nano neuron
1.0.0
7 وظائف جافا سكريبت بسيطة ستمنحك شعورًا بكيفية "التعلم" الفعلي للآلات.
بلغات أخرى: Русский، البرتغالية
قد تكون مهتمًا أيضًا؟ تجارب التعلم الآلي التفاعلية
NanoNeuron هي نسخة مبسطة للغاية من مفهوم Neuron من الشبكات العصبية. تم تدريب NanoNeuron على تحويل قيم درجات الحرارة من درجة مئوية إلى فهرنهايت.
يحتوي مثال التعليمات البرمجية NanoNeuron.js على 7 وظائف JavaScript بسيطة (والتي تتناول التنبؤ بالنموذج، وحساب التكلفة، والنشر للأمام/للخلف، والتدريب) والتي ستمنحك شعورًا بكيفية "التعلم" الفعلي للآلات. لا توجد مكتبات تابعة لجهات خارجية، ولا مجموعات بيانات أو تبعيات خارجية، فقط وظائف JavaScript نقية وبسيطة.
☝؟ هذه الوظائف ليست بأي حال من الأحوال دليلاً كاملاً للتعلم الآلي. يتم تخطي الكثير من مفاهيم التعلم الآلي والإفراط في تبسيطها! تم إجراء هذا التبسيط عن قصد لمنح القارئ فهمًا وشعورًا أساسيًا حقًا لكيفية تعلم الآلات وفي النهاية لتمكين القارئ من إدراك أنه ليس "سحر التعلم الآلي" بل "تعلم الآلة MATH"؟.
ربما سمعت عن الخلايا العصبية في سياق الشبكات العصبية. NanoNeuron هو مجرد ذلك ولكنه أبسط وسنقوم بتنفيذه من الصفر. ولأسباب تتعلق بالبساطة، لن نقوم حتى ببناء شبكة على NanoNeurons. سنجعل كل شيء يعمل من تلقاء نفسه، ليقوم ببعض التنبؤات السحرية لنا. على وجه التحديد، سنقوم بتعليم NanoNeuron المفرد تحويل (التنبؤ) بدرجة الحرارة من درجة مئوية إلى فهرنهايت.
بالمناسبة، صيغة التحويل من درجة مئوية إلى فهرنهايت هي كما يلي:
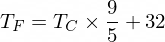
لكن في الوقت الحالي، لا يعرف NanoNeuron الخاص بنا شيئًا عن ذلك...
دعونا ننفذ وظيفة نموذج NanoNeuron الخاصة بنا. ينفذ التبعية الخطية الأساسية بين x و y والتي تبدو مثل y = w * x + b . نقول ببساطة إن NanoNeuron الخاص بنا هو "طفل" في "مدرسة" يتم تعليمه رسم الخط المستقيم بإحداثيات XY .
المتغيرات w , b هي معلمات النموذج. لا تعرف NanoNeuron سوى هاتين المعلمتين للدالة الخطية. هذه المعلمات هي شيء سوف "يتعلمه" NanoNeuron أثناء عملية التدريب.
الشيء الوحيد الذي يمكن لـ NanoNeuron فعله هو تقليد التبعية الخطية. في طريقة predict() الخاصة بها، تقبل بعض المدخلات x وتتنبأ بالإخراج y . لا يوجد سحر هنا.
function NanoNeuron ( w , b ) {
this . w = w ;
this . b = b ;
this . predict = ( x ) => {
return x * this . w + this . b ;
}
}(...انتظر... هل أنت من الانحدار الخطي؟) ؟
يمكن تحويل قيمة درجة الحرارة بالمئوية إلى فهرنهايت باستخدام الصيغة التالية: f = 1.8 * c + 32 ، حيث c هي درجة الحرارة بالمئوية و f هي درجة الحرارة المحسوبة بالفهرنهايت.
function celsiusToFahrenheit ( c ) {
const w = 1.8 ;
const b = 32 ;
const f = c * w + b ;
return f ;
} ; في النهاية، نريد تعليم NanoNeuron الخاص بنا كيفية تقليد هذه الوظيفة (لمعرفة أن w = 1.8 و b = 32 ) دون معرفة هذه المعلمات مسبقًا.
هذه هي الطريقة التي تبدو بها وظيفة التحويل من درجة مئوية إلى فهرنهايت:
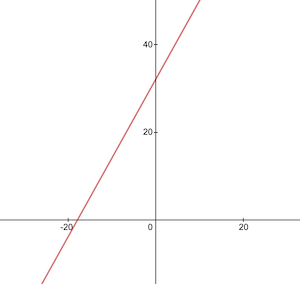
قبل التدريب، نحتاج إلى إنشاء مجموعات بيانات التدريب والاختبار بناءً على الدالة celsiusToFahrenheit() . تتكون مجموعات البيانات من أزواج من قيم الإدخال وقيم الإخراج ذات العلامات الصحيحة.
