WeClone
1.0.0
باستخدام سجلات دردشة WeChat لضبط نموذج لغة كبير، استخدمت حوالي 20000 قطعة من البيانات الفعالة المتكاملة، ولا يمكن القول إلا أن النتيجة النهائية غير مرضية، ولكنها في بعض الأحيان مضحكة حقًا.
مهم
حاليًا، يستخدم المشروع نموذج chatglm3-6b افتراضيًا، ويتم استخدام طريقة LoRA لضبط مرحلة sft، الأمر الذي يتطلب حوالي 16 جيجابايت من ذاكرة الفيديو. يمكنك أيضًا استخدام النماذج والأساليب الأخرى التي يدعمها LLaMA Factory، والتي تستهلك ذاكرة فيديو أقل. تحتاج إلى تعديل كلمات موجه النظام الخاصة بالقالب والتكوينات الأخرى ذات الصلة بنفسك.
متطلبات ذاكرة الفيديو المقدرة:
| طريقة التدريب | دقة | 7 ب | 13 ب | 30 ب | 65 ب | 8x7 ب |
|---|---|---|---|---|---|---|
| المعلمات كاملة | 16 | 160 جيجابايت | 320 جيجابايت | 600 جيجابايت | 1200 جيجابايت | 900 جيجابايت |
| بعض المعلمات | 16 | 20 جيجابايت | 40 جيجابايت | 120 جيجابايت | 240 جيجابايت | 200 جيجابايت |
| لورا | 16 | 16 جيجابايت | 32 جيجابايت | 80 جيجابايت | 160 جيجابايت | 120 جيجابايت |
| كلورا | 8 | 10 جيجابايت | 16 جيجابايت | 40 جيجابايت | 80 جيجابايت | 80 جيجابايت |
| كلورا | 4 | 6 جيجابايت | 12 جيجابايت | 24 جيجابايت | 48 جيجابايت | 32 جيجابايت |
| مطلوب | على الأقل | يوصي |
|---|---|---|
| بيثون | 3.8 | 3.10 |
| الشعلة | 1.13.1 | 2.2.1 |
| محولات | 4.37.2 | 4.38.1 |
| مجموعات البيانات | 2.14.3 | 2.17.1 |
| تسريع | 0.27.2 | 0.27.2 |
| com.peft | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| خياري | على الأقل | يوصي |
|---|---|---|
| كودا | 11.6 | 12.2 |
| com.deepspeed | 0.10.0 | 0.13.4 |
| bitsandbytes | 0.39.0 | 0.41.3 |
| فلاش عناية | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtيتم توحيد التكوينات ذات الصلة بالتدريب والاستدلال في ملف settings.json
الرجاء استخدام PyWxDump لاستخراج سجلات دردشة WeChat. بعد تنزيل البرنامج وفك تشفير قاعدة البيانات، انقر فوق Chat Backup. نوع التصدير هو CSV. يمكنك تصدير جهات اتصال متعددة أو محادثات جماعية، ثم ضع مجلد csv الذي تم تصديره والموجود في wxdump_tmp/export في دليل ./data . يتم وضع مجلدات سجلات الدردشة الخاصة بالأشخاص معًا في ./data/csv . توجد بيانات المثال في data/example_chat.csv.
بشكل افتراضي، يقوم المشروع بإزالة أرقام الهواتف المحمولة وأرقام المعرفات وعناوين البريد الإلكتروني وعناوين مواقع الويب من البيانات. كما يوفر قاعدة بيانات للكلمات المحظورة، الكلمات المحظورة، حيث يمكنك إضافة الكلمات والجمل التي تحتاج إلى تصفيتها (ستتم إزالة الجملة بأكملها بما في ذلك الكلمات المحظورة بشكل افتراضي). قم بتنفيذ البرنامج النصي ./make_dataset/csv_to_json.py لمعالجة البيانات.
عندما يجيب نفس الشخص على عدة جمل متتالية، هناك ثلاث طرق للتعامل مع الأمر:
| وثيقة | طريقة المعالجة |
|---|---|
| csv_to_json.py | تواصل مع الفواصل |
| csv_to_json-إجابة جملة مفردة (قديمة) | يتم تحديد الإجابات الأطول فقط كبيانات نهائية |
| csv_to_json-جملة واحدة متعددة rounds.py | تم وضعها في "تاريخ" الكلمة السريعة |
الخيار الأول هو تنزيل نموذج ChatGLM3 من Hugging Face. إذا واجهت مشاكل في تنزيل نموذج Hugging Face، فيمكنك استخدام مجتمع MoDELSCOPE من خلال الطرق التالية للتدريب والاستدلال اللاحق، تحتاج إلى تنفيذ export USE_MODELSCOPE_HUB=1 أولاً لاستخدام نموذج مجتمع MoDELSCOPE.
