نظرًا لأن ظهور نموذج اللغة الكبير (LLM) يمثله ChatGPT ، نظرًا لقدرته المذهلة للذكاء الاصطناعي الشامل للأغراض العامة (AGI) ، فقد بدأ موجة من البحث والتطبيق في مجال معالجة اللغة الطبيعية. خاصة بعد المصدر المفتوح LLM الصغير الذي يمكن أن يركض مع ChatGLM و LLAMA واللاعبين المدنيين الآخرين ، هناك العديد من حالات تعديلها أو تطبيقات قائمة على LLM بناءً على LLM. يهدف هذا المشروع إلى جمع وفرز النماذج المفتوحة المصدر والتطبيقات ومجموعات البيانات والبرامج التعليمية المتعلقة بـ LLM الصينية.
إذا كان هذا المشروع يمكن أن يجلب لك القليل من المساعدة ، فيرجى السماح لي قليلاً ~
في الوقت نفسه ، نرحب أيضًا بالمساهمة في نماذج المصادر المفتوحة غير الشعبية والتطبيقات ومجموعات البيانات وما إلى ذلك من هذا المشروع. تقديم معلومات مستودعات جديدة ، يرجى بدء العلاقات العامة ، وتقديم معلومات ذات صلة مثل روابط المستودعات وأرقام النجوم والملفات الشخصية والمعلومات الإحاطة والمعلومات ذات الصلة وفقًا لتنسيق هذا المشروع
نظرة عامة على نموذج الأساس الشائع:
قاعدة
تضمين نموذج
حجم المعلمة النموذج
رقم الرمز المميز
الحد الأقصى للتدريب
سواء للتسويق
ChatGlm
chatglm/2/3/4 قاعدة ودردشة
6 ب
1T/1.4
2K/32K
الاستخدام التجاري
لاما
لاما/2/3 قاعدة ودردشة
7b/8b/13b/33b/70b
1T/2T
2K/4K
تجاري جزئيا
بايتشوان
Baichuan/2 قاعدة ودردشة
7B/13B
1.2T/1.4T
4K
الاستخدام التجاري
Qwen
Qwen/1.5/2/2.5 قاعدة ودردشة و VL
7b/14b/32b/72b/110b
2.2T/3T/18T
8k/32k
الاستخدام التجاري
يزدهر
يزدهر
1B/7B/176B-MT
1.5T
2K
الاستخدام التجاري
أكويلا
أكويلا/2 قاعدة/دردشة
7B/34B
-
2K
الاستخدام التجاري
إنترنت
إنترنت
7B/20B
-
200k
الاستخدام التجاري
mixtrac
قاعدة ودردشة
8x7b
-
32 كيلو
الاستخدام التجاري
نعم
قاعدة ودردشة
6b/9b/34b
3T
200k
الاستخدام التجاري
ديبسيك
قاعدة ودردشة
1.3b/7b/33b/67b
-
4K
الاستخدام التجاري
xverse
قاعدة ودردشة
7b/13b/65b/a4.2b
2.6t/3.2t
8k/16k/256k
الاستخدام التجاري
