pi zero pytorch
0.1.5
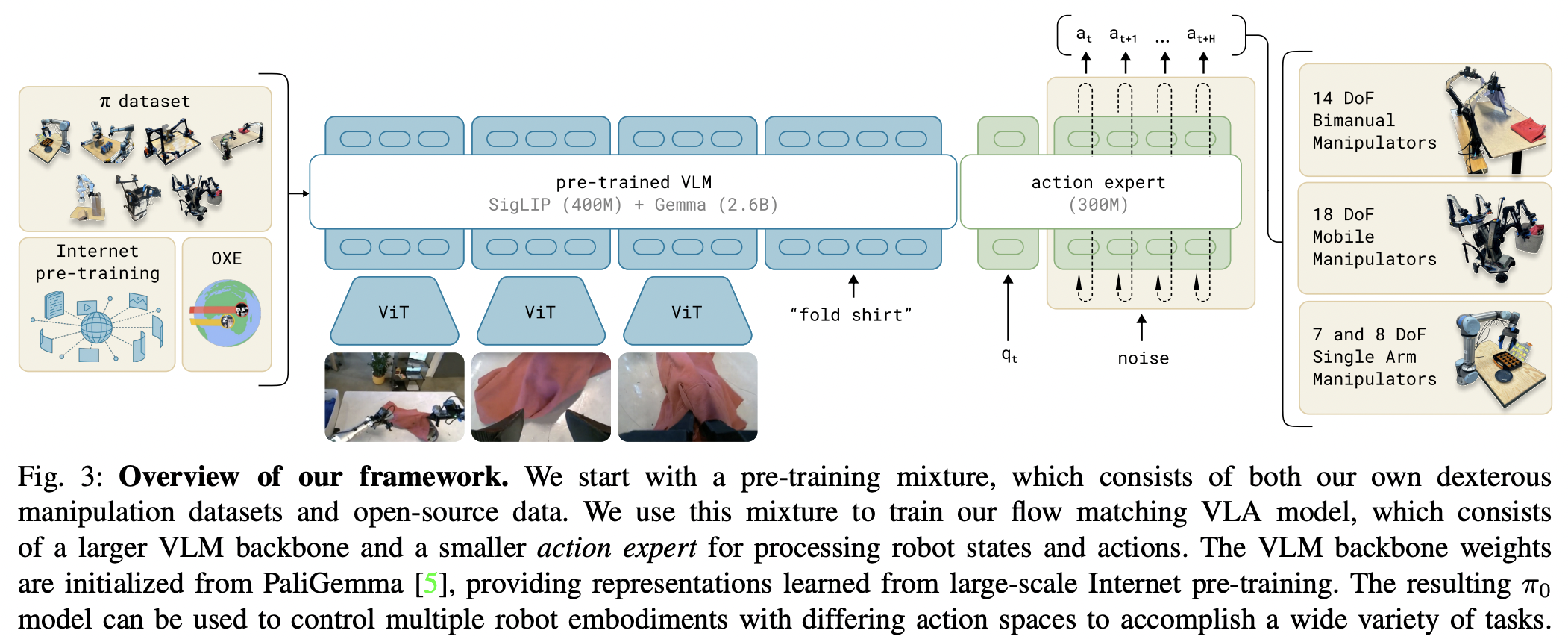
تنفيذ π₀ بنية نموذج الأساس الآلي الذي اقترحه الذكاء الفيزيائي
ملخص هذا العمل هو أنه عبارة عن عملية نقل مبسطة (Zhou et al.) مع تأثير من Stable Diffusion 3 (Esser et al.)، وبشكل أساسي اعتماد مطابقة التدفق بدلاً من الانتشار لتوليد السياسات، فضلاً عن فصل المعلمات (اهتمام مشترك من mmDIT). إنهم يعتمدون على نموذج لغة الرؤية المُدرب مسبقًا، PaliGemma 2B.
Einops للحزمة المذهلة والتفريغ، يتم استخدامها على نطاق واسع هنا لإدارة مجموعات الرموز المميزة المختلفة
Flex Attention للسماح بمزيج سهل من الاهتمام التلقائي والانتباه ثنائي الاتجاه
@ Wonder1905 لمراجعة الكود وتحديد المشكلات
أنت؟ ربما طالب دكتوراه يريد المساهمة في أحدث بنية SOTA للاستنساخ السلوكي؟
$ pip install pi-zero-pytorch import torch
from pi_zero_pytorch import π0
model = π0 (
dim = 512 ,
dim_action_input = 6 ,
dim_joint_state = 12 ,
num_tokens = 20_000
)
vision = torch . randn ( 1 , 1024 , 512 )
commands = torch . randint ( 0 , 20_000 , ( 1 , 1024 ))
joint_state = torch . randn ( 1 , 12 )
actions = torch . randn ( 1 , 32 , 6 )
loss , _ = model ( vision , commands , joint_state , actions )
loss . backward ()
# after much training
sampled_actions = model ( vision , commands , joint_state , trajectory_length = 32 ) # (1, 32, 6)في جذر المشروع، قم بتشغيل
$ pip install ' .[test] ' # or `uv pip install '.[test]'` ثم أضف اختباراتك إلى tests/test_pi_zero.py وقم بتشغيلها
$ pytest tests/هذا كل شيء
@misc { Black2024 ,
author = { Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, Ury Zhilinsky } ,
url = { https://www.physicalintelligence.company/download/pi0.pdf }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @article { Li2024ImmiscibleDA ,
title = { Immiscible Diffusion: Accelerating Diffusion Training with Noise Assignment } ,
author = { Yiheng Li and Heyang Jiang and Akio Kodaira and Masayoshi Tomizuka and Kurt Keutzer and Chenfeng Xu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2406.12303 } ,
url = { https://api.semanticscholar.org/CorpusID:270562607 }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
} @article { Bulatov2022RecurrentMT ,
title = { Recurrent Memory Transformer } ,
author = { Aydar Bulatov and Yuri Kuratov and Mikhail S. Burtsev } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.06881 } ,
url = { https://api.semanticscholar.org/CorpusID:250526424 }
} @inproceedings { Bessonov2023RecurrentAT ,
title = { Recurrent Action Transformer with Memory } ,
author = { A. B. Bessonov and Alexey Staroverov and Huzhenyu Zhang and Alexey K. Kovalev and D. Yudin and Aleksandr I. Panov } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:259188030 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}عزيزتي أليس