في الحياة الواقعية، في معظم الحالات، سيتم جمع هذه البيانات بدلاً من توليدها. على سبيل المثال، قد يكون لدينا مجموعة من الصور لأرقام مرسومة باليد ومجموعة الأرقام المقابلة لها والتي توضح الرقم المكتوب على كل صورة.
سوف نستخدم بيانات نموذج التدريب لتدريب NanoNeuron الخاص بنا. قبل أن ينمو جهاز NanoNeuron الخاص بنا ويكون قادرًا على اتخاذ القرارات بنفسه، نحتاج إلى تعليمه ما هو الصواب وما هو الخطأ باستخدام أمثلة التدريب.
سوف نستخدم أمثلة TEST لتقييم مدى جودة أداء NanoNeuron لدينا على البيانات التي لم تراها أثناء التدريب. هذه هي النقطة التي يمكننا أن نرى فيها أن "طفلنا" قد نما ويمكنه اتخاذ القرارات بنفسه.
function generateDataSets ( ) {
// xTrain -> [0, 1, 2, ...],
// yTrain -> [32, 33.8, 35.6, ...]
const xTrain = [ ] ;
const yTrain = [ ] ;
for ( let x = 0 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTrain . push ( x ) ;
yTrain . push ( y ) ;
}
// xTest -> [0.5, 1.5, 2.5, ...]
// yTest -> [32.9, 34.7, 36.5, ...]
const xTest = [ ] ;
const yTest = [ ] ;
// By starting from 0.5 and using the same step of 1 as we have used for training set
// we make sure that test set has different data comparing to training set.
for ( let x = 0.5 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTest . push ( x ) ;
yTest . push ( y ) ;
}
return [ xTrain , yTrain , xTest , yTest ] ;
} نحتاج إلى بعض المقاييس التي توضح لنا مدى قرب تنبؤات نموذجنا من تصحيح القيم. سيتم حساب التكلفة (الخطأ) بين قيمة الإخراج الصحيحة لـ y prediction ، التي أنشأها NanoNeuron، باستخدام الصيغة التالية:
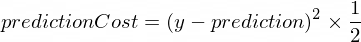
وهذا فرق بسيط بين قيمتين. كلما كانت القيم أقرب إلى بعضها البعض، كلما كان الفرق أصغر. نحن نستخدم قوة 2 هنا فقط للتخلص من الأرقام السالبة بحيث يكون (1 - 2) ^ 2 هو نفسه (2 - 1) ^ 2 . يتم القسمة على 2 فقط لتبسيط صيغة الانتشار العكسي (انظر أدناه).
ستكون وظيفة التكلفة في هذه الحالة بسيطة مثل:
function predictionCost ( y , prediction ) {
return ( y - prediction ) ** 2 / 2 ; // i.e. -> 235.6
} يعني القيام بالانتشار الأمامي إجراء تنبؤ لجميع أمثلة التدريب من مجموعات بيانات xTrain و yTrain وحساب متوسط تكلفة تلك التنبؤات على طول الطريق.
لقد سمحنا فقط لـ NanoNeuron بإبداء رأيها، في هذه المرحلة، من خلال السماح لها بتخمين كيفية تحويل درجة الحرارة. قد يكون من الخطأ بغباء هنا. سيوضح لنا متوسط التكلفة مدى خطأ نموذجنا في الوقت الحالي. تعتبر قيمة التكلفة هذه مهمة حقًا منذ تغيير معلمات NanoNeuron w و b ، ومن خلال إجراء النشر الأمامي مرة أخرى؛ سنكون قادرين على تقييم ما إذا كان NanoNeuron الخاص بنا قد أصبح أكثر ذكاءً أم لا بعد تغيير هذه المعلمات.
سيتم حساب متوسط التكلفة باستخدام الصيغة التالية:
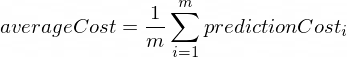
حيث m عبارة عن عدد من الأمثلة التدريبية (في حالتنا: 100 ).