جدول المحتويات
جدول المحتويات
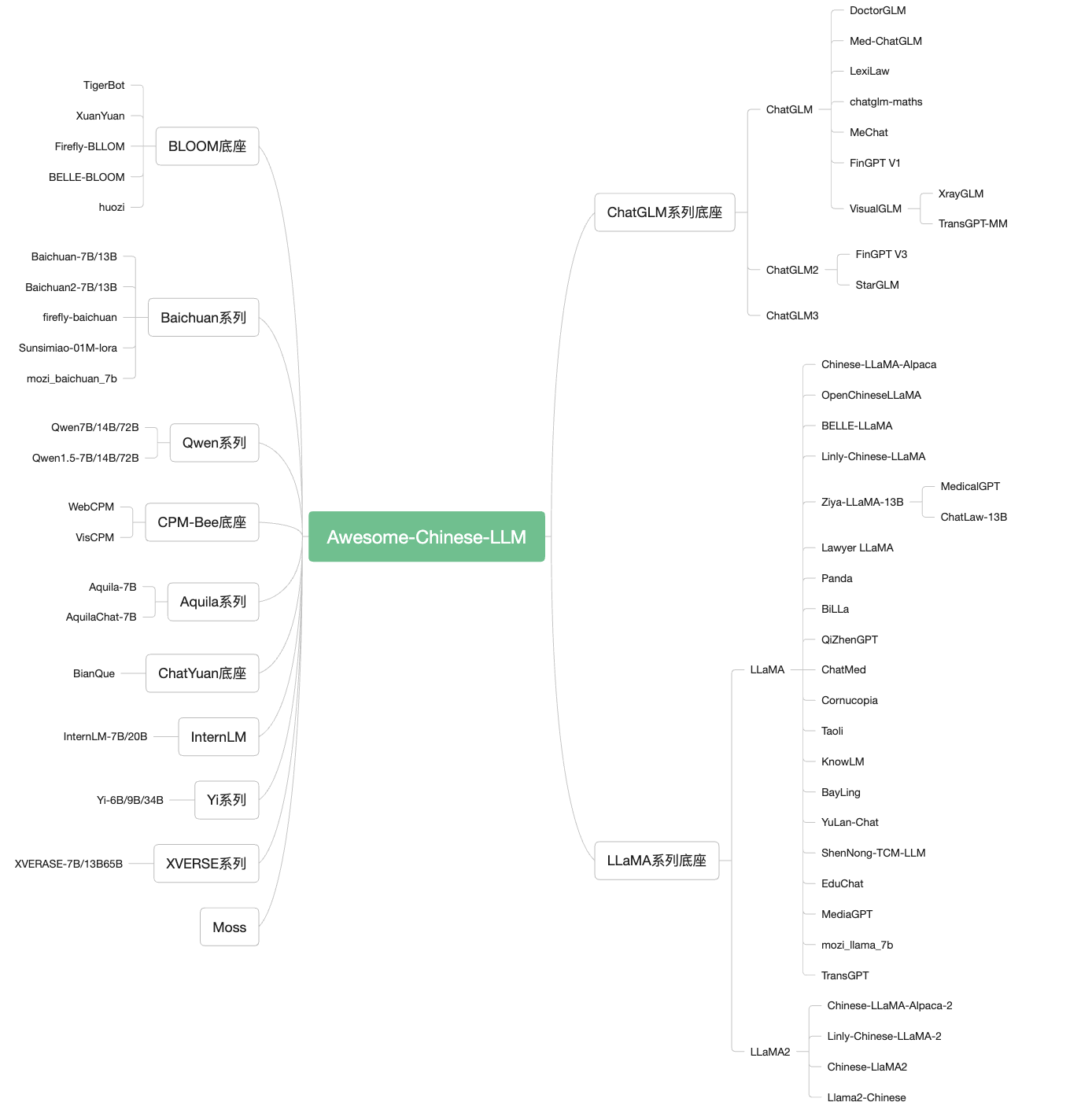
1. نموذج
1.1 Text LLM Model
1.2 نموذج Multifamily LLM
2. التطبيق
2.1 التصفية في الحقل العمودي
الرعاية الطبية
قانون
تمويل
تثقيف
العلوم والتكنولوجيا
e -الشجاعة
أمان الشبكة
زراعة
2.2 تطبيق Langchain
2.3 التطبيقات الأخرى
3. مجموعة البيانات
مجموعة بيانات ما قبل التدريب
مجموعة بيانات SFT
مجموعة بيانات التفضيل
4. LLM تدريب غرامة إطار عمل
5. إطار نشر المنطق LLM
6. تقييم LLM
7. LLM البرنامج التعليمي
LLM المعرفة الأساسية
دفع تعليمي الهندسة
LLM تطبيق البرنامج التعليمي
LLM البرنامج التعليمي القتالي الفعلي
8. المستودع ذات الصلة
تاريخ النجوم
1. نموذج
1.1 Text LLM Model
ChatGlm:
العنوان: https://github.com/thudm/chatglm-6b
مقدمة: أحد أكثر طرز قاعدة المصدر المفتوحة فعالية في الحقل الصيني ، تحسين الأسئلة والأجوبة الصينية والحوار. بعد تدريب ثنائي اللغة لحوالي 1T ، تستكمل تقنيات مثل الإشراف على الراحة والتعليقات والتعليقات من التعليقات البشرية لتعزيز التعلم
ChatGlm2-6b
العنوان: https://github.com/thudm/chatglm2-6b
مقدمة: استنادًا إلى إصدار الجيل الثاني من نموذج الحوار الصيني والإنجليزي المفتوح ، فقد قدمت وظيفة GLM الهجينة على أساس الحوار النموذجية المحفوظة وعتبات النشر المنخفضة ، والتي تم الاحتفاظ بها -توسع رموز التعريف البريطانية في T ومواءمة التفضيلات البشرية ؛ الاستخدام التجاري.
ChatGlm3-6b
العنوان: https://github.com/thudm/chatglm3
مقدمة: chatglm3-6b هو نموذج مفتوح المصدر في سلسلة chatglm3 : يستخدم ChatGlm3- 6B النموذج الأساسي ChatGlm3-6b المزيد من بيانات التدريب ، وخطوات التدريب الكاملة ، واستراتيجيات تدريب أكثر معقولة ؛同时原生支持工具调用 (استدعاء الوظيفة) ((مترجم رمز) 和 الوكيل : : : chatglm3-6b 外 还开源了基础模型 at chatglm3-6b-base 、长文本نموذج الحوار chatglm3-6b-32k. الوزن أعلاه مفتوح تمامًا للبحث الأكاديمي ، ويسمح أيضًا بالاستخدام التجاري المجاني بعد ملء الاستبيان.
