يتكون المستودع من VQ-VAE تم تنفيذه في Pytorch وتدريب على مجموعة بيانات MNIST.
تتبع VQ-VAE نفس المفهوم الأساسي كما هو الحال مع أدوات التنقل التلقائية (VAE). تستخدم VQ-VAE التضمينات الكامنة المنفصلة لمشفرات السيارات المتغيرة ، أي كل بعد من z (المتجه الكامن) هو عدد صحيح منفصل ، بدلاً من التوزيع الطبيعي المستمر المستخدم بشكل عام أثناء ترميز المدخلات.
تتكون VAES من 3 أجزاء:
حسنًا ، قد تسأل عن الاختلافات التي تجلبها VQ-VAEs إلى الطاولة. دعونا ندرجهم:
العديد من الأشياء المهمة في العالم الحقيقي منفصلة. على سبيل المثال في الصور ، قد يكون لدينا فئات مثل "CAT" ، "Car" ، وما إلى ذلك ، وقد لا يكون من المنطقي الاستيفاء بين هذه الفئات. التمثيلات المنفصلة هي أيضا أسهل في نموذج.
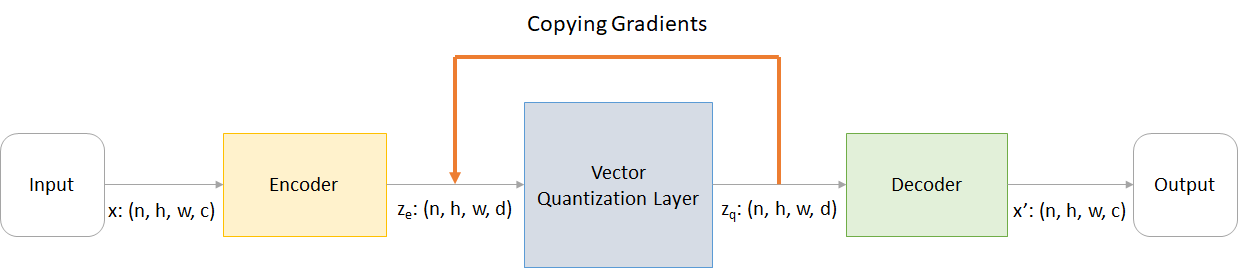
أين:
