lion pytorch
0.2.3
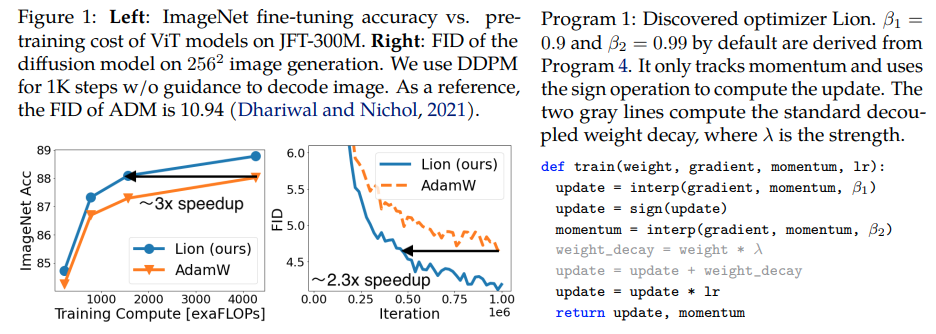
Lion، Evo Lved Sign Mome ntum ، مُحسِّن جديد اكتشفه Google Brain ويُزعم أنه أفضل من Adam(w) في Pytorch. هذه نسخة مباشرة تقريبًا من هنا، مع بعض التعديلات الطفيفة.
إنه أمر بسيط للغاية، ربما يمكننا أيضًا أن نجعله في متناول الجميع ويستخدمه في أسرع وقت ممكن لتدريب بعض النماذج الرائعة، إذا كان يعمل بالفعل؟
معدل التعلم وتناقص الوزن: كتب المؤلفون في القسم 5 - Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. يجب تغيير القيمة الأولية وقيمة الذروة والقيمة النهائية في جدول معدل التعلم في وقت واحد بنفس النسبة مقارنة بـ AdamW، كما يتضح من أحد الباحثين.
جدول معدل التعلم: يستخدم المؤلفون نفس جدول معدل التعلم لـ Lion مثل AdamW في الورقة. ومع ذلك، فقد لاحظوا ربحًا أكبر عند استخدام جدول اضمحلال جيب التمام لتدريب ViT، مقارنةً بجدول الجذر التربيعي المتبادل.
β1 وβ2: كتب المؤلفون في القسم 5 - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. على غرار الطريقة التي يقوم بها الأشخاص بتخفيض β2 إلى 0.99 أو أصغر وزيادة ε إلى 1e-6 في AdamW لتحسين الاستقرار، فإن استخدام β1=0.95, β2=0.98 في Lion يمكن أن يكون مفيدًا أيضًا في تخفيف عدم الاستقرار أثناء التدريب، كما اقترح المؤلفون. وهذا ما أكده أحد الباحثين.
التحديث: يبدو أنه يعمل مع نموذج لغة الانحدار التلقائي enwik8 المحلي الخاص بي.
التحديث 2: التجارب تبدو أسوأ بكثير من آدم إذا ظل معدل التعلم ثابتًا.
التحديث 3: قسمة معدل التعلم على 3، ورؤية نتائج مبكرة أفضل من آدم. ربما تم خلع آدم من العرش بعد ما يقرب من عقد من الزمن.
التحديث 4: أدى استخدام قاعدة معدل التعلم الأصغر بمقدار 10 مرات من الورقة إلى أسوأ تشغيل. لذلك أعتقد أن الأمر لا يزال يتطلب القليل من الضبط.
تلخيص التحديثات السابقة: كما هو موضح في التجارب، يتفوق الأسد بمعدل تعلم أقل 3 مرات على آدم. لا يزال الأمر يتطلب القليل من الضبط لأن معدل التعلم الأصغر بمقدار 10 مرات يؤدي إلى نتيجة أسوأ.
التحديث 5: تم سماع جميع النتائج الإيجابية لنمذجة اللغة حتى الآن، عندما يتم ذلك بشكل صحيح. سمعت أيضًا نتائج إيجابية للتدريب الكبير على تحويل النص إلى صورة، على الرغم من أن الأمر يتطلب القليل من الضبط. يبدو أن النتائج السلبية تتعلق بمشاكل وبُنى خارج نطاق ما تم تقييمه في الورقة - RL، وشبكات التغذية الأمامية، والبنيات الهجينة الغريبة مع LSTMs + التلافيفات وما إلى ذلك. وتؤكد البيانات السلبية أيضًا أن هذه التقنية حساسة لحجم الدفعة وكمية البيانات/الزيادة . سيتم تحديد الجدول الزمني الأمثل لمعدل التعلم، وما إذا كان التباطؤ يؤثر على النتائج. ومن المثير للاهتمام أيضًا وجود نتيجة إيجابية عند المقطع المفتوح، والتي أصبحت سلبية مع زيادة حجم النموذج (ولكن قد يكون قابلاً للحل).
التحديث 6: تم حل مشكلة المقطع المفتوح بواسطة المؤلف، عن طريق ضبط درجة حرارة أولية أعلى.
التحديث 7: سيوصي فقط بهذا المحسن في إعداد أحجام الدُفعات العالية (64 أو أعلى)
$ نقطة تثبيت Lion-Pytorch
بدلًا من ذلك، استخدم كوندا:
$ كوندا تثبيت Lion-Pytorch
# نموذج لعبة استيراد الشعلة من الشعلة import nnmodel = nn.Linear(10, 1)# استيراد الأسد وإنشاء مثيل له باستخدام المعلمات من lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4,weight_decay=1e-2)# Forward and backsloss = model(torch.randn(10))loss.backward()# محسن stepopt.step()opt.zero_grad()
لاستخدام نواة مدمجة لتحديث المعلمات، pip install triton -U --pre ، ثم
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # اضبط هذا على True لاستخدام cuda kernel w/ Triton lang (Tillet et al))
Stability.ai للرعاية السخية للعمل وأبحاث الذكاء الاصطناعي المتطورة مفتوحة المصدر
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Chen, Xiangning and Liang, Chen and Huang, Da and Real, إستيبان ووانغ، كايوان وليو، ياو وفام، هيو ودونغ، شوانيي and Luong, Thang and Hsieh, Cho-Jui and Lu, Yifeng and Le, Quoc V.},title = {الاكتشاف الرمزي لخوارزميات التحسين},publisher = {arXiv},year = {2023}} @article{Tillet2019TritonAI,title = {Triton: لغة وسيطة ومترجم لحسابات الشبكة العصبية المتجانبة}، المؤلف = {Philippe Tillet and H. Kung and D. Cox},journal = {Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine تعلم لغات البرمجة}، السنة = {2019}} @misc{Schaipp2024,author = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {المحسنون الحذرون: تحسين التدريب باستخدام سطر واحد من التعليمات البرمجية}، المؤلف = {Kaizhao Liang and Lizhang Chen and Bo Liu and Qiang Liu}، العام = {2024}، URL = {https://api .semanticscholar.org/CorpusID:274234738}} 

