algebraic nnhw
1.0.0
يحتوي هذا المستودع على الكود المصدري لبنيات أجهزة تعلم الآلة التي تتطلب ما يقرب من نصف عدد الوحدات المضاعفة لتحقيق نفس الأداء، من خلال تنفيذ خوارزميات بديلة للمنتج الداخلي تستبدل ما يقرب من نصف المضاعفات بإضافات رخيصة ذات عرض بت منخفض، بينما لا تزال تنتج مخرجات متطابقة كمنتج داخلي تقليدي. يؤدي هذا إلى زيادة الإنتاجية النظرية وحدود كفاءة الحوسبة لمسرعات التعلم الآلي. راجع منشور المجلة التالي للحصول على التفاصيل الكاملة:
TE Pogue and N. Nicolici، "خوارزميات وهندسة المنتجات الداخلية السريعة لمسرعات الشبكات العصبية العميقة،" في معاملات IEEE على أجهزة الكمبيوتر، المجلد. 73، لا. 2، الصفحات من 495 إلى 509، فبراير 2024، دوى: 10.1109/TC.2023.3334140.
عنوان URL للمقالة: https://ieeeexplore.ieee.org/document/10323219
نسخة الوصول المفتوح: https://arxiv.org/abs/2311.12224
الملخص: نقدم خوارزمية جديدة تسمى المنتج الداخلي السريع ذو المسار الحر (FFIP) وبنية أجهزته التي تعمل على تحسين خوارزمية المنتج الداخلي السريع غير المستكشفة (FIP) التي اقترحها فينوغراد في عام 1968. على عكس خوارزميات وينوغراد ذات الحد الأدنى من التصفية غير ذات الصلة لـ الطبقات التلافيفية، ينطبق FIP على جميع طبقات نموذج التعلم الآلي (ML) التي يمكن أن تتحلل بشكل أساسي إلى مضاعفة المصفوفة، بما في ذلك الطبقات المتصلة بالكامل والتلافيفية والمتكررة والانتباه/المحولات طبقات. نقوم بتنفيذ FIP لأول مرة في مسرع ML، ثم نقدم خوارزمية FFIP والهندسة المعمارية المعممة التي تعمل بطبيعتها على تحسين تردد ساعة FIP، ونتيجة لذلك، الإنتاجية مقابل تكلفة مماثلة للأجهزة. أخيرًا، نساهم في إجراء تحسينات خاصة بالتعلم الآلي لخوارزميات وبنيات FIP وFFIP. لقد أظهرنا أنه يمكن دمج FFIP بسلاسة في مسرعات تعلم الآلة الانقباضية التقليدية ذات النقطة الثابتة لتحقيق نفس الإنتاجية بنصف عدد الوحدات المتراكمة المضاعفة (MAC)، أو يمكنه مضاعفة الحد الأقصى لحجم الصفيف الانقباضي الذي يمكن أن يتناسب مع الأجهزة ذات ميزانية الأجهزة الثابتة. يحقق تطبيق FFIP الخاص بنا لنماذج ML غير المتفرقة مع مدخلات النقطة الثابتة من 8 إلى 16 بت إنتاجية أعلى وكفاءة حوسبة مقارنة بالحلول السابقة الأفضل في فئتها على نفس النوع من النظام الأساسي للحوسبة.