إليك كيفية تنفيذ ذلك في الكود:
function forwardPropagation ( model , xTrain , yTrain ) {
const m = xTrain . length ;
const predictions = [ ] ;
let cost = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
const prediction = nanoNeuron . predict ( xTrain [ i ] ) ;
cost += predictionCost ( yTrain [ i ] , prediction ) ;
predictions . push ( prediction ) ;
}
// We are interested in average cost.
cost /= m ;
return [ predictions , cost ] ;
}عندما نعرف مدى صحة أو خطأ تنبؤات NanoNeuron (استنادًا إلى متوسط التكلفة في هذه المرحلة)، ما الذي يجب علينا فعله لجعل التنبؤات أكثر دقة؟
الانتشار العكسي يعطينا الإجابة على هذا السؤال. الانتشار العكسي هو عملية تقييم تكلفة التنبؤ وضبط معلمات NanoNeuron w و b بحيث تكون التنبؤات التالية والمستقبلية أكثر دقة.
هذا هو المكان الذي يبدو فيه التعلم الآلي كالسحر؟♂️. المفهوم الأساسي هنا هو المشتق الذي يوضح الخطوة التي يجب اتخاذها للاقتراب من الحد الأدنى لدالة التكلفة.
تذكر أن العثور على الحد الأدنى من دالة التكلفة هو الهدف النهائي لعملية التدريب. إذا وجدنا مثل هذه القيم لـ w و b بحيث تكون دالة متوسط التكلفة لدينا صغيرة، فهذا يعني أن نموذج NanoNeuron يقدم تنبؤات جيدة ودقيقة حقًا.
المشتقات موضوع كبير ومنفصل لن نغطيه في هذه المقالة. يعد MathIsFun مصدرًا جيدًا للحصول على فهم أساسي له.
أحد الأمور المتعلقة بالمشتقات التي ستساعدك على فهم كيفية عمل الانتشار العكسي هو أن المشتقة، بمعناها، هي خط مماس لمنحنى الدالة يشير إلى اتجاه الحد الأدنى للدالة.
مصدر الصورة: MathIsFun
على سبيل المثال، في المخطط أعلاه، يمكنك أن ترى أنه إذا كنا عند النقطة (x=2, y=4) فإن الميل يخبرنا بالتحرك left down للوصول إلى الحد الأدنى للدالة. لاحظ أيضًا أنه كلما كان المنحدر أكبر، كلما كان علينا التحرك بشكل أسرع إلى الحد الأدنى.
تبدو مشتقات دالة averageCost للمعلمات w و b كما يلي:
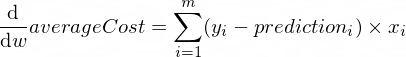
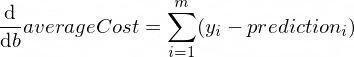
حيث m عبارة عن عدد من الأمثلة التدريبية (في حالتنا: 100 ).
يمكنك قراءة المزيد عن القواعد المشتقة وكيفية الحصول على مشتقة من الدوال المعقدة هنا.
function backwardPropagation ( predictions , xTrain , yTrain ) {
const m = xTrain . length ;
// At the beginning we don't know in which way our parameters 'w' and 'b' need to be changed.
// Therefore we're setting up the changing steps for each parameters to 0.
let dW = 0 ;
let dB = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
dW += ( yTrain [ i ] - predictions [ i ] ) * xTrain [ i ] ;
dB += yTrain [ i ] - predictions [ i ] ;
}
// We're interested in average deltas for each params.
dW /= m ;
dB /= m ;
return [ dW , dB ] ;
} الآن نحن نعرف كيفية تقييم صحة نموذجنا لجميع أمثلة مجموعة التدريب ( الانتشار الأمامي ). نحن نعرف أيضًا كيفية إجراء تعديلات صغيرة على المعلمات w و b لنموذج NanoNeuron الخاص بنا ( الانتشار العكسي ). لكن المشكلة هي أننا إذا قمنا بتشغيل الانتشار للأمام ثم الانتشار للخلف مرة واحدة فقط، فلن يكون كافيًا لنموذجنا أن يتعلم أي قوانين/اتجاهات من بيانات التدريب. يمكنك مقارنتها بحضور يوم واحد في المدرسة الابتدائية للطفل. يجب عليه أن يذهب إلى المدرسة ليس مرة واحدة بل يومًا بعد يوم وعامًا بعد عام ليتعلم شيئًا ما.
