whisper.cpp
v1.7.2
مستقر: v1.7.2 / طريق الطريق | التعليمات
الاستدلال عالي الأداء لنموذج التعرف على الكلام التلقائي في Openai (ASR):
المنصات المدعومة:
يتم تضمين تطبيق كامل المستوى للنموذج في Whisper.h و Whisper.cpp. ما تبقى من الكود جزء من مكتبة التعلم الآلي ggml .
يتيح وجود مثل هذا التنفيذ الخفيف للنموذج دمجه بسهولة في منصات وتطبيقات مختلفة. على سبيل المثال ، إليك مقطع فيديو لتشغيل النموذج على جهاز iPhone 13 - غير متصل تمامًا ، على الجهاز: whisper.objc
يمكنك أيضًا عمل تطبيق مساعد الصوت الخاص بك بسهولة: أمر
على سيليكون التفاح ، يعمل الاستدلال بالكامل على وحدة معالجة الرسومات عبر المعادن:
أو يمكنك حتى تشغيله مباشرة في المتصفح: Talk.wasm
يتم تحسين مشغلي الموتر بشكل كبير لوحدة المعالجة المركزية للسيليكون Apple. اعتمادًا على حجم الحساب ، يتم استخدام روتينات الإطار الإطارية لـ CBLAS ARM NEON SIMD. هذا الأخير فعال بشكل خاص للأحجام الأكبر لأن إطار التسريع يستخدم المعالجات المشتركة AMX ذات الأغراض الخاصة المتاحة في منتجات Apple الحديثة.
أول استنساخ المستودع:
git clone https://github.com/ggerganov/whisper.cpp.gitانتقل إلى الدليل:
cd whisper.cpp
ثم ، قم بتنزيل أحد طرز الهمس التي تم تحويلها بتنسيق ggml . على سبيل المثال:
sh ./models/download-ggml-model.sh base.enقم الآن ببناء المثال الرئيسي ونسخ ملف صوتي مثل هذا:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav للحصول على عرض سريع ، ما عليك سوى تشغيل make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
يقوم الأمر بتنزيل نموذج base.en الذي تم تحويله إلى تنسيق ggml مخصص ويقوم بتشغيل الاستدلال على جميع عينات .wav في samples المجلد.
للحصول على تعليمات الاستخدام التفصيلية ، قم بتشغيل: ./main -h
لاحظ أن المثال الرئيسي يعمل حاليًا فقط مع ملفات WAV 16 بت ، لذا تأكد من تحويل الإدخال الخاص بك قبل تشغيل الأداة. على سبيل المثال ، يمكنك استخدام ffmpeg مثل هذا:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavإذا كنت تريد أن تلعب بعض عينات الصوت الإضافية ، فما عليك سوى التشغيل:
make -j samples
سيؤدي ذلك إلى تنزيل عدد قليل من الملفات الصوتية من Wikipedia وتحويلها إلى تنسيق WAV 16 بت عبر ffmpeg .
يمكنك تنزيل وتشغيل النماذج الأخرى على النحو التالي:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| نموذج | القرص | ميم |
|---|---|---|
| صغير الحجم | 75 MIB | ~ 273 ميغابايت |
| قاعدة | 142 MIB | ~ 388 ميغابايت |
| صغير | 466 MIB | ~ 852 ميغابايت |
| واسطة | 1.5 جيب | ~ 2.1 غيغابايت |
| كبير | 2.9 جيب | ~ 3.9 جيجابايت |
whisper.cpp يدعم تقدير عدد صحيح لنماذج ggml الهامس. تتطلب النماذج الكمية مساحة أقل للذاكرة ومساحة القرص واعتمادًا على الأجهزة يمكن معالجتها بشكل أكثر كفاءة.
فيما يلي خطوات إنشاء نموذج كمي واستخدامه:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav على أجهزة Apple Silicon ، يمكن تنفيذ استدلال التشفير على محرك Apple العصبي (ANE) عبر Core ML. يمكن أن يؤدي ذلك إلى تسريع كبير-أكثر من x3 أسرع مقارنة مع تنفيذ وحدة المعالجة المركزية فقط. فيما يلي التعليمات لإنشاء نموذج ML الأساسي واستخدامه مع whisper.cpp :
تثبيت تبعيات Python اللازمة لإنشاء نموذج ML الأساسي:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools بشكل صحيح ، يرجى تأكيد أن Xcode مثبت وتنفيذ xcode-select --install لتثبيت أدوات سطر الأوامر.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper توليد نموذج ML الأساسي. على سبيل المثال ، لإنشاء نموذج. base.en ، استخدم:
./models/generate-coreml-model.sh base.en سيؤدي ذلك إلى إنشاء models/ggml-base.en-encoder.mlmodelc
بناء whisper.cpp مع دعم Core ML:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config Releaseتشغيل الأمثلة كالمعتاد. على سبيل المثال:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
يكون التشغيل الأول على الجهاز بطيئًا ، نظرًا لأن خدمة ANE تجمع طراز ML الأساسي إلى تنسيق خاص بالجهاز. أشواط التالية أسرع.