GLM-4
العنوان: https://github.com/thudm/glm-4
مقدمة موجزة: GLM-4-9B هو الإصدار المفتوح المصدر من أحدث طراز الجيل قبل التدريب الذي أطلقته Smart Spectrum AI. في تقييم مجموعات البيانات مثل الدلالات ، والرياضيات ، والمنطق ، والرمز ، والمعرفة ، فإن GLM-4-9B وإصدارها التفضيلي البشري من GLM-4-9B الكل بالإضافة إلى جولات متعددة من الحوار ، يحتوي GLM-4-9B-Chat أيضًا على وظائف متقدمة مثل تصفح الويب وتنفيذ التعليمات البرمجية واتصال الأدوات المخصصة (استدعاء الوظيفة) والتفكير النصفي الطويل (دعم سياق 128K القصوى). أضاف هذا الجيل دعمًا متعدد اللغة ، ودعم 26 لغة بما في ذلك اليابانية والكورية والألمانية. أطلقنا أيضًا طرز GLM-4-9B-CHAT-1M التي تدعم طولها 1 مترًا للسياق (حوالي 2 مليون حرف صيني) ونماذج GLM-4V-9B على أساس GLM-4-9B. GLM-4V-9B لديه قدرة حوار متعددة اللغات متعددة اللغات تحت الدقة العالية من 1120 * 1120. في العديد من جوانب التقييم متعدد الوسائط مثل القدرة الصينية والإنجليزية الشاملة ، التفكير الإدراك ، التعرف على النص ، فهم المخطط ، GLM-4V -9b تعبر عن الأداء الممتاز المتمثل في تجاوز GPT-4-Turbo-2024-04-09 و Gemini 1.0 Pro و Qwen-VL-Max و Claude 3 Opus.
QWEN/QWEN1.5/QWEN2/QWEN2.5
العنوان: https://github.com/qwenlm
مقدمة: Tongyi Qianwen هي سلسلة من النماذج من نموذج Tongyi Qianwen الذي طورته Cloud Alibaba ، بما في ذلك مقياس المعلمة 1.8 مليار (1.8B) ، 7 مليارات (7 ب) ، 14 مليار (14 ب) ، 72 مليار (72 ب) ، 1100 و 1100 و 1100 و 1100 1100 100 مليون (110 ب). تتضمن نماذج كل مقياس الطراز الأساسي Qwen ونموذج الحوار. تتضمن مجموعات البيانات مجموعة متنوعة من البيانات مثل الحقل العام والمحترفين. استدعاء القابس بشكل فعال وترقية إلى جوهر الوكيل
مقدمة: أصدرت شركة Shangtang Technology ، ومختبر شنغهاي AI والجامعة الصينية في هونغ كونغ ، وجامعة فودان ، وجامعة شنغهاي جياوتونغ ، نموذج اللغة الكبير البالغة 100 مليار ". وتفيد التقارير أن "Scholar PU" لديه 104 مليار معلمة ، ويتم تدريبه على أساس "مجموعة بيانات عالية الجودة متعددة اللغات التي تحتوي على 1.6 تريليون رمز".
إنترنت
العنوان: https://github.com/internlm/internlm
مقدمة: أصدرت شركة Shangtang Technology ، ومختبر شنغهاي AI ، والجامعة الصينية في هونغ كونغ ، وجامعة فودان ، وجامعة شنغهاي جياوتونغ نموذج اللغة الكبيرة 100 مليار "internlm2". حقق Internlm2 تقدمًا كبيرًا في الرقمية والرمز والحوار والإنشاء ، وقد وصل الأداء الشامل إلى المستوى الرئيسي لنموذج المصدر المفتوح. يحتوي InternLM2 على نموذجين: 7B و 20B. يوفر 7B نموذجًا خفيف الوزن ولكنه فريد من نوعه للبحث عن الوزن الخفيف.
مقدمة: نموذج لغوي كبير قبل التدريب الذي طوره التطور الذكي Baichuan. استنادًا إلى بنية المحولات ، يدعم نموذج المعلمة الذي يبلغ طوله 7 مليارات من الرموز المميزة التي تبلغ مساحتها حوالي 1.2 تريليون رموز اللغة الصينية والإنجليزية ، وطول نافذة السياق 4096. كل من المعيار القياسي للسلطة الصينية والإنجليزية (C-eval/mmlu) له أفضل تأثير من نفس الحجم.
مقدمة: Baichuan-13B هو نموذج لغة واسع النطاق يحتوي على 13 مليار معلمة بعد Baichuan-7B بعد Baichuan-7B. ينشر المشروع نسختين: Baichuan-13B-Base و Baichuan-13B-Chat.
