self rewarding lm pytorch
0.2.12
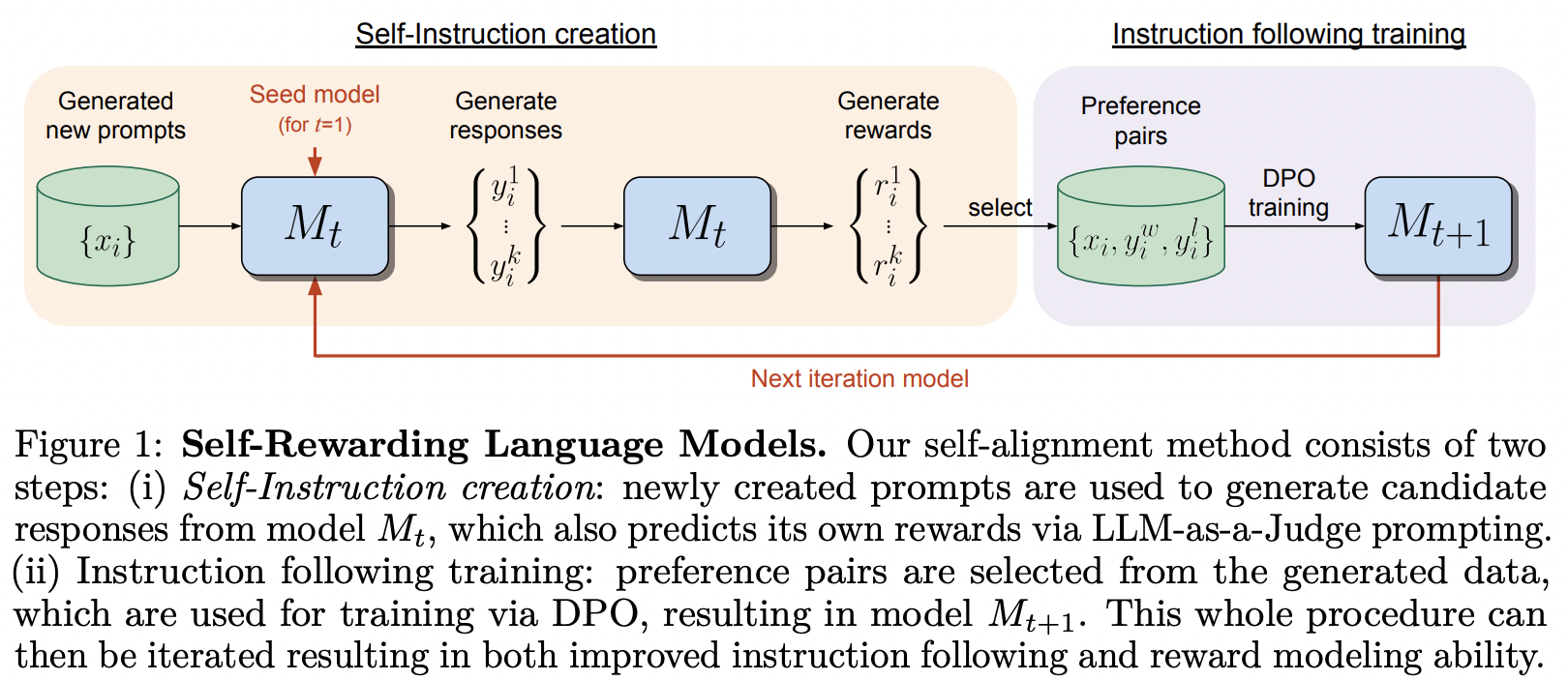
تنفيذ الإطار التدريبي المقترح في نموذج اللغة المكافئ ذاتيًا، من MetaAI
لقد أخذوا حقًا عنوان ورقة DPO على محمل الجد.
تحتوي هذه المكتبة أيضًا على تطبيق SPIN، والذي أعربت Teknium of Nous Research عن تفاؤله به.
$ pip install self-rewarding-lm-pytorch import torch
from torch import Tensor
from self_rewarding_lm_pytorch import (
SelfRewardingTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 1 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
prompt_dataset = create_mock_dataset ( 100 , lambda : 'mock prompt' )
def decode_tokens ( tokens : Tensor ) -> str :
decode_token = lambda token : str ( chr ( max ( 32 , token )))
return '' . join ( list ( map ( decode_token , tokens )))
def encode_str ( seq_str : str ) -> Tensor :
return Tensor ( list ( map ( ord , seq_str )))
trainer = SelfRewardingTrainer (
transformer ,
finetune_configs = dict (
train_sft_dataset = sft_dataset ,
self_reward_prompt_dataset = prompt_dataset ,
dpo_num_train_steps = 1000
),
tokenizer_decode = decode_tokens ,
tokenizer_encode = encode_str ,
accelerate_kwargs = dict (
cpu = True
)
)
trainer ( overwrite_checkpoints = True )
# checkpoints after each finetuning stage will be saved to ./checkpointsيمكن تدريب SPIN على النحو التالي - ويمكن أيضًا إضافته إلى مسار الضبط الدقيق كما هو موضح في المثال الأخير في الملف التمهيدي.
import torch
from self_rewarding_lm_pytorch import (
SPINTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 6 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
spin_trainer = SPINTrainer (
transformer ,
max_seq_len = 16 ,
train_sft_dataset = sft_dataset ,
checkpoint_every = 100 ,
spin_kwargs = dict (
λ = 0.1 ,
),
)
spin_trainer () لنفترض أنك تريد تجربة المطالبة بالمكافأة الخاصة بك (بخلاف LLM-as-Judge). تحتاج أولاً إلى استيراد RewardConfig ، وبعد ذلك قم بتمريره إلى المدرب كمكافأة_ reward_prompt_config
# first import
from self_rewarding_lm_pytorch import RewardConfig
# then say you want to try asking the transformer nicely
# reward_regex_template is the string that will be looked for in the LLM response, for parsing out the reward where {{ reward }} is defined as a number
trainer = SelfRewardingTrainer (
transformer ,
...,
self_reward_prompt_config = RewardConfig (
prompt_template = """
Pretty please rate the following user prompt and response
User: {{ prompt }}
Response: {{ response }}
Format your score as follows:
Rating: <rating as integer from 0 - 10>
""" ,
reward_regex_template = """
Rating: {{ reward }}
"""
)
) أخيرًا، إذا كنت ترغب في تجربة أوامر ضبط عشوائية، فستتمتع أيضًا بهذه المرونة، عن طريق تمرير مثيلات FinetuneConfig إلى finetune_configs كقائمة
السابق. لنفترض أنك تريد إجراء بحث حول تشذير SPIN والمكافأة الخارجية والمكافأة الذاتية
نشأت هذه الفكرة من Teknium من قناة Discord خاصة.
# import the configs
from self_rewarding_lm_pytorch import (
SFTConfig ,
SelfRewardDPOConfig ,
ExternalRewardDPOConfig ,
SelfPlayConfig ,
)
trainer = SelfRewardingTrainer (
model ,
finetune_configs = [
SFTConfig (...),
SelfPlayConfig (...),
ExternalRewardDPOConfig (...),
SelfRewardDPOConfig (...),
SelfPlayConfig (...),
SelfRewardDPOConfig (...)
],
...
)
trainer ()
# checkpoints after each finetuning stage will be saved to ./checkpoints تعميم أخذ العينات بحيث يمكن التقدم في مواضع مختلفة في الدفعة، وتثبيت جميع العينات التي سيتم دفعها. تسمح أيضًا بالتسلسلات المبطنة اليسرى، في حالة أن بعض الأشخاص لديهم محولات بمواضع نسبية تسمح بذلك
التعامل مع إيوس
اعرض مثالاً لاستخدام مطالبة المكافأة الخاصة بك بدلاً من دورة الحكم الافتراضية
السماح لاستراتيجيات مختلفة لأخذ عينات من الأزواج
سدادة مبكرة
أي ترتيب لـ sft، وspin، وdpo، وdpo للمكافأة الذاتية مع نموذج المكافأة الخارجية
السماح بوظيفة التحقق من صحة المكافآت (على سبيل المثال، يجب أن تكون المكافأة عددًا صحيحًا أو عائمًا أو بين بعض النطاقات وما إلى ذلك)
اكتشف أفضل السبل للتعامل مع مختلف أنواع ذاكرة التخزين المؤقت لـ kv، في الوقت الحالي فقط استغني عنها
علامة البيئة التي تقوم بمسح كافة مجلدات نقاط التفتيش تلقائيًا
@misc { yuan2024selfrewarding ,
title = { Self-Rewarding Language Models } ,
author = { Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston } ,
year = { 2024 } ,
eprint = { 2401.10020 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { Chen2024SelfPlayFC ,
title = { Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models } ,
author = { Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.01335 } ,
url = { https://api.semanticscholar.org/CorpusID:266725672 }
} @article { Rafailov2023DirectPO ,
title = { Direct Preference Optimization: Your Language Model is Secretly a Reward Model } ,
author = { Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.18290 } ,
url = { https://api.semanticscholar.org/CorpusID:258959321 }
} @inproceedings { Guo2024DirectLM ,
title = { Direct Language Model Alignment from Online AI Feedback } ,
author = { Shangmin Guo and Biao Zhang and Tianlin Liu and Tianqi Liu and Misha Khalman and Felipe Llinares and Alexandre Rame and Thomas Mesnard and Yao Zhao and Bilal Piot and Johan Ferret and Mathieu Blondel } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267522951 }
}