لمزيد من المعلومات حول تطبيق ML الأساسي ، يرجى الرجوع إلى PR #566.
على المنصات التي تدعم Openvino ، يمكن تنفيذ استدلال التشفير على الأجهزة المدعومة من Openvino بما في ذلك وحدات المعالجة المركزية X86 و Intel وحدات معالجة الرسومات (المتكاملة والمنفصلة).
هذا يمكن أن يؤدي إلى تسريع كبير في أداء التشفير. فيما يلي التعليمات لإنشاء نموذج OpenVino واستخدامه مع whisper.cpp :
أولاً ، إعداد بيثون الظاهري ENV. وتثبيت تبعيات بيثون. ينصح بيثون 3.10.
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux و MacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt توليد نموذج تشفير Openvino. على سبيل المثال ، لإنشاء نموذج. base.en ، استخدم:
python convert-whisper-to-openvino.py --model base.en
سيؤدي ذلك إلى إنتاج ملفات نموذج GGML-base.en-encoder-Openvino.xml/.bin IR. يوصى بنقلها إلى نفس المجلد مثل نماذج ggml ، لأن هذا هو الموقع الافتراضي الذي سيبحثه امتداد OpenVino في وقت التشغيل.
بناء whisper.cpp مع دعم Openvino:
قم بتنزيل حزمة OpenVino من صفحة الإصدار. الإصدار الموصى به لاستخدامه هو 2023.0.0.
بعد تنزيل الحزمة واستخراجها على نظام التطوير الخاص بك ، قم بإعداد البيئة المطلوبة عن طريق الحصول على برنامج SetupVars Script. على سبيل المثال:
لينكس:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batثم بناء المشروع باستخدام CMake:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config Releaseتشغيل الأمثلة كالمعتاد. على سبيل المثال:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
أول مرة على جهاز Openvino بطيئة ، لأن إطار OpenVino سيقوم بتجميع نموذج IR (التمثيل المتوسط) إلى "Blob" الخاص بالجهاز. سيتم تخزين هذا النقطة الخاصة بالجهاز للتخزين المؤقت للتشغيل التالي.
لمزيد من المعلومات حول تطبيق ML الأساسي ، يرجى الرجوع إلى PR #1037.
مع بطاقات NVIDIA ، تتم معالجة النماذج بكفاءة على وحدة معالجة الرسومات عبر Cublas و Cuda Juda. أولاً ، تأكد من تثبيت cuda : https://developer.nvidia.com/cuda-downloads
الآن قم ببناء whisper.cpp مع دعم CUDA:
make clean
GGML_CUDA=1 make -j
حل البائع الذي يسمح لك بتسريع عبء العمل على وحدة معالجة الرسومات الخاصة بك. أولاً ، تأكد من أن برنامج تشغيل بطاقة الرسومات الخاص بك يوفر الدعم لـ Vulkan API.
الآن قم ببناء whisper.cpp بدعم Vulkan:
make clean
make GGML_VULKAN=1 -j
يمكن تسريع معالجة التشفير على وحدة المعالجة المركزية عبر OpenBlas. أولاً ، تأكد من تثبيت openblas : https://www.openblas.net/
الآن بناء whisper.cpp مع دعم OpenBlas:
make clean
GGML_OPENBLAS=1 make -j
يمكن تسريع معالجة التشفير على وحدة المعالجة المركزية عبر الواجهة المتوافقة مع BLAS لمكتبة Kernel Math's Intel. أولاً ، تأكد من تثبيت حزم Runting MKL والتطوير من Intel:
الآن قم ببناء whisper.cpp مع دعم Intel MKL Blas:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
يوفر Ascend NPU تسارع الاستدلال عبر CANN و AI Cores.
أولاً ، تحقق مما إذا كان جهاز Ascend NPU مدعومًا:
الأجهزة التي تم التحقق منها
| صعود NPU | حالة |
|---|---|
| أطلس 300T A2 | يدعم |
ثم ، تأكد من تثبيت CANN toolkit . يتم التوصية النسخة المستمرة من Cann.