مقدمة: يستخدم الجيل الجديد من نموذج اللغة المفتوح المصدر الذي تم إطلاقه بواسطة Baichuan Intelligence 2.6 تريليون رموز للتدريب مع مجموعة عالية الجودة. .
xverse-7b
العنوان: https://github.com/xverse- ai/xverse-7b
مقدمة: يدعم نموذج اللغة الكبيرة التي تدعمها تقنية Shenzhen Yuanxiang نماذج متعددة اللغات ، ويدعم طول سياق 8K ، ويستخدم بيانات عالية الجودة ومتنوعة تبلغ 2.6 تريليون رمز لتدريب النموذج. روسيا ، والغربية. ويتضمن أيضًا نماذج من الإصدارات الكمية GGUF و GPTQ ، والتي تدعم التفكير في llama.cpp و VLLM على نظام MacOS/Linux/Windows.
xverse-13b
العنوان: https://github.com/xverse- ai/xverse-13b
مقدمة: نماذج اللغة الكبيرة التي تدعمها تقنية Shenzhen Yuanxiang التي تدعم نماذج متعددة اللغات ، ودعم طول سياق 8K (طول السياق) ، واستخدام بيانات عالية الجودة ومتنوعة تبلغ 3.2 تريليون لتدريب النموذج بالكامل. كما بريطانيا وروسيا والغربية. بما في ذلك نموذج الحوار التسلسل الطويل Xverse-13B-256K. ويتضمن أيضًا نماذج من الإصدارات الكمية GGUF و GPTQ ، والتي تدعم التفكير في llama.cpp و VLLM على نظام MacOS/Linux/Windows.
xverse-65b
العنوان: https://github.com/xverse- ai/xverse-65b
مقدمة: يدعم نموذج اللغة الكبيرة التي تدعمها تقنية Shenzhen Yuanxiang نموذجًا متعدد اللغات ، ويدعم طول السياق 16 ألفًا ، ويستخدم بيانات عالية الجودة ومتنوعة تبلغ 2.6 تريليون لتدريب النموذج لتدريب النموذج بالكامل لغات مثل بريطانيا وروسيا والغربية. بما في ذلك نموذج Xverse-65B-2 التدريجي قبل التدريب مع تدريب تدريجي. ويتضمن أيضًا نماذج من الإصدارات الكمية GGUF و GPTQ ، والتي تدعم التفكير في llama.cpp و VLLM على نظام MacOS/Linux/Windows.
مقدمة: نموذج اللغة الكبيرة ، الذي يدعم اللغة المتعددة التي تم تطويرها بشكل مستقل بواسطة تقنية Shenzhen Yuanxiang. دعم أكثر من 40 لغة مثل الصين وبريطانيا وروسيا والغربية.
Skywork
العنوان: https://github.com/skyworkai/skywork
مقدمة: المشروع مفتوح لنماذج سلسلة تيانغونغ. نموذج محدد لـ Skywork-13B-base ، نموذج Skywork-13B-Chat ، نموذج Skywork-13B-Math ، نموذج Skywork-13B-MM ، ونماذج الإصدار الكمي لكل طراز لدعم المستخدمين للنشر والسبب في نشر بطاقة الرسومات المستهلك و جوهر التفكير
نعم
العنوان: https://github.com/01- ai/yi
مقدمة موجزة: هذا المشروع مفتوح لنماذج مثل YI-6B و YI-34B. وثائق مع أكثر من 1000 صفحة.
مقدمة: يعتمد المشروع على التدريب على مقياس التدريب ؛ -جولات متعددة للتكيف مع سيناريوهات التطبيق المختلفة وتفاعلات الحوار متعددة الدورات. في الوقت نفسه ، نحن نعتبر أيضًا حلًا أسرع للتكيف الصيني: الصينية-لاما 2-SFT-V0: استخدم تعليمات صينية مفتوحة المصدر موجودة بيانات النقل أو الحوار الدقيق إلى LAMA-2 بشكل مباشر (سيكون مفتوح المصدر مؤخرًا).
مقدمة: استنادًا إلى LLAMA-7B ، وهي قاعدة لغوية كبيرة تم إنشاؤها بواسطة التدريب المسبق لتدريبات البيانات الصينية ، مقارنةً بـ LLAMA الأصلي ، تحسن هذا النموذج بشكل كبير من حيث الفهم الصيني وقدرة توليدها. .
حسناء:
العنوان: https://github.com/lianjiaatech/belle
مقدمة: المصدر المفتوح لسلسلة من النماذج القائمة على تحسين Bloomz و Llama. خوارزميات التدريب على أداء النموذج.
مقدمة: يعتمد المصدر المفتوح على LLAMA -7B ، -13B ، -33B ، -65B لنماذج لغة ما قبل التدريب المستمرة في الحقل الصيني ، ويستخدم ما يقرب من 15 مليون بيانات للتدريب الثانوي قبل.
روبن (روبن):
العنوان: https://github.com/optimalscale/lmflow
مقدمة موجزة: روبن (روبن) هو نموذج ثنائي اللغة الصيني -الذي طوره فريق LMFLOW في جامعة العلوم والتكنولوجيا في الصين. كان نموذج Robin الثاني فقط الذي تم الحصول عليه بواسطة بيانات بيانات 180K فقط ، حيث وصل إلى المركز الأول في قائمة Huggingface. يدعم LMFLOW المستخدمين لتدريب النماذج الشخصية بسرعة.