n : حجم الدُفعةh : ارتفاع الصورةw : عرض الصورةc : عدد القنوات في صورة الإدخالd : عدد القنوات في الحالة الخفية فيما يلي نظرة عامة موجزة على عمل شبكة VQ-VAE:
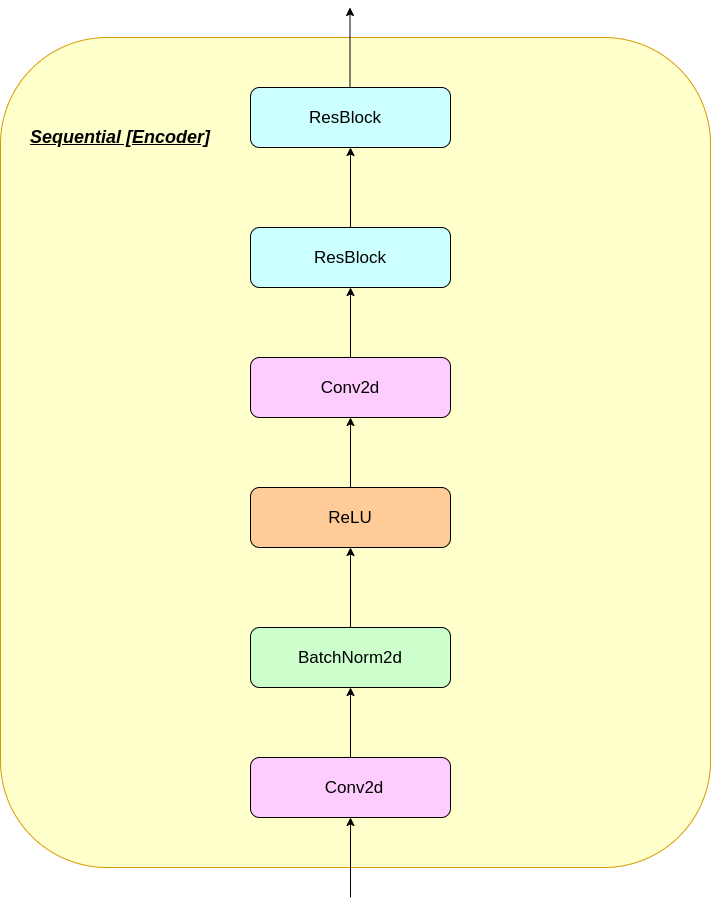
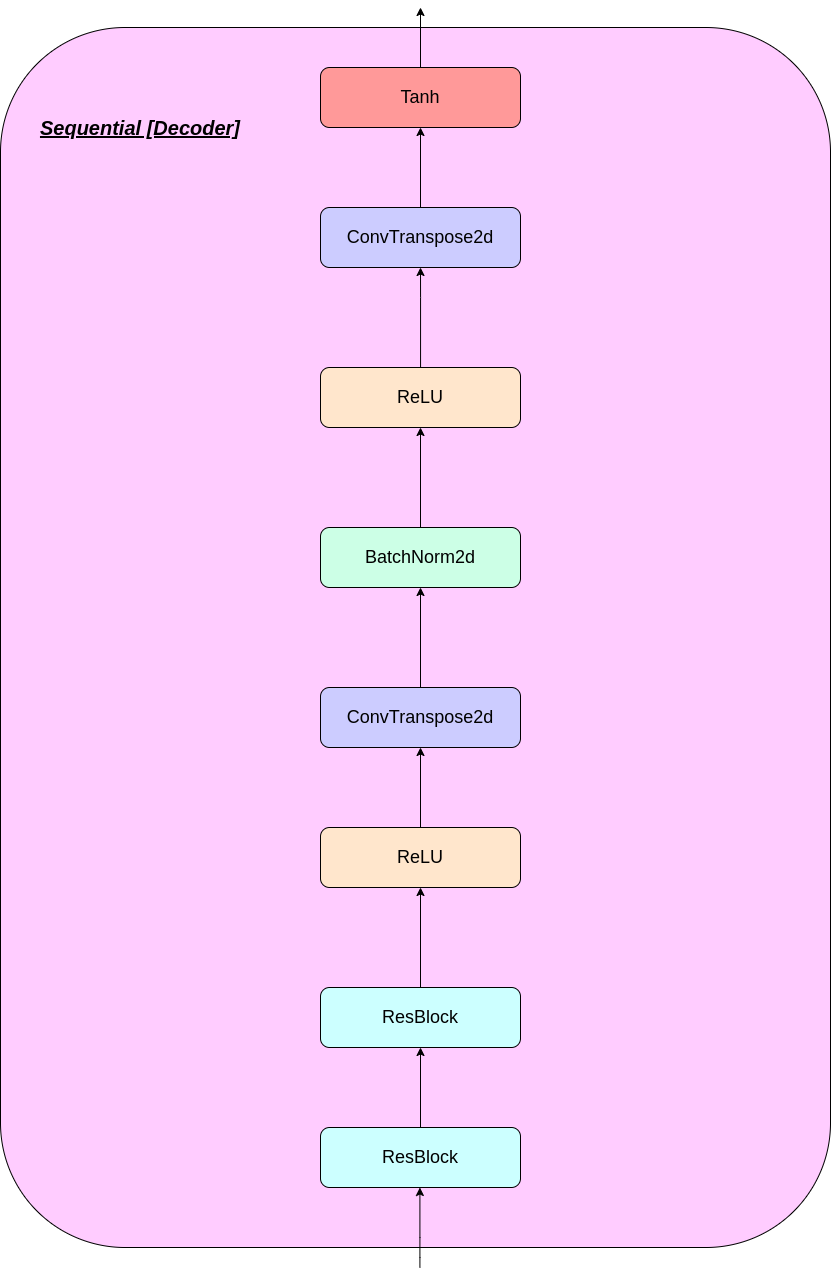
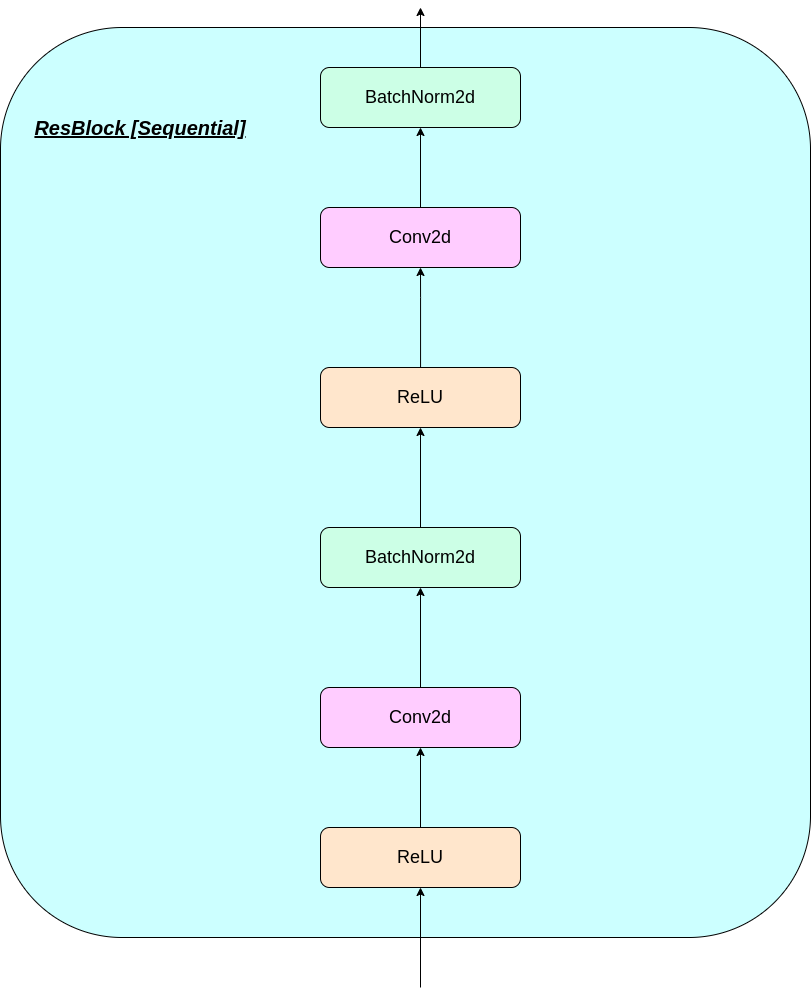
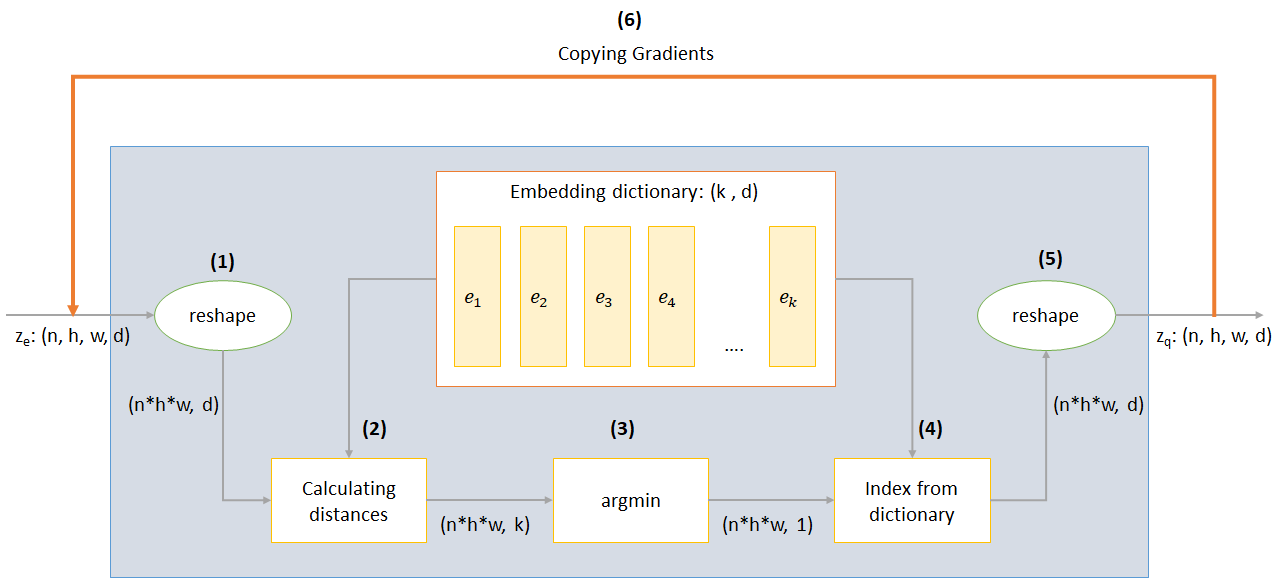
يمكن تفسير عمل طبقة VQ في ست خطوات كما هو مرقمة في الشكل:
يستخدم VQ-VAE 3 خسائر لحساب الخسارة الكلية أثناء التدريب:
فقدان إعادة الإعمار: يحسن وحدة فك التشفير والتشفير كـ VAE ، أي الفرق بين صورة الإدخال وإعادة الإعمار:
reconstruction_loss = -log( p(x|z_q) )
فقدان الكود: نظرًا لحقيقة أن التدرجات تتجاوز التضمين ، يتم استخدام خوارزمية تعلم القاموس التي تستخدم خطأ L2 لنقل متجهات التضمين E_I نحو إخراج المشفر.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(تمثل SG مشغل التدرج التوقف الذي يعني عدم وجود تدفقات تدرج من خلال كل ما يتم تطبيقه عليه)