الآن قم ببناء whisper.cpp بدعم CAN:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
قم بتشغيل أمثلة الاستدلال كالمعتاد ، على سبيل المثال:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
ملحوظات:
Verified devices الجدول. لدينا صورتان من Docker متاحين لهذا المشروع:
ghcr.io/ggerganov/whisper.cpp:main : تتضمن هذه الصورة الملف القابل للتنفيذ الرئيسي وكذلك curl و ffmpeg . (المنصات: linux/amd64 ، linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : مثل main ولكن تم تجميعه مع دعم CUDA. (المنصات: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " يمكنك تثبيت ثنائيات تم إنشاؤها مسبقًا لـ Whisper.cpp أو إنشاءها من المصدر باستخدام Conan. استخدم الأمر التالي:
conan install --requires="whisper-cpp/[*]" --build=missing
للحصول على إرشادات مفصلة حول كيفية استخدام كونان ، يرجى الرجوع إلى وثائق كونان.
فيما يلي مثال آخر على نسخ خطاب 3:24 دقيقة في حوالي نصف دقيقة على جهاز MacBook M1 Pro ، باستخدام نموذج medium.en .
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
هذا مثال ساذج لأداء الاستدلال في الوقت الفعلي على الصوت من الميكروفون الخاص بك. تقوم أداة الدفق بتأييد الصوت كل نصف ثانية وتشغيل النسخ بشكل مستمر. مزيد من المعلومات متاح في العدد رقم 10.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 ستطبع إضافة وسيطة --print-colors الطباعة النص المكتوب باستخدام استراتيجية ترميز الألوان التجريبية لتسليط الضوء على الكلمات بثقة عالية أو منخفضة:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors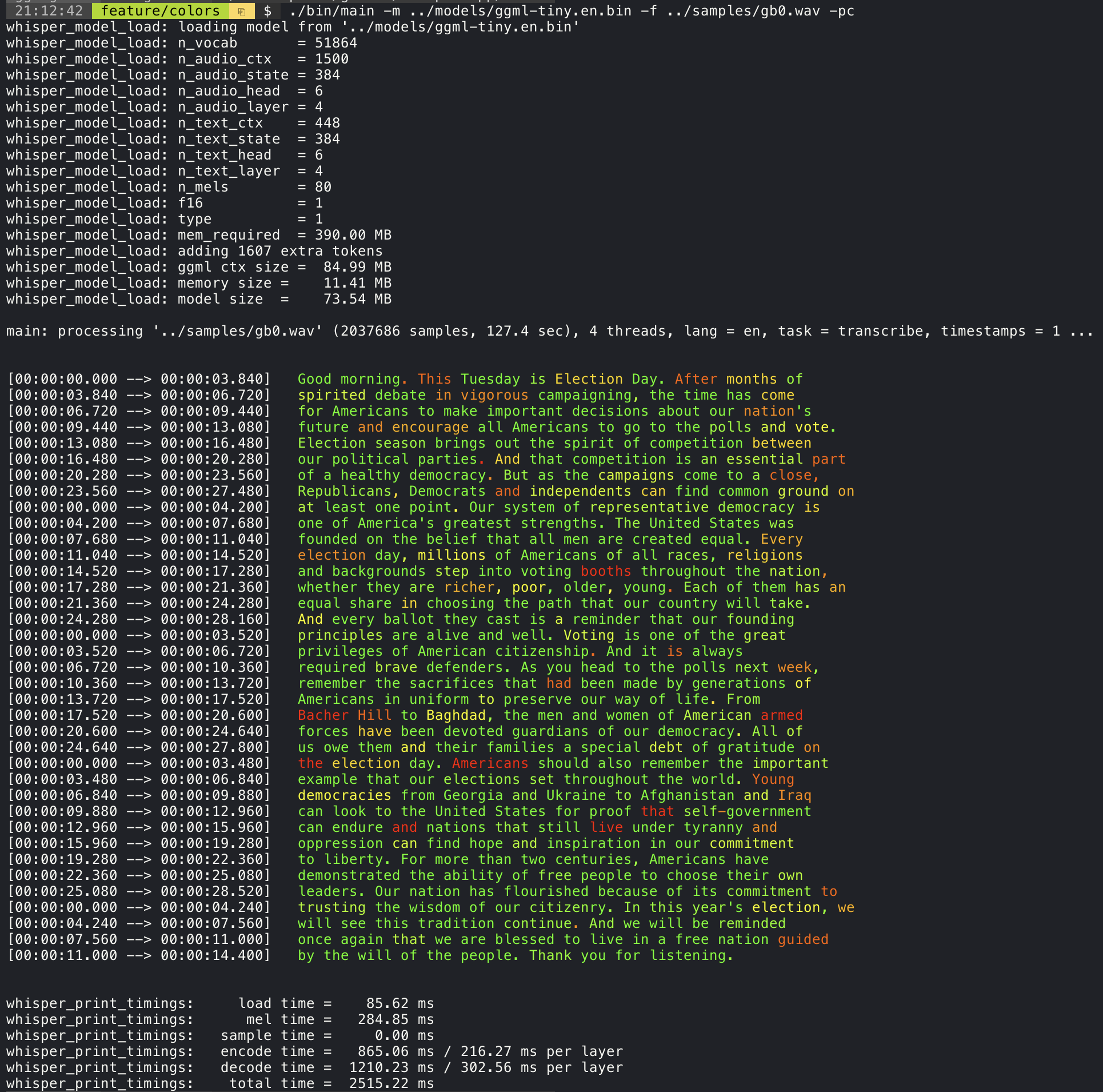
على سبيل المثال ، للحد من طول الخط إلى 16 حرفًا كحد أقصى ، ما عليك سوى إضافة -ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
يمكن استخدام وسيطة-- --max-len للحصول على الطوابع الزمنية على مستوى الكلمات. ببساطة استخدم -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
مزيد من المعلومات حول هذا النهج متاح هنا: #1058
استخدام العينة:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . يوفر المثال الرئيسي دعمًا لإخراج أفلام على طراز الكاريوكي ، حيث يتم تسليط الضوء على الكلمة الواضحة حاليًا. استخدم وسيطة -wts وقم بتشغيل البرنامج النصي الذي تم إنشاؤه. هذا يتطلب تثبيت ffmpeg .