مقدمة: Fengshenbang-LM (النموذج الكبير لله) هو نظام كبير من المصادر المفتوحة التي يهيمن عليها معهد أبحاث الأفكار الحوسبة المعرفية وبحوث اللغة الطبيعية. وكتابة الإعلانات ، مسابقة الحس السليم ، والحوسبة الرياضية. بالإضافة إلى نماذج سلسلة Jiangziya ، فإن المشروع مفتوح أيضًا لنماذج مثل سلسلة Taiyi و Erlang God.
بيلا:
العنوان: https://github.com/neutralzz/billa
مقدمة موجزة: المشروع هو المصدر المفتوح لنموذج Llama بلغتين الصين -مع قدرات التفكير المعززة. الخصائص الرئيسية للنموذج هي: تعزيز قدرة الفهم الصيني للياما ، وتقليل الأضرار التي لحقت بقدرة اللغة الإنجليزية على مستوى المهمة ، وتستخدم بيانات المهمة ، وتستخدم chatgpt لإنشاء التحليل مهمة فهم النموذج لحل منطق المهمة ؛
طحلب:
العنوان: https://github.com/openlmlab/moss
مقدمة: دعم لغة الحوار المفتوحة للمكونات الإضافية الصينية والإنجليزية. التدريب على التفضيل ، لديه تعليمات الحوار ، وتوصيل التعلم والتدريب على التفضيلات البشرية.
مقدمة: يتضمن سلسلة من المشاريع المفتوحة المصدر لنماذج اللغة الصينية الكبيرة ، والتي تحتوي على سلسلة من نماذج اللغة تعتمد على نماذج المصادر المفتوحة الحالية (MOSS ، LLAMA) ، تعليمات إلى مجموعات البيانات التي تتناسب معها.
لينلي:
العنوان: https://github.com/cvi-szu/linly
مقدمة: توفير نموذج الحوار الصيني لينلي-الطبقة الصينية ، النموذج الأساسي الصيني الللاما وبيانات التدريب. يعتمد النموذج الأساسي الصيني على لاما ، باستخدام التدريب التزايد الصيني والبريطاني والبريطاني. يلخص المشروع بيانات التعليمات المتعددة اللغات الحالية ، ويقوم بإجراء تعليمات واسعة النطاق لمتابعة النموذج الصيني لمتابعة التدريب ، وتحقيق نموذج حوار التلاشي الخلوي.
يراعة:
العنوان: https://github.com/yangjianxin1/firefly
مقدمة: يشتمل Firefly على مشروع صيني مفتوح المصدر. كما Baichuan Baichuan ، Ziya ، Bloom ، Llama ، إلخ. عقد Lora و Base Model لدمج الوزن ، وهو أكثر ملاءمة للعقل.
chatyuan
العنوان: https://github.com/clue- ai/chatyuan
مقدمة: سلسلة من نماذج لغة الحوار الوظيفي المدعوم من Yuanyu Interment ، والتي تدعم الحوار الثنائي اللغة الصيني -المُحسَّن في البيانات الدقيقة ، والتعلم البشري المعزز ، وسلسلة التفكير ، وما إلى ذلك ، إلخ.
chatrwkv:
العنوان: https://github.com/blinkdl/chatrwkv
مقدمة: Open Source سلسلة من نماذج الدردشة (بما في ذلك اللغة الإنجليزية والصينية) استنادًا إلى بنية RWKV ، والموديلات المنشورة بما في ذلك Raven ، و Novel-Chneng ، و Novel-Chneng-Chnpro ، يمكنها الدردشة واللعب مباشرة شعر وروايات وغيرها إبداعات.
CPM-BEE
العنوان: https://github.com/openbmbmb/cpm-bee
مقدمة موجزة: المصدر المفتوح الكامل ، والاستخدام التجاري المسموح به من 10 مليارات من النماذج القاعدة الصينية والإنجليزية. إنها تتبنى بنية الانحدار التلقائي للمحول لإجراء التدريب المسبق على مجموعة عالية الجودة في تريليون ، ولديها قدرات أساسية قوية. يمكن للمطورين والباحثين التكيف مع السيناريوهات المختلفة على أساس نموذج قاعدة CPM-BEE لإنشاء نماذج تطبيقات في حقول محددة.
مقدمة: نموذج لغة واسع النطاق (LLM) مع مجموعة متعددة ومهام متعددة (LLM) ، المصدر المفتوح يشمل النماذج: Tigerbot-7B ، Tigerbot-7B-Base ، Tigerbot-180B ، رمز التدريب الأساسي والمنطق ، 100 جرام بيانات ما قبل التدريب ، وتغطية التمويل والقانون مجال الموسوعة و API.
مقدمة: ورث نموذج لغة Aquila ، الذي نشره معهد Zhiyuan للبحوث ، مزايا التصميم المعماري لـ GPT-3 ، Llama ، وما إلى ذلك ، محل مجموعة من المشغلين الأساسيين الأكثر كفاءة لتحقيق ، وأعاد تصميم الرمز المميز الصيني والإنجليزي ، ترجع Bmtrain المتوازي بدأت طريقة التدريب من 0 على أساس جودة الصينية والإنجليزية. إنه أيضًا أول نموذج لغة مفتوح المصدر كبير النطاق يدعم المعرفة الجنسية الصينية الثنائية ، ودعم اتفاقية الترخيص التجاري ، وتلبية احتياجات الامتثال للبيانات المحلية.