يوضح الرسم البياني التالي نظرة عامة على نظام تسريع ML المطبق في كود المصدر هذا:
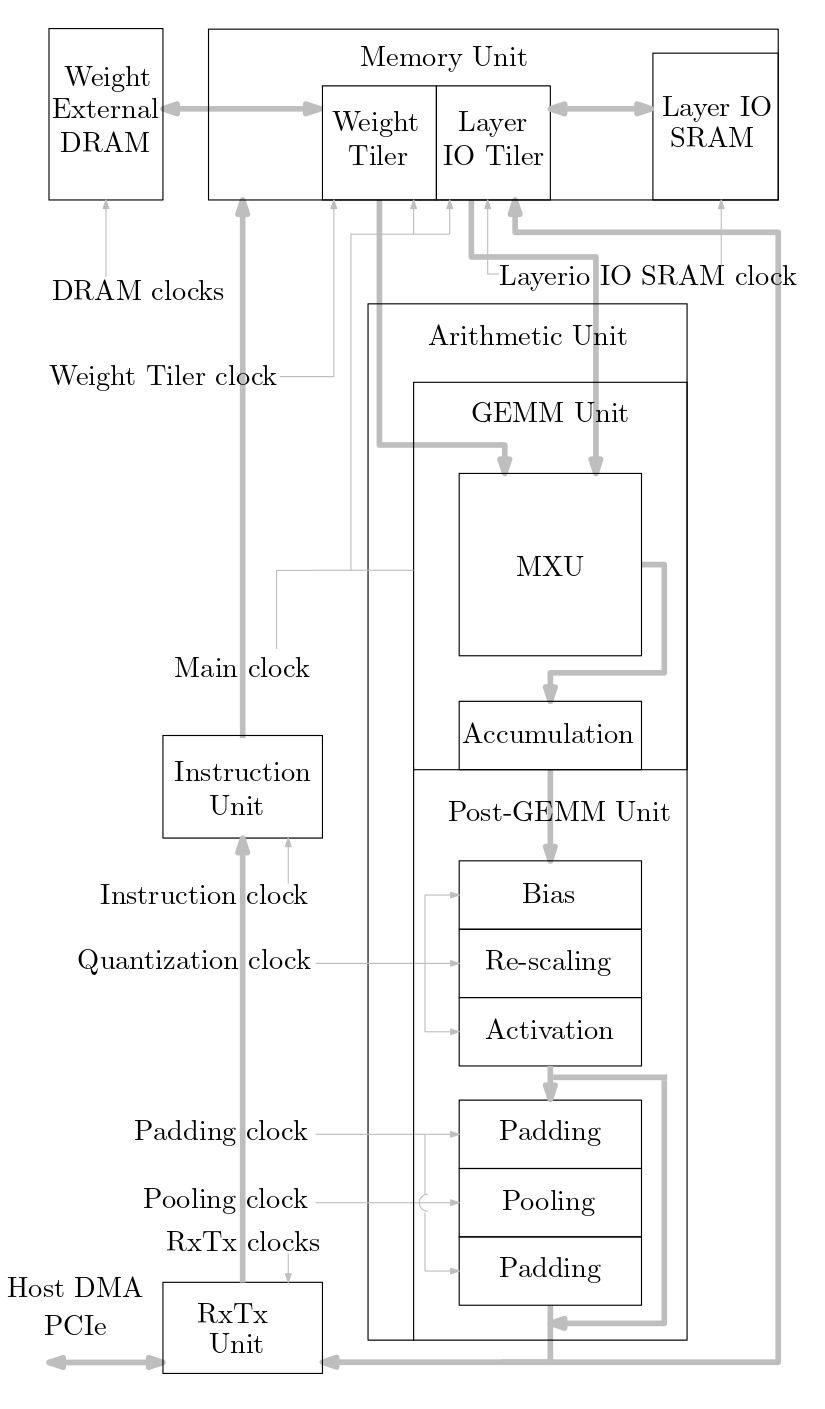
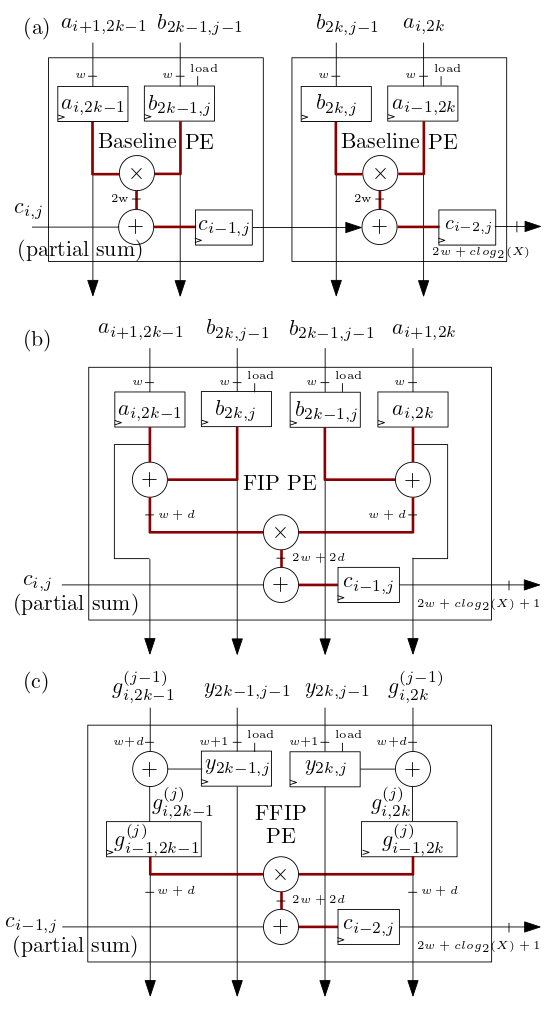
تقوم عناصر معالجة FIP وFFIP الانقباضية/عناصر معالجة MXU الموضحة أدناه في (ب) و(ج) بتنفيذ خوارزميات المنتج الداخلي FIP وFFIP ويوفر كل منها على حدة نفس القوة الحسابية الفعالة مثل عنصري PE الأساسيين الموضحين في ( أ) مجتمعة والتي تنفذ المنتج الداخلي الأساسي كما هو الحال في مسرعات تعلم الآلة ذات المصفوفة الانقباضية السابقة:
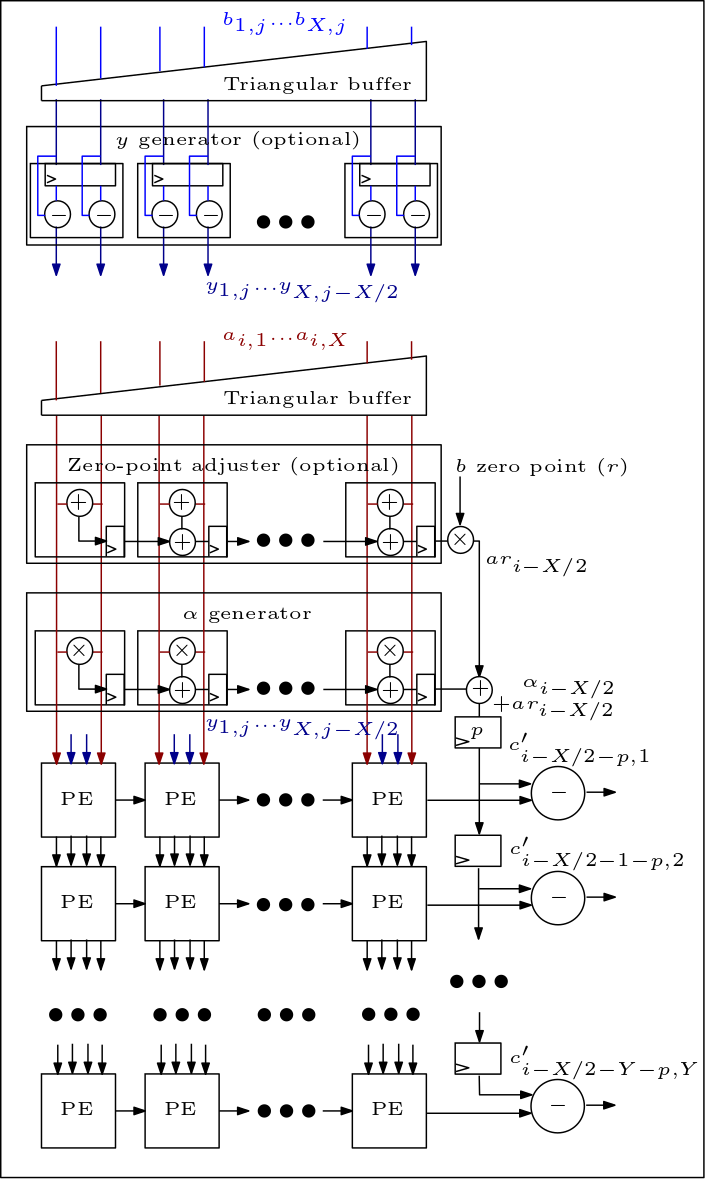
فيما يلي رسم تخطيطي لمصفوفة MXU/الانقباضية ويوضح كيفية توصيل وحدات PE:
تنظيم كود المصدر هو كما يلي:
يحتوي الملفان rtl/top/define.svh وrtl/top/pkg.sv على عدد من المعلمات القابلة للتكوين مثل FIP_METHOD في Define.svh الذي يحدد نوع المصفوفة الانقباضية (خط الأساس أو FIP أو FFIP) وSZI وSZJ التي تحدد ارتفاع/عرض المصفوفة الانقباضية، وLAYERIO_WIDTH/WEIGHT_WIDTH التي تحدد الإدخال عرض البتات.
يتضمن الدليل rtl/arith mxu.sv وmac_array.sv الذي يحتوي على RTL لخط الأساس وFIP وبنية الصفيف الانقباضي FFIP (اعتمادًا على قيمة المعلمة FIP_METHOD).