فيما يلي بعض الأمثلة "النموذجية" :
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4استخدم نص البرامج النصية/مقعد wts.sh لإنشاء مقطع فيديو بالتنسيق التالي:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4من أجل الحصول على مقارنة موضوعية لأداء الاستدلال عبر تكوينات النظام المختلفة ، استخدم أداة المقعد. تقوم الأداة ببساطة بتشغيل جزء التشفير من النموذج وتطبع مقدار الوقت الذي استغرقته لتنفيذه. تم تلخيص النتائج في قضية جيثب التالية:
النتائج القياسية
بالإضافة إلى ذلك ، يتم توفير برنامج نصي لتشغيل Whisper.cpp مع نماذج مختلفة وملفات صوتية.
يمكنك تشغيله باستخدام الأمر التالي ، بشكل افتراضي ، سيتم تشغيله مقابل أي نموذج قياسي في مجلد النماذج.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2إنه مكتوب في Python بقصد أن تكون سهلة التعديل والتمديد لحالة الاستخدام القياسية الخاصة بك.
يخرج ملف CSV مع نتائج القياس.
ggmlيتم تحويل النماذج الأصلية إلى تنسيق ثنائي مخصص. هذا يسمح لحزم كل ما هو مطلوب في ملف واحد:
يمكنك تنزيل النماذج المحولة باستخدام النماذج/التنزيل -ggml-model.sh أو يدويًا من هنا:
لمزيد من التفاصيل ، راجع نماذج برنامج التحويل/تحويل PT-PT إلى ggml.py أو النماذج/README.MD.
هناك العديد من الأمثلة على استخدام المكتبة لمشاريع مختلفة في مجلد الأمثلة. حتى يتم نقل بعض الأمثلة لتشغيلها في المتصفح باستخدام Webassembly. تحقق منها!
| مثال | الويب | وصف |
|---|---|---|
| رئيسي | الهمس | أداة لترجمة الصوت ونسخه باستخدام الهمس |
| مقعد | مقعد | معيار أداء الهمس على جهازك |
| تدفق | دفق | النسخ في الوقت الحقيقي لالتقاط الميكروفون الخام |
| يأمر | command.wasm | مثال مساعد صوتي أساسي لتلقي الأوامر الصوتية من الميكروفون |
| WCHESS | wchess.wasm | الشطرنج التي تسيطر عليها الصوت |
| يتحدث | Talk.Wasm | تحدث مع روبوت GPT-2 |
| الحديث بلاما | تحدث مع روبوت لاما | |
| Whisper.Objc | تطبيق iOS للجوال باستخدام Whisper.cpp | |
| Whisper.Swiftui | تطبيق Swiftui IOS / MacOS باستخدام Whisper.cpp | |
| Whisper.android | تطبيق Android Mobile باستخدام Whisper.cpp | |
| Whisper.nvim | المكون الإضافي للكلام إلى النص لـ Neovim | |
| توليد karaoke.sh | البرنامج النصي المساعد لإنشاء مقطع فيديو للكاريوكي بسهولة لالتقاط الصوت الخام | |
| Livestream.sh | النسخ الصوتي للبث | |
| yt-wsp.sh | تنزيل + نسخ و/أو ترجمة أي VOD (الأصلي) | |
| الخادم | خادم النسخ HTTP مع واجهة برمجة تطبيقات تشبه OAI |
إذا كان لديك أي نوع من التعليقات حول هذا المشروع ، فلا تتردد في استخدام قسم المناقشات وفتح موضوع جديد. يمكنك استخدام المعرض وإخبار الفئة لمشاركة مشاريعك الخاصة التي تستخدم whisper.cpp . إذا كان لديك سؤال ، فتأكد من التحقق من مناقشة الأسئلة المتداولة (#126).