Aquila2
العنوان: https://github.com/flagai-open/aquila2
مقدمة: نشرها معهد أبحاث Zhiyuan ، سلسلة Aquila2 ، بما في ذلك نموذج اللغة الأساسي Aquila2-7b و Aquila2-34b و Aquila2-70b-Expr و Dialogue Aquilachat2-7b و Aquilachat2-34b و Aquilachat2-70-P-Expr ، telect teled long quopog quorg -7B-16K و Aquilachat2-34B-16.
أنيما
العنوان: https://github.com/lyogavin/anima
مقدمة: يعتمد هذا النموذج على نموذج 33B من AI Ten Model الذي تم تطويره بواسطة AI Ten Model. بناءً على تقييم بطولة تصنيف ELO أفضل.
Knowlm
العنوان: https://github.com/zjunlp/knowlm
مقدمة: يهدف مشروع Knowlm إلى نشر إطار عمل النماذج الكبيرة المفتوحة المصدر والأوزان النموذجية المقابلة للمساعدة في تقليل مشكلة مغالطة المعرفة ، بما في ذلك صعوبة معرفة النماذج الكبيرة والأخطاء المحتملة والأحكام الإقامة. أصدرت المرحلة الأولى من المشروع استخراجًا قائمًا على Llama لتحليل الذكاء النموذجي الكبير ، باستخدام مجموعة الصينية والإنجليزية لزيادة تدريب LAMA (13B) ، وتحسين مهام استخراج المعرفة بناءً على تكنولوجيا تعليمات تحويل الرسم البياني المعرفة.
Bayling
العنوان: https://github.com/ictnlp/bayling
مقدمة: تم تطوير نموذج عالمي كبير على نطاق واسع مع محاذاة متعددة اللغة من قبل فريق علاج اللغة الطبيعية في معهد تكنولوجيا الحوسبة في الأكاديمية الصينية للعلوم. يستخدم Bayling Llama كنموذج أساسي ، حيث يستكشف طريقة التعليمات الدقيقة مع مهام الترجمة التفاعلية باعتبارها جوهرها. . في تقييم الترجمة المتعددة اللغات ، والترجمة التفاعلية ، والمهام الشاملة ، والامتحانات الموحدة ، أظهرت Bai Ling أداءً أفضل باللغة الصينية/الإنجليزية. يوفر Bai Ling نسخة عبر الإنترنت من العرض التوضيحي للجميع لتجربة.
مقدمة: Yulan-Chat هو نموذج لغة كبير تم تطويره بواسطة باحثو Renmin بجامعة GSAI. تم تطويره بشكل جيد على أساس LLAMA وله تعليمات باللغة الإنجليزية والصينية عالية الجودة. يمكن لـ Yulan-Chat الدردشة مع المستخدمين ، واتبع التعليمات الإنجليزية أو الصينية جيدًا ، ويمكن نشرها على GPU (A800-80G أو RTX3090) بعد التقدير الكمي.
polylm
العنوان: https://github.com/damo-nlp-mt/polylm
مقدمة موجزة: نموذج متعدد اللغات تم تدريبه من بداية 640 مليار كلمة ، بما في ذلك حجم نموذجين (1.7B و 13B). يغطي Polylm الصين ، بريطانيا ، روسيا ، الغرب ، فرنسا ، البرتغاليين ، ألمانيا ، إيطاليا ، هو ، بو ، بوبو ، آشي ، العبرانيين ، اليابان ، كوريا الجنوبية ، تايلاند ، فيتنام ، إندونيسيا وغيرها من أنواعها ، خاصة أكثر ودية للغة الآسيوية.
هووزي
العنوان: https://github.com/hit-scir/huozi
مقدمة: نموذج لغوي كبير قبل التدريب لنموذج لغة ما قبل التدريب الكبير الذي تم تطويره بواسطة معهد أبحاث معهد هاربين للعلاج الطبيعي. يعتمد هذا النموذج على نموذج المعلمة 7 مليارات من بنية Bloom ، والذي يدعم ثنائي اللغة الصيني والإنجليزية. مجموعة البيانات.