لذلك نحن بحاجة إلى تكرار الانتشار الأمامي والخلفي لنموذجنا عدة مرات. هذا هو بالضبط ما تفعله الدالة trainModel() . إنه بمثابة "المعلم" لنموذج NanoNeuron الخاص بنا:
epochs ) مع نموذج NanoNeuron الغبي بعض الشيء ويحاول تدريبه/تعليمه،xTrain و yTrain ) للتدريب،alpha بضع كلمات حول معدل التعلم alpha . وهذا مجرد مضاعف لقيم dW و dB التي قمنا بحسابها أثناء الانتشار الخلفي. لذلك، وجهتنا المشتقة نحو الاتجاه الذي نحتاج إلى اتخاذه للعثور على الحد الأدنى من دالة التكلفة (علامة dW و dB ) كما أوضحت لنا مدى السرعة التي نحتاجها للمضي قدمًا في هذا الاتجاه (القيم المطلقة لـ dW و dB ). نحن الآن بحاجة إلى مضاعفة أحجام الخطوات تلك إلى alpha فقط لضبط حركتنا إلى الحد الأدنى بشكل أسرع أو أبطأ. في بعض الأحيان، إذا استخدمنا قيمًا كبيرة لـ alpha ، فقد نقفز ببساطة فوق الحد الأدنى ولا نجده أبدًا.
التشبيه مع المعلم هو أنه كلما دفع "طفلنا الصغير" بقوة كلما تعلم "طفلنا الصغير" بشكل أسرع، ولكن إذا ضغط المعلم بقوة أكثر من اللازم، فإن "الطفل" سيصاب بانهيار عصبي ولن يتمكن من ذلك. لن تكون قادرًا على تعلم أي شيء؟
إليك كيفية تحديث معلمات نموذجنا w و b :
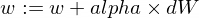
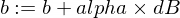
وهنا وظيفة المدرب لدينا:
function trainModel ( { model , epochs , alpha , xTrain , yTrain } ) {
// The is the history array of how NanoNeuron learns.
const costHistory = [ ] ;
// Let's start counting epochs.
for ( let epoch = 0 ; epoch < epochs ; epoch += 1 ) {
// Forward propagation.
const [ predictions , cost ] = forwardPropagation ( model , xTrain , yTrain ) ;
costHistory . push ( cost ) ;
// Backward propagation.
const [ dW , dB ] = backwardPropagation ( predictions , xTrain , yTrain ) ;
// Adjust our NanoNeuron parameters to increase accuracy of our model predictions.
nanoNeuron . w += alpha * dW ;
nanoNeuron . b += alpha * dB ;
}
return costHistory ;
}الآن دعونا نستخدم الوظائف التي أنشأناها أعلاه.
لنقم بإنشاء مثيل نموذج NanoNeuron الخاص بنا. في هذه اللحظة، لا يعرف NanoNeuron القيم التي يجب تعيينها للمعلمات w و b . لذلك دعونا نقوم بإعداد w و b بشكل عشوائي.
const w = Math . random ( ) ; // i.e. -> 0.9492
const b = Math . random ( ) ; // i.e. -> 0.4570
const nanoNeuron = new NanoNeuron ( w , b ) ;إنشاء مجموعات بيانات التدريب والاختبار.
const [ xTrain , yTrain , xTest , yTest ] = generateDataSets ( ) ; دعونا ندرب النموذج بخطوات تزايدية صغيرة ( 0.0005 ) لمدة 70000 فترة. يمكنك اللعب بهذه المعلمات، حيث يتم تعريفها تجريبيًا.
const epochs = 70000 ;
const alpha = 0.0005 ;
const trainingCostHistory = trainModel ( { model : nanoNeuron , epochs , alpha , xTrain , yTrain } ) ;دعونا نتحقق من كيفية تغير دالة التكلفة أثناء التدريب. نتوقع أن تكون التكلفة بعد التدريب أقل بكثير من ذي قبل. وهذا يعني أن NanoNeuron أصبح أكثر ذكاءً. والعكس ممكن أيضا.
console . log ( 'Cost before the training:' , trainingCostHistory [ 0 ] ) ; // i.e. -> 4694.3335043
console . log ( 'Cost after the training:' , trainingCostHistory [ epochs - 1 ] ) ; // i.e. -> 0.0000024 هذه هي الطريقة التي تتغير بها تكلفة التدريب على مر العصور. على المحاور x يوجد رقم العصر x1000.