نظرًا لكبر حجم النموذج، ستستغرق عملية التنزيل وقتًا طويلاً، يرجى التحلي بالصبر.
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(اختياري) قم بتعديل settings.json لتحديد النماذج الأخرى التي تم تنزيلها محليًا.
قم بتعديل حجم per_device_train_batch_size و gradient_accumulation_steps لضبط استخدام ذاكرة الفيديو.
يمكنك تعديل المعلمات مثل num_train_epochs و lora_rank و lora_dropout وفقًا لكمية ونوعية مجموعة البيانات الخاصة بك.
قم بتشغيل src/train_sft.py لضبط مرحلة sft، حيث انخفضت خسارتي إلى حوالي 3.5 فقط. إذا تم تقليلها كثيرًا، فقد يتسبب ذلك في الإفراط في الملاءمة.
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.pyملحوظة
يمكنك أيضًا ضبط مرحلة pt أولاً. يبدو أن تأثير التحسين غير واضح. يوفر المستودع أيضًا رمزًا للمعالجة المسبقة لمجموعة بيانات مرحلة pt.
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.pyمهم
هناك خطر إغلاق الحساب على WeChat. يوصى باستخدام حساب صغير ويجب ربط بطاقة مصرفية لاستخدامه.
python ./src/api_service.py # 先启动api服务
python ./src/wechat_bot/main.py بشكل افتراضي، يتم عرض رمز الاستجابة السريعة على الجهاز، ما عليك سوى مسح الرمز ضوئيًا لتسجيل الدخول. ويمكن استخدامه في الدردشة الخاصة أو في الدردشة الجماعية @bot.
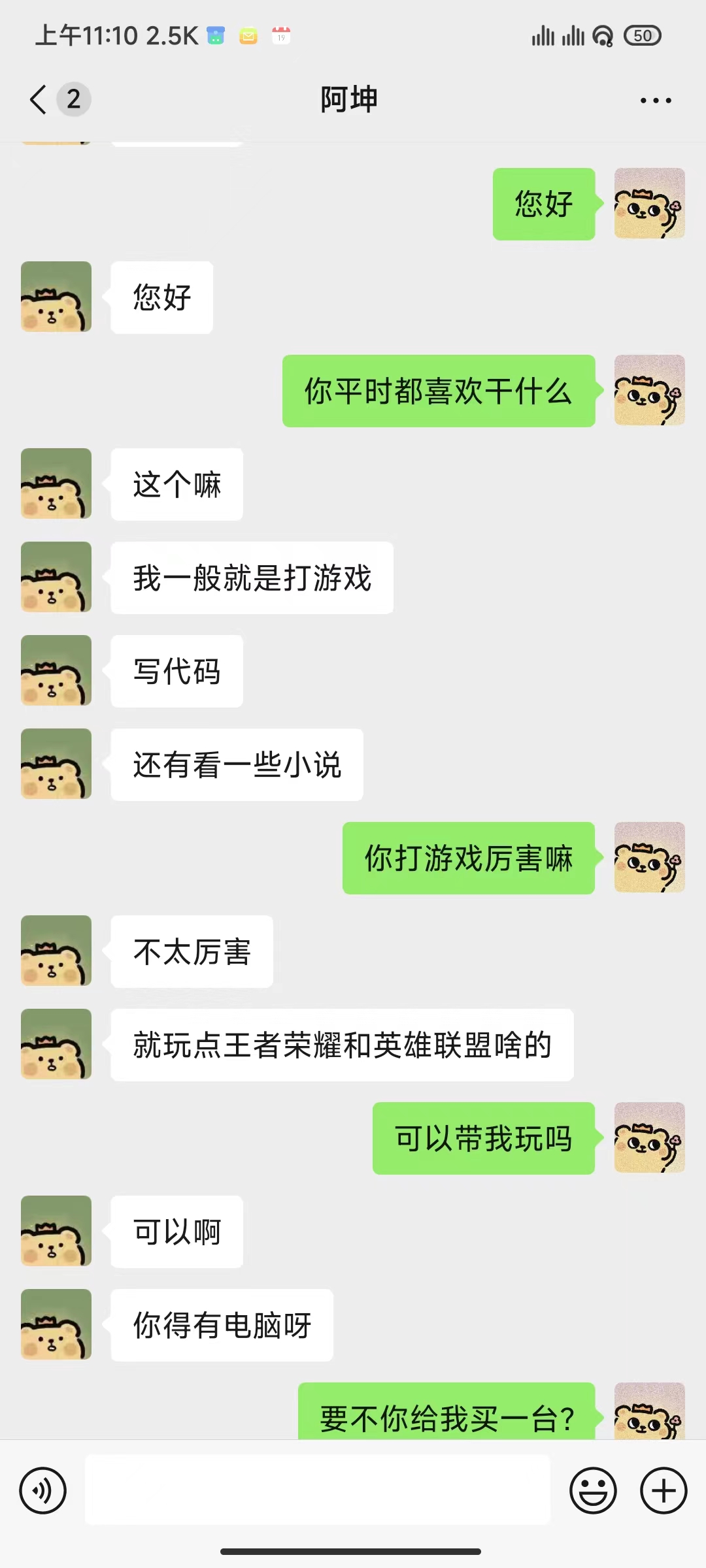

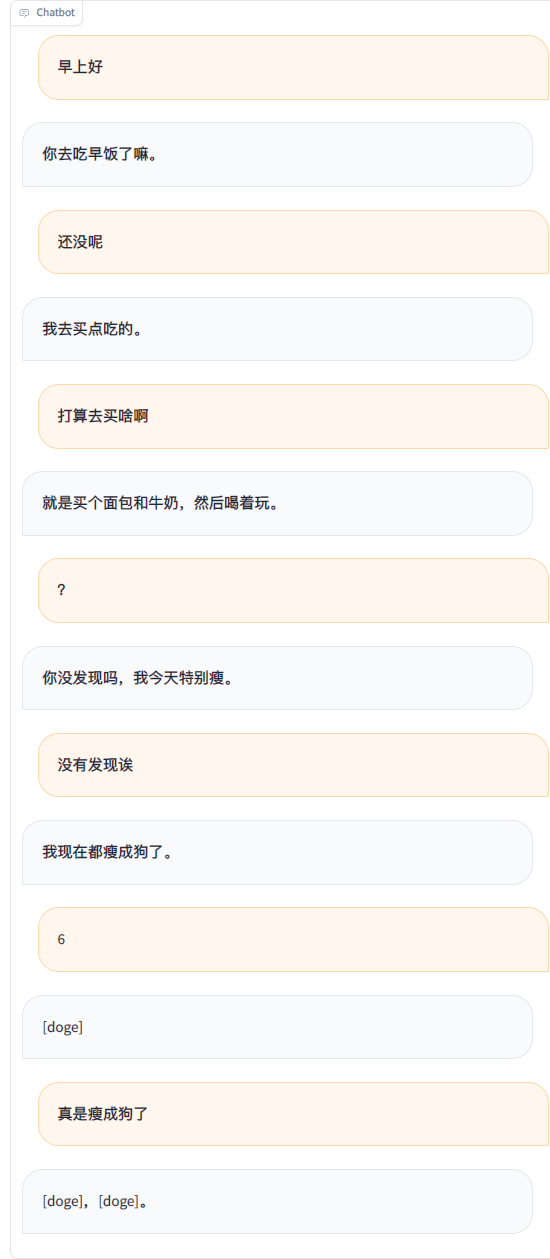
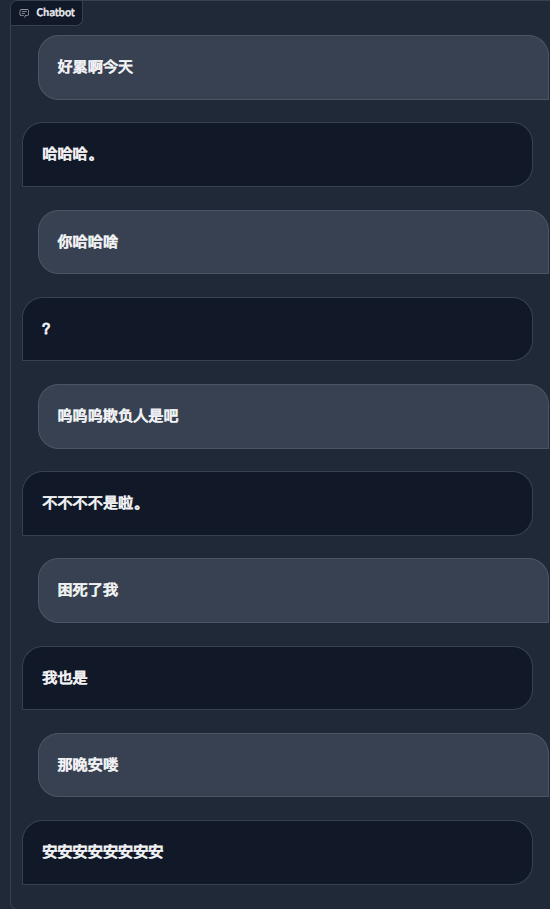
ما يجب القيام به
ما يجب القيام به