ياي
العنوان: https://github.com/weenge-research/yayi
مقدمة: النموذج الأنيق مُخفف في البيانات الميدانية عالية الجودة لحقل الجودة العالي للملايين من الهياكل الاصطناعية. والحكم الحضري. من تكرار التهيئة المسبقة للتدريب المسبق ، قمنا بتنفيذ قدراتها الأساسية على قدرتها الصينية والتحليل الميداني تدريجياً ، وزيادة جولات متعددة من الحوار وبعض القدرات. في الوقت نفسه ، بعد المئات من الاختبارات الداخلية للمستخدمين ، تم تحسين التعليقات الاصطناعية المستمرة بشكل مستمر ، مما يزيد من تحسين أداء النموذج والأمان. يستكشف المصدر المفتوح لنموذج التحسين الصيني القائم على LLAMA 2 آخر الممارسات المناسبة للبعثات الصينية في العديد من مجالات الصينيين.
yayi2
العنوان: https://github.com/weenge-research/yayi2
مقدمة: Yayi 2 هو جيل جديد من نماذج اللغة الكبيرة المفتوحة المصدر التي طورتها Zhongke Wenge ، بما في ذلك إصدارات القاعدة والدردشة مع مقياس المعلمة 30 ب. Yayi2-30b هو نموذج لغة كبير يعتمد على المحول ، باستخدام مجموعة عالية الجودة ومتعددة اللغات التي تزيد عن 2 تريليون رمز للتدريب المسبق. استجابةً لسيناريوهات التطبيق بشكل عام ومجالات محددة ، استخدمنا ملايين التعليمات لتنظيفها ، وفي الوقت نفسه ، نستخدم التعليقات البشرية لتعزيز أساليب التعلم لمحاذاة النموذج والقيم الإنسانية بشكل أفضل. هذا النموذج مفتوح المصدر هو نموذج قاعدة Yayi2-30B.
يوان -2.0
العنوان: https://github.com/ieit-yuan/yuan-2.0
مقدمة: يفتح المشروع جيلًا جديدًا من نموذج اللغة الأساسي الذي تم إصداره بواسطة Inspur Information. وتوفير البرامج النصية ذات الصلة لخدمات التدريب المسبق ، والرائعة ، والخدمات المنطقية. يعتمد المصدر 2.0 على المصدر 1.0 ، باستخدام المزيد من البيانات المسبقة ذات الجودة العالية ومجموعات البيانات الدقيقة لجعل النموذج لها فهم أقوى في الدلالات والرياضيات والتفكير والرمز والمعرفة.
مقدمة: يقوم المشروع بإجراء طاولات خبير مختلطة متفرقة في Mixtral-8x7B. تم تحسين كفاءة الترميز الصينية لهذا النموذج بشكل كبير من النموذج الأصلي. في الوقت نفسه ، من خلال التدريب المسبق للتدريب على مجموعة كبيرة من المصدر مفتوح النطاق ، فإن هذا النموذج لديه جيل صيني قوي وقدرة على التفاهم.
بلويلم
العنوان: https: //github.com/vivo-jlab/bluelm
مقدمة: Bluelm هو نموذج لغة مسبقة للغاية تم تطويره بشكل مستقل من قبل معهد الأبحاث العالمي في Vivo. (دردشة) نموذج.
مقدمة: Orionstar-YI-34B-Chat هو نموذج YI-34B المستند إلى Sky Starry استنادًا إلى المصدر المفتوح البالغ 10،000 شيء. تجارب تفاعلية لمستخدمي المجتمع الكبير.
minicpm
يضيف
مقدمة: Minicpm عبارة عن سلسلة من النماذج الجانبية التي يتم افتتاحها عادةً بواسطة ذكاء جدار المعكرونة ومختبر اللغة الطبيعية لجامعة Tsinghua. من المعلمات.
Mengzi3
العنوان: https://github.com/langboat/mengzi3
مقدمة: يعتمد نموذج Mengzi3 8b/13B على بنية Llama ، مع اختيار Corpus من صفحات الويب ، الموسوعة ، الاجتماعية ، الإعلام ، الأخبار ، ومجموعات بيانات المصادر المفتوحة عالية الجودة. من خلال استمرار تدريب مجموعة متعددة اللغة على تريليون رموز ، فإن القدرة الصينية للنموذج رائعة وتأخذ في الاعتبار القدرة متعددة اللغة.
1.2 نموذج Multifamily LLM
VisualGLM-6B
العنوان: https://github.com/thudm/visualglm-6b
مقدمة: يعتمد نموذج لغة الحوار متعدد الأوضاع ، وهو نموذج اللغة الصينية والإنجليزية. بالاعتماد على زوج الرسوم الصينية عالية الجودة من 30 متر من مجموعة بيانات COGVIEW ، قبل التدريب مع الرسم الإنجليزي الذي تم فحصه مع 300 متر.
cogvlm
العنوان: https://github.com/thudm/cogvlm
مقدمة موجزة: نموذج لغة بصرية مفتوح المصدر قوي (VLM). يحتوي COGVLM-17B على 10 مليارات معلمات بصرية و 7 مليارات من المعلمات اللغوية. حقق COGVLM-17B أداء SOTA في 10 اختبارات قياسية كلاسيكية متعددة المعدلات. يمكن لـ COGVLM وصف الصور بدقة ، ولا تظهر الهلوسة تقريبًا.
