block recurrent transformer pytorch
0.4.4
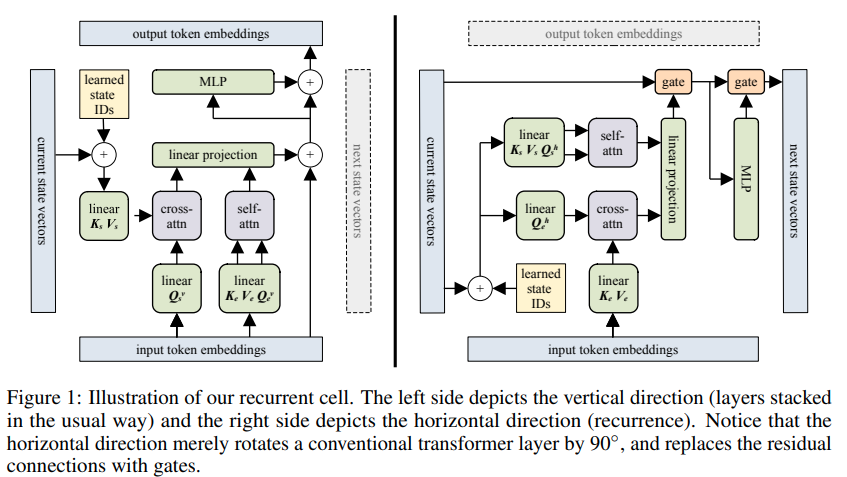
تنفيذ كتلة المحولات المتكررة - Pytorch. أهم ما يميز الورقة هو قدرتها المعلنة على تذكر شيء ما يصل إلى 60 ألف رمز مضت.
هذا التصميم هو SOTA لخط بحث المحولات المتكررة.
سيتضمن أيضًا انتباهًا سريعًا بالإضافة إلى ذكريات موجهة لما يصل إلى 250 ألف رمز باستخدام أفكار من هذه الورقة
$ pip install block-recurrent-transformer-pytorch import torch
from block_recurrent_transformer_pytorch import BlockRecurrentTransformer
model = BlockRecurrentTransformer (
num_tokens = 20000 , # vocab size
dim = 512 , # model dimensions
depth = 6 , # depth
dim_head = 64 , # attention head dimensions
heads = 8 , # number of attention heads
max_seq_len = 1024 , # the total receptive field of the transformer, in the paper this was 2 * block size
block_width = 512 , # block size - total receptive field is max_seq_len, 2 * block size in paper. the block furthest forwards becomes the new cached xl memories, which is a block size of 1 (please open an issue if i am wrong)
num_state_vectors = 512 , # number of state vectors, i believe this was a single block size in the paper, but can be any amount
recurrent_layers = ( 4 ,), # where to place the recurrent layer(s) for states with fixed simple gating
use_compressed_mem = False , # whether to use compressed memories of a single block width, from https://arxiv.org/abs/1911.05507
compressed_mem_factor = 4 , # compression factor of compressed memories
use_flash_attn = True # use flash attention, if on pytorch 2.0
)
seq = torch . randint ( 0 , 2000 , ( 1 , 1024 ))
out , mems1 , states1 = model ( seq )
out , mems2 , states2 = model ( seq , xl_memories = mems1 , states = states1 )
out , mems3 , states3 = model ( seq , xl_memories = mems2 , states = states2 ) pip install -r requirements.txt ، ثم
$ python train.pyاستخدام التحيز الموضعي الديناميكي
إضافة تكرار محسن
إعداد كتل الاهتمام المحلية، كما هو الحال في الورقة
فئة محول المجمع للتدريب
رعاية الجيل مع التكرار في RecurrentTrainWrapper
إضافة القدرة على التسرب إلى الذكريات والحالات بأكملها خلال كل خطوة مقطعية أثناء التدريب
اختبر النظام بالكامل على enwik8 محليًا وقم بإزالة الحالات والذكريات وشاهد التأثيرات مباشرة
تأكد من أن الاهتمام يسمح بمفتاح/قيم رأس واحد أيضًا
إجراء بعض التجارب على البوابات الثابتة في المحولات العادية - لا يعمل
دمج انتباه الفلاش
قناع انتباه ذاكرة التخزين المؤقت + التضمينات الدوارة
إضافة ذكريات مضغوطة
إعادة النظر في memformer
حاول توجيه ذكريات بعيدة المدى تصل إلى 250 ألفًا باستخدام النسب الإحداثي (رايت وآخرون.)
@article { Hutchins2022BlockRecurrentT ,
title = { Block-Recurrent Transformers } ,
author = { DeLesley S. Hutchins and Imanol Schlag and Yuhuai Wu and Ethan Dyer and Behnam Neyshabur } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2203.07852 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Ainslie2023CoLT5FL ,
title = { CoLT5: Faster Long-Range Transformers with Conditional Computation } ,
author = { Joshua Ainslie and Tao Lei and Michiel de Jong and Santiago Ontan'on and Siddhartha Brahma and Yury Zemlyanskiy and David Uthus and Mandy Guo and James Lee-Thorp and Yi Tay and Yun-Hsuan Sung and Sumit Sanghai } ,
year = { 2023 }
}الذاكرة هي الانتباه عبر الزمن - أليكس جريفز


