rtdl revisiting models
1.0.0
مهم
تحقق من نموذج DL الجدولي الجديد: TabM
أرخايف؟ حزمة بايثون مشاريع DL الجدولية الأخرى
هذا هو التنفيذ الرسمي لورقة "إعادة النظر في نماذج التعلم العميق للبيانات الجدولية".
في جملة واحدة: لا تزال النماذج المشابهة لـ MLP بمثابة خطوط أساس جيدة، ويعتبر FT-Transformer بمثابة تكيف قوي جديد لبنية Transformer لمشاكل البيانات الجدولية.
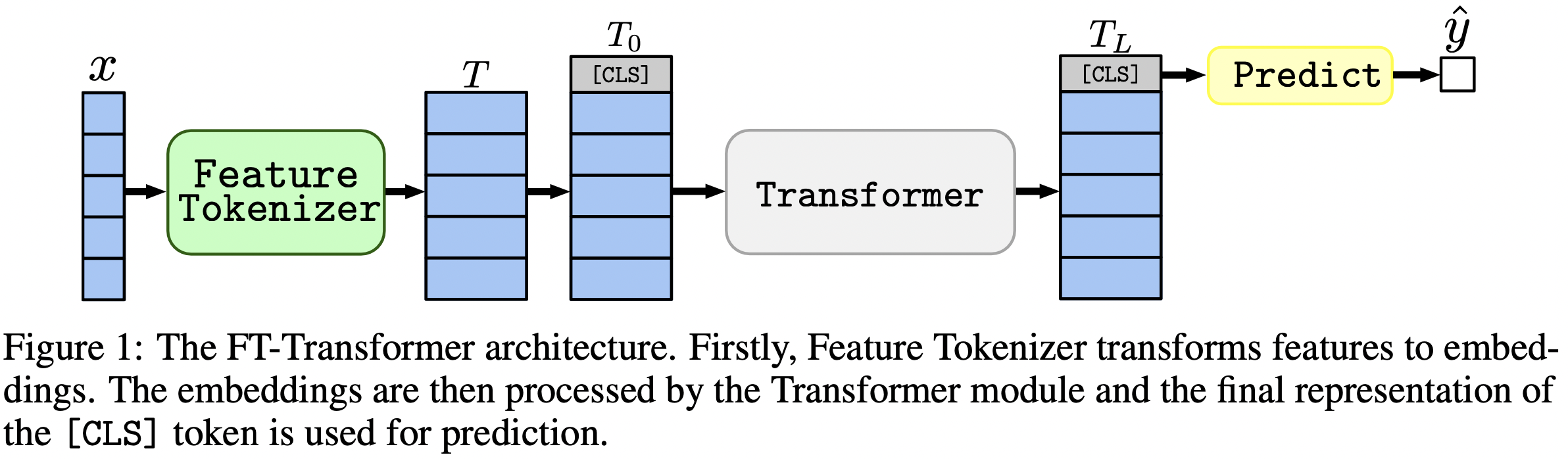
تركز الورقة على بنيات مشاكل البيانات الجدولية. النتائج:
تعد حزمة Python الموجودة في package/ الحزمة هي الطريقة الموصى بها لاستخدام الورقة في الممارسة العملية وفي العمل المستقبلي.
بقية الوثيقة :
يحتوي دليل output/ على نتائج عديدة ومعلمات تشعبية (مضبوطة) لمختلف النماذج ومجموعات البيانات المستخدمة في الورقة.
على سبيل المثال، دعنا نستكشف مقاييس نموذج MLP. لنقم أولاً بتحميل التقارير (ملفات stats.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])الآن، لكل مجموعة بيانات، دعونا نحسب متوسط درجات الاختبار على جميع البذور العشوائية:
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))يتطابق الإخراج تمامًا مع الجدول 2 من الورقة:
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
يمكن أيضًا استخدام الطريقة المذكورة أعلاه لاستكشاف المعلمات الفائقة للتعرف على قيم المعلمات الفائقة النموذجية للخوارزميات المختلفة. على سبيل المثال، هذه هي الطريقة التي يمكن بها حساب متوسط معدل التعلم المضبوط لنموذج MLP:
ملحوظة
بالنسبة لبعض الخوارزميات (مثل MLP)، تقدم المشاريع الأحدث المزيد من النتائج التي يمكن استكشافها بطريقة مماثلة. على سبيل المثال، راجع هذه الورقة على TabR.
تحذير
استخدم هذا النهج بحذر. عند دراسة قيم المعلمات الفائقة:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536ملحوظة
هذا القسم طويل. استخدم ميزة "المخطط التفصيلي" على GitHub في محرر النصوص الخاص بك للحصول على نظرة عامة على هذا القسم.
يتم تنظيم الكود على النحو التالي:
bin :ensemble.py عملية التجميعtune.py بإجراء ضبط المعلمات الفائقةanalysis_gbdt_vs_nn.py التجاربcreate_synthetic_data_plots.py يبني المخططاتlib على الأدوات الشائعة التي تستخدمها البرامج الموجودة في binoutput على ملفات التكوين (مدخلات البرامج في bin ) والنتائج (المقاييس والتكوينات المضبوطة وما إلى ذلك)package على حزمة بايثون لهذه الورقة قم بتثبيت كوندا
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsهذه البيئة مطلوبة فقط لتجربة TabNet. بالنسبة لجميع الحالات الأخرى، استخدم بيئة PyTorch.