مقدمة: النماذج الصينية متعددة الأسلوب تم تطويرها على أساس مشروع نموذج Llama & Alpaca الصيني. يضيف VisualCla وحدات تشفير الصور إلى نموذج Llama/Alpaca الصيني ، بحيث يمكن أن يتلقى نموذج Llama معلومات بصرية. على هذا الأساس ، تم استخدام الرسم الصيني للاتصالات المتعددة المسببة للبيانات. تعليمات الوضع هي حاليا مفتوحة المصدر VisualCla-7B-V0.1.
llasm
العنوان: https://github.com/linksoul- ai/llasm
مقدمة موجزة: أول نموذج حوار مفتوح المصدر والتجاري الذي يدعم حوارًا متعدد الوسائط الصيني والإنجليزي. ستعمل المدخلات الصوتية المريحة على تحسين تجربة النموذج الكبير مع النص كإدخال ، مع تجنب العمليات الشاقة بناءً على حلول ASR والأخطاء المحتملة التي قد يتم تقديمها. حاليًا المصدر المفتوح Llasm-chinese-llama-2-7b و Llasm-Baichuan-7B وغيرها من النماذج ومجموعات البيانات.
Viscpm
يضيف
مقدمة: سلسلة طرازات متعددة الأوضاع مفتوحة المصدر ، تدعم الحوار الصيني والإنجليزي متعدد الأوضاع (نماذج Chat في VisCPM) ونص على إمكانيات توليد الرسم البياني (نموذج Viscpm-Paint). تعتمد VISCPM على عشرات المليارات من المعلمات ، وتدريب نموذج اللغة على نطاق واسع CPM-BEE (10B) ، ويدمج المشفر البصري (Q-former) ومواد الترميز البصري (Diffusion-unet) لدعم مدخلات وإخراج الإشارة البصرية. بفضل القدرة الممتازة ثنائية اللغة لقاعدة CPM-BEE ، لا يمكن أن تكون VISCPM فقط تدريبًا مسبقًا من خلال البيانات الإنجليزية متعددة الوسائط لتحقيق قدرة صينية متعددة الوسائط ممتازة.
Introduction: The project is open to the field of Chinese long text instructions with a multi-scale psychological counseling field with a multi-round dialogue data combined instruction to fine-tune the psychological health model (Soulchat). Fully tune the full number of parameters .
Introduction: WingPT is a large model based on the GPT-based medical vertical field. Based on the Qwen-7B1 as the basic pre-training model, it has continued pre-training in this technology, instructions fine-tuning. -7B-Chat نموذج.
简介:LazyLLM是一款低代码构建多Agent大模型应用的开发工具,协助开发者用极低的成本构建复杂的AI应用,并可以持续的迭代优化效果。 Lazyllm provides a more flexible application function customization method, and realizes a set of lightweight network management mechanisms to support one -click multi -Agent application, support streaming output, compatible with multiple IaaS platforms, and support the model in the application model Continue fine - ضبط.
MemFree
地址:https://github.com/memfreeme/memfree
简介:MemFree 是一个开源的Hybrid AI 搜索引擎,可以同时对您的个人知识库(如书签、笔记、文档等)和互联网进行搜索, 为你提供最佳答案。MemFree 支持自托管的极速无服务器向量数据库,支持自托管的极速Local Embedding and Rerank Service,支持一键部署。
Data set description: The scholar · Wanjuan 1.0 is the first open source version of the scholar · Wanjuan multi -modal language library, including three parts: text data set, graphic data set, and video data set. The total amount of data exceeds 2TB . 目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
Data set description: Unified rich IFT data (such as COT data, still expands continuously), multiple training efficiency methods (such as Lora, P-Tuning), and multiple LLMS, three interfaces on three levels to create convenient researchers LLM-IFT research منصة.
Data set description: Data sets are renovated with the true psychological mutual assistance QA for multiple rounds of psychological health support through ChatGPT. Dialogue themes, vocabulary and chapters are more rich and diverse, and are more in line with the application scenarios of multi -round حوار.
偏好数据集
CValues
地址:https://github.com/X-PLUG/CValues
数据集说明:该项目开源了数据规模为145k的价值对齐数据集,该数据集对于每个prompt包括了拒绝&正向建议(safe and reponsibility) > 拒绝为主(safe) > 风险回复(unsafe)三种类型,可用于增强SFT模型的安全性或用于训练reward模型。
简介:一个中文版的大模型入门教程,围绕吴恩达老师的大模型系列课程展开,主要包括:吴恩达《ChatGPT Prompt Engineering for Developers》课程中文版,吴恩达《Building Systems with the ChatGPT API》课程中文版,吴恩达《LangChain for LLM Application Development》课程中文版等。
Introduction: ChatGPT burst into fire, which has opened a key step leading to AGI. This project aims to summarize the open source calories of those ChatGPTs, including large text models, multi -mode and large models, etc., providing some convenience for everyone .
简介:This repo aims at recording open source ChatGPT, and providing an overview of how to get involved, including: base models, technologies, data, domain models, training pipelines, speed up techniques, multi-language, multi-modal, and more to go.
简介:This repo record a list of totally open alternatives to ChatGPT.
Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM
简介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs.