meshgpt pytorch
1.8.1
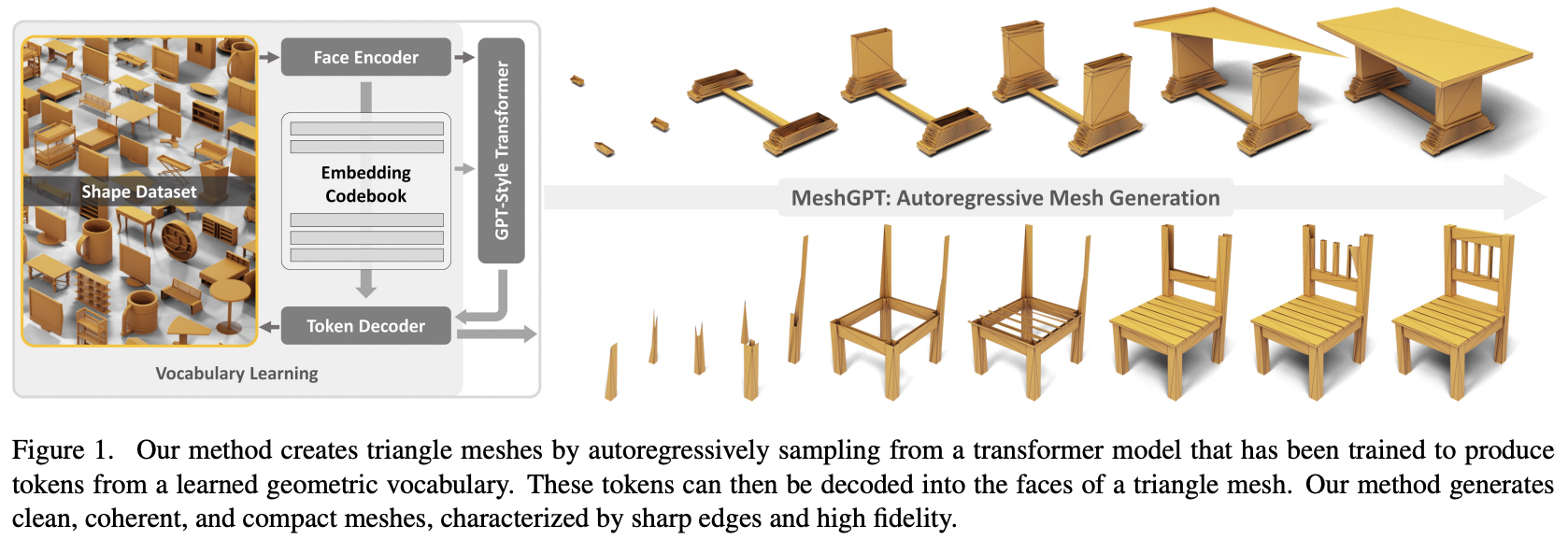
تنفيذ إنشاء شبكة MeshGPT وSOTA باستخدام Attention في Pytorch
سيتم أيضًا إضافة تكييف النص، لتحويل النص إلى أصل ثلاثي الأبعاد في نهاية المطاف
يرجى الانضمام إذا كنت مهتمًا بالتعاون مع الآخرين لتكرار هذا العمل
تحديث: قام ماركوس بتدريب نموذج عمل وتحميله إلى؟ معانقة الوجه!
StabilityAI وبرنامج منحة الذكاء الاصطناعي مفتوح المصدر A16Z و؟ معانقة للرعايات السخية، وكذلك الرعاة الآخرين، لمنحني الاستقلالية لإجراء أبحاث الذكاء الاصطناعي الحالية مفتوحة المصدر
Einops لجعل حياتي سهلة
ماركوس لمراجعة الكود الأولية (مع الإشارة إلى بعض الميزات المشتقة المفقودة) بالإضافة إلى تشغيل أول تجارب شاملة ناجحة
ماركوس لأول تدريب ناجح لمجموعة من الأشكال المشروطة بالملصقات
Quexi Ma للعثور على العديد من الأخطاء من خلال المعالجة التلقائية لـ eos
Yingtian لاكتشافه خطأً في التمويه الغاوسي لمواضع تجانس التسمية المكانية
ماركوس مرة أخرى لإجراء التجارب للتحقق من إمكانية توسيع النظام من المثلثات إلى الأرباع
ماركوس للتعرف على مشكلة تتعلق بتكييف النص ولإجراء جميع التجارب التي أدت إلى حلها
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset بالنسبة لتركيب الأشكال ثلاثية الأبعاد المشروطة بالنص، ما عليك سوى تعيين condition_on_text = True على MeshTransformer ، ثم قم بتمرير قائمة الأوصاف الخاصة بك كوسيطة الكلمات الرئيسية texts
السابق.
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
) إذا كنت ترغب في ترميز الشبكات، لاستخدامها في المحول متعدد الوسائط، فما عليك سوى استدعاء .tokenize على جهاز التشفير التلقائي الخاص بك (أو نفس الطريقة في مثيل مدرب جهاز التشفير التلقائي للنموذج السلس بشكل كبير)
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) في جذر المشروع، قم بتشغيل
$ cp .env.sample .envالتشفير التلقائي
face_edges تلقائيًا مباشرةً من الوجوه والقمم محول
غلاف المدرب مع تسريع التردد العالي
تكييف النص باستخدام مكتبة CFG الخاصة
المحولات الهرمية (باستخدام محول RQ)
إصلاح التخزين المؤقت في طبقة Gateloop البسيطة في الريبو الأخرى
الاهتمام المحلي
إصلاح التخزين المؤقت لـ kv للمحول الهرمي ثنائي المراحل - أسرع 7 مرات الآن، وأسرع من المحول الأصلي غير الهرمي
إصلاح التخزين المؤقت لطبقات Gateloop
السماح بتخصيص أبعاد النموذج لشبكة الانتباه الدقيقة مقابل شبكة الانتباه الخشنة
اكتشف ما إذا كان جهاز التشفير التلقائي ضروريًا حقًا - فهو ضروري، فالاستئصال موجود في الورقة
جعل المحول فعالا
خيار فك التشفير المضاربة
قضاء يوم في التوثيق
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

