PALM E
0.0.4

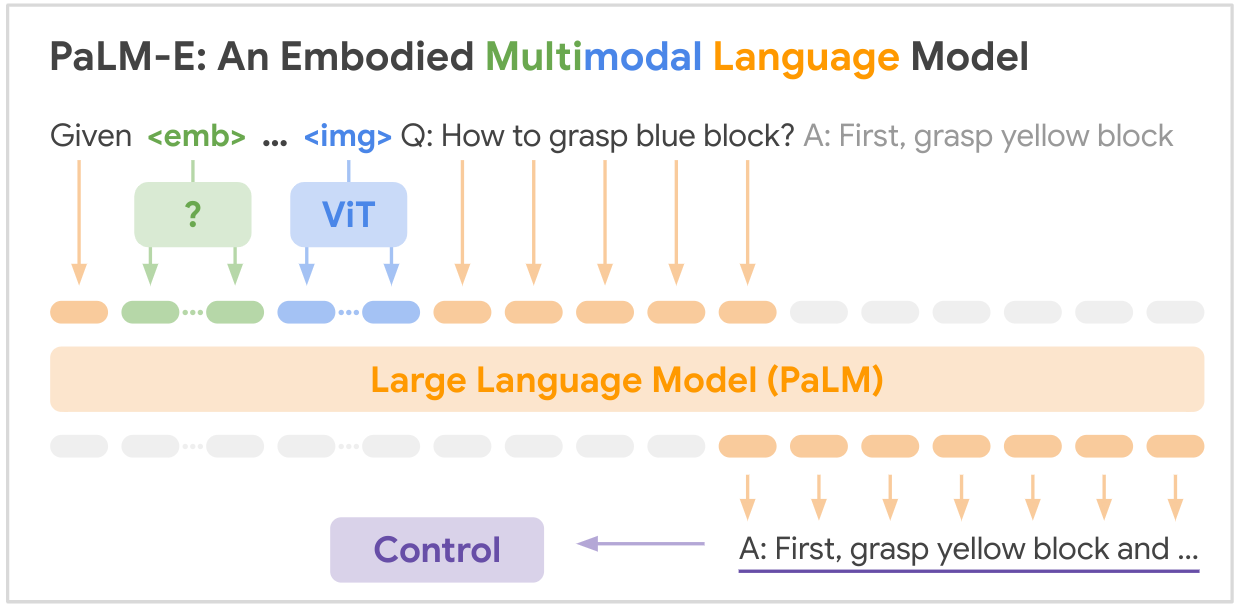
هذا هو تطبيق مفتوح المصدر لنموذج مؤسسة SOTA متعدد الوسائط "PALM-E: نموذج لغة متعدد الوسائط مجسد" من Google، PALM-E هو نموذج واحد كبير مجسد متعدد الوسائط، يمكنه معالجة مجموعة متنوعة من مهام الاستدلال المتجسد، من تُظهِر مجموعة متنوعة من طرائق المراقبة، على تجسيدات متعددة، علاوة على ذلك، نقلًا إيجابيًا: يستفيد النموذج من التدريب المشترك المتنوع عبر مجالات اللغة والرؤية واللغة المرئية على نطاق الإنترنت.
رابط الورق: PaLM-E: نموذج لغة متعدد الوسائط مجسد
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
فيما يلي جدول ملخص لمجموعات البيانات الرئيسية المذكورة في الورقة:
| مجموعة البيانات | المهام | مقاس | وصلة |
|---|---|---|---|
| حشا | تخطيط التلاعب الآلي، VQA | 96000 مشاهد | مجموعة البيانات المخصصة |
| جدول اللغة | تخطيط التلاعب الروبوتي | مجموعة البيانات المخصصة | وصلة |
| التلاعب بالموبايل | الملاحة الروبوتية وتخطيط المعالجة، VQA | 2912 تسلسل | بناءً على مجموعة بيانات SayCan |
| ويب لي | استرجاع النص الصورة | 66 مليون زوج من التسميات التوضيحية للصور | وصلة |
| VQAv2 | الإجابة على السؤال البصري | 1.1 مليون سؤال على صور COCO | وصلة |
| موافق-VQA | الإجابة على الأسئلة المرئية تتطلب معرفة خارجية | 14031 سؤالاً على صور COCO | وصلة |
| كوكو | تعليق الصورة | 330 ألف صورة مع التسميات التوضيحية | وصلة |
| ويكيبيديا | جسم النص | لا يوجد | وصلة |
تم جمع مجموعات بيانات الروبوتات الرئيسية خصيصًا لهذا العمل، في حين أن مجموعات بيانات لغة الرؤية الأكبر (WebLI، VQAv2، OK-VQA، COCO) تعد معايير قياسية في هذا المجال. تتراوح مجموعات البيانات من عشرات الآلاف من الأمثلة في مجالات الروبوتات إلى عشرات الملايين من بيانات لغة الرؤية على نطاق الإنترنت.
هناك حاجة إلى تألق الخاص بك! انضم إلينا، ومعًا، لنجعل PALM-E أكثر روعة:
؟ إصلاحات،؟ التحسينات أو المستندات أو الأفكار – كلها موضع ترحيب! دعونا نشكل مستقبل الذكاء الاصطناعي، يدًا بيد.
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