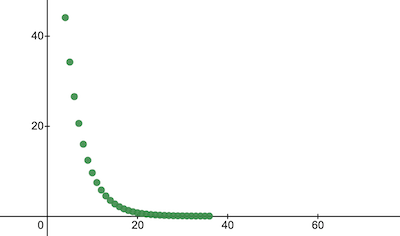
دعونا نلقي نظرة على معلمات NanoNeuron لمعرفة ما تعلمته. نتوقع أن تكون معلمات NanoNeuron w و b مشابهة لتلك الموجودة في الدالة celsiusToFahrenheit() ( w = 1.8 و b = 32 ) نظرًا لأن NanoNeuron الخاص بنا حاول تقليدها.
console . log ( 'NanoNeuron parameters:' , { w : nanoNeuron . w , b : nanoNeuron . b } ) ; // i.e. -> {w: 1.8, b: 31.99}قم بتقييم دقة النموذج لمجموعة بيانات الاختبار لمعرفة مدى جودة تعامل NanoNeuron مع تنبؤات البيانات الجديدة غير المعروفة. من المتوقع أن تكون تكلفة التنبؤات على مجموعات الاختبار قريبة من تكلفة التدريب. وهذا يعني أن NanoNeuron الخاص بنا يعمل بشكل جيد فيما يتعلق بالبيانات المعروفة وغير المعروفة.
[ testPredictions , testCost ] = forwardPropagation ( nanoNeuron , xTest , yTest ) ;
console . log ( 'Cost on new testing data:' , testCost ) ; // i.e. -> 0.0000023الآن، بما أننا نرى أن "طفلنا" NanoNeuron قد أدى أداءً جيدًا في "المدرسة" أثناء التدريب وأنه يمكنه تحويل درجات الحرارة المئوية إلى فهرنهايت بشكل صحيح، حتى بالنسبة للبيانات التي لم يرها، يمكننا أن نطلق عليه "ذكي". وطرح عليه بعض الأسئلة. وكان هذا هو الهدف النهائي لعملية التدريب بأكملها.
const tempInCelsius = 70 ;
const customPrediction = nanoNeuron . predict ( tempInCelsius ) ;
console . log ( `NanoNeuron "thinks" that ${ tempInCelsius } °C in Fahrenheit is:` , customPrediction ) ; // -> 158.0002
console . log ( 'Correct answer is:' , celsiusToFahrenheit ( tempInCelsius ) ) ; // -> 158قريبة جدا! كجميع البشر، فإن NanoNeuron الخاص بنا جيد ولكنه ليس مثاليًا :)
تعلم سعيد لك!
يمكنك استنساخ المستودع وتشغيله محليًا:
git clone https://github.com/trekhleb/nano-neuron.git
cd nano-neuronnode ./NanoNeuron.jsتم تخطي مفاهيم التعلم الآلي التالية وتبسيطها لتسهيل الشرح.
تدريب/اختبار تقسيم مجموعة البيانات
عادةً ما يكون لديك مجموعة واحدة كبيرة من البيانات. اعتمادًا على عدد الأمثلة في تلك المجموعة، قد ترغب في تقسيمها بنسبة 70/30 لمجموعات التدريب/الاختبار. يجب أن يتم خلط البيانات الموجودة في المجموعة بشكل عشوائي قبل التقسيم. إذا كان عدد الأمثلة كبيرًا (أي الملايين)، فقد يحدث التقسيم بنسب أقرب إلى 90/10 أو 95/5 لمجموعات بيانات التدريب/الاختبار.
الشبكة تجلب القوة
عادةً لن تلاحظ استخدام خلية عصبية واحدة مستقلة فقط. القوة موجودة في شبكة هذه الخلايا العصبية. قد تتعلم الشبكة ميزات أكثر تعقيدًا. يبدو NanoNeuron وحده أشبه بانحدار خطي بسيط منه بشبكة عصبية.
تطبيع الإدخال
قبل التدريب، سيكون من الأفضل تطبيع قيم الإدخال.
التنفيذ المتجه
بالنسبة للشبكات، تعمل الحسابات الموجهة (المصفوفة) بشكل أسرع بكثير for الحلقات. عادةً ما يعمل الانتشار للأمام/للخلف بشكل أسرع بكثير إذا تم تنفيذه في شكل متجه وحسابه باستخدام مكتبة Numpy Python، على سبيل المثال.
الحد الأدنى من وظيفة التكلفة
إن دالة التكلفة التي كنا نستخدمها في هذا المثال مبالغ فيها. يجب أن تحتوي على مكونات لوغاريتمية. سيؤدي تغيير دالة التكلفة أيضًا إلى تغيير مشتقاتها، وبالتالي فإن خطوة النشر الخلفي ستستخدم أيضًا صيغًا مختلفة.
وظيفة التنشيط
عادة يجب أن يتم تمرير مخرجات الخلية العصبية من خلال وظيفة التنشيط مثل Sigmoid أو ReLU أو غيرها.