التعليمات هي نفسها الخاصة ببيئة PyTorch (بما في ذلك تثبيت PyTorch!)، ولكن:
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt مباشرةً، قم بما يلي:pip install tensorflow-gpu==1.14tensorboard في requirements.txtالترخيص : من خلال تنزيل مجموعة البيانات الخاصة بنا، فإنك تقبل تراخيص جميع مكوناتها. ولا نفرض أي قيود جديدة بالإضافة إلى تلك التراخيص. يمكنك العثور على قائمة المصادر في قسم "المراجع" في ورقتنا.
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz يوفر هذا القسم فقط أوامر محددة مع القليل من التعليقات. بعد الانتهاء من البرنامج التعليمي، نوصي بمراجعة القسم التالي لفهم كيفية العمل مع المستودع بشكل أفضل. سيساعد أيضًا على فهم البرنامج التعليمي بشكل أفضل.
في هذا البرنامج التعليمي، سنقوم بإعادة إنتاج نتائج MLP في مجموعة بيانات الإسكان في كاليفورنيا. سوف نغطي:
لاحظ أن فرص الحصول على نفس النتائج تمامًا منخفضة نوعًا ما، ومع ذلك، لا ينبغي أن تختلف كثيرًا عن نتائجنا. قبل تشغيل أي شيء، انتقل إلى جذر المستودع وقم بتعيين CUDA_VISIBLE_DEVICES بشكل صريح (إذا كنت تخطط لاستخدام GPU):
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0قبل أن نبدأ، دعونا نتحقق من تكوين البيئة بنجاح. يجب أن تقوم الأوامر التالية بتدريب أحد MLP على مجموعة بيانات California Housing:
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml يجب أن تكون النتيجة في draft/check_environment . في الوقت الحالي، محتوى النتيجة ليس مهما.
التكوين الخاص بنا لضبط MLP على مجموعة بيانات الإسكان في كاليفورنيا موجود في output/california_housing/mlp/tuning/0.toml . من أجل إعادة إنتاج الضبط، انسخ التكوين الخاص بنا وقم بتشغيل الضبط الخاص بك:
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml ستكون نتيجة ضبطك موجودة في output/california_housing/mlp/tuning/reproduced ، ويمكنك مقارنتها بنتائجنا: output/california_housing/mlp/tuning/0 . يحتوي الملف best.toml على أفضل التكوين الذي سنقوم بتقييمه في القسم التالي.
علينا الآن تقييم التكوين المضبوط باستخدام 15 بذرة عشوائية مختلفة.
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done يوجد دليلنا الذي يحتوي على نتائج التقييم بجوار دليلك مباشرةً، أي في output/california_housing/mlp/tuned .
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced ستكون نتائجك موجودة في output/california_housing/mlp/tuned_reproduced_ensemble ، ويمكنك مقارنتها بنتائجنا: output/california_housing/mlp/tuned_ensemble .
استخدم النهج الموصوف هنا لتلخيص نتائج التجربة التي أجريت (تعديل مرشح المسار في .glob(...) وفقًا لذلك: tuned -> tuned_reproduced ).
يمكن تنفيذ خطوات مماثلة لجميع النماذج ومجموعات البيانات. تختلف عملية الضبط قليلًا في حالة بحث الشبكة: يجب عليك تشغيل كافة التكوينات المطلوبة واختيار الأفضل يدويًا بناءً على أداء التحقق من الصحة . على سبيل المثال، راجع output/epsilon/ft_transformer .
يجب عليك تشغيل برامج Python النصية من جذر المستودع. تتوقع معظم البرامج أن يكون ملف التكوين هو الوسيط الوحيد. سيكون الناتج عبارة عن دليل يحمل نفس اسم التكوين، ولكن بدون الامتداد. تتم كتابة التكوينات في TOML. لا يتم توفير قوائم الوسائط المحتملة للبرامج ويجب استنتاجها من البرامج النصية (عادةً، يتم تمثيل التكوين بمتغير args في البرامج النصية). إذا كنت تريد استخدام CUDA، فيجب عليك تعيين متغير البيئة CUDA_VISIBLE_DEVICES بشكل صريح. على سبيل المثال:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlإذا كنت ستستخدم CUDA طوال الوقت، فيمكنك حفظ متغير البيئة في بيئة Conda:
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " سيؤدي الخيار -f ( --force ) إلى إزالة النتائج الموجودة وتشغيل البرنامج النصي من البداية:
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config يدعم bin/tune.py الاستمرارية:
python bin/tune.py path/to/config.toml --continuestats.json والنتائج الأخرى بالنسبة لجميع البرامج النصية، يعد stats.json الجزء الأكثر أهمية في الإخراج. ويختلف المحتوى من برنامج لآخر. يمكن أن تحتوي على:
عادةً ما يتم أيضًا حفظ التنبؤات الخاصة بالتدريب والتحقق من الصحة ومجموعات الاختبار.
الآن، أنت تعرف كل ما تحتاجه لإعادة إنتاج جميع النتائج وتوسيع هذا المستودع لتلبية احتياجاتك. يجب أن يكون البرنامج التعليمي أكثر وضوحًا الآن. لا تتردد في فتح القضايا وطرح الأسئلة.
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


