فرض نفس عينة هرتز
كود تدريب المحولات الكامل لجميع المحولات الثلاثة
إعادة البناء بحيث يحتوي المحول الدلالي على غلاف يتعامل مع المتتاليات الفريدة بالإضافة إلى wav إلى Hubert أو vq-wav2vec
ببساطة لا تحضر بنفسك إلى رمز eos على جانب المطالبة (دلالي للمحول الخشن، خشن للمحول الدقيق)
أضف التسرب المنظم من الإخفاء السببي النسيان، وهو أفضل بكثير من التسرب التقليدي
اكتشف كيفية منع تسجيل الدخول إلى fairseq
تأكد من أن المحولات الثلاثة التي تم تمريرها إلى Audiolm متوافقة
السماح بالتضمين الموضعي النسبي المتخصص في المحولات الدقيقة استنادًا إلى مواضع المطابقة المطلقة للمكممات بين الخشنة والناعمة
السماح بـ vq المتبقي المجمع في تدفق الصوت (استخدم GroupedResidualVQ من Vector-quantize-pytorch lib)، من hifi-codec
أضف انتباه الفلاش باستخدام NoPE
قبول الموجة الأولية في AudioLM كمسار إلى ملف صوتي، وإعادة تشكيل تلقائي للدلالي مقابل الصوتي
إضافة مفتاح/قيمة التخزين المؤقت لجميع المحولات، وتسريع الاستدلال
تصميم محول هرمي خشن ودقيق
تحقق من فك تشفير المواصفات، واختبر أولاً في محولات x، ثم قم بالتمرير إذا كان ذلك ممكنًا
إعادة التضمين الموضعي في وجود مجموعات في vq المتبقية
اختبار مع تركيب الكلام للمبتدئين
أداة cli، مثل audiolm generate <wav.file | text> واحفظ ملف wav الذي تم إنشاؤه في الدليل المحلي
قم بإرجاع قائمة الموجات في حالة الصوت المتغير الطول
ما عليك سوى الاعتناء بحالة الحافة في التدريب المكيف على نص المحولات الخشنة، حيث يتم إعادة تشكيل الموجة الأولية بترددات مختلفة. التحديد التلقائي لكيفية التوجيه بناءً على الطول
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