فقدان الالتزام: نظرًا لأن حجم مساحة التضمين غير أبعاد ، فقد ينمو بشكل تعسفي إذا لم يتدرب التضمينات E_I بأسرع ما يتراوح من معلمات التشفير ، وبالتالي تتم إضافة خسارة الالتزام للتأكد من أن المشفر يرتبط بتضمين.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β هو مقياس مفرط يتحكم في مقدار ما نريد أن نزن فقدان الالتزام مقارنة بالمكونات الأخرى)
يمكنك إما تنزيل REPO أو استنساخه عن طريق تشغيل ما يلي في موجه CMD
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
يمكنك تدريب النموذج من الصفر حسب الأمر التالي (في Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - اسم مجلد البياناتdata-folder - اسم مجلد البياناتdevice - اضبط الجهاز (وحدة المعالجة المركزية أو CUDA ، افتراضي: وحدة المعالجة المركزية)hidden-size - حجم المتجهات الكامنة (الافتراضي: 40)k - عدد المتجهات الكامنة (الافتراضي: 512)batch-size - حجم الدُفعة (الافتراضي: 128)num-epochs - عدد الحدث (الافتراضي: 10)lr - معدل التعلم لـ Adam Optimizer (افتراضي: 2E -4)beta - مساهمة فقدان الالتزام ، بين 0.1 و 2.0 (افتراضي: 1.0)num-workers - عدد العمال لأخذ عينات المسارات (افتراضي: CPU_Count () - 1) يقوم البرنامج تلقائيًا بتنزيل مجموعة بيانات MNIST ويحفظها في مجلد PATH_TO_MNIST_dataset (تحتاج إلى إنشاء هذا المجلد). هذا يحدث مرة واحدة فقط.
كما أنه ينشئ مجلد logs ومجلد models وداخلها ينشئ مجلد مع الاسم الذي تم تمريره بواسطتك لحفظ السجلات ونقاط تفتيش النموذج بداخله على التوالي.
لإنشاء صور جديدة من Z تم أخذ عينات منها بشكل عشوائي من وحدة Gaussian قم بتشغيل الأمر التالي (في Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - اسم الملف الذي يحتوي على النموذجinput - mnist أو عشوائيdevice - اضبط الجهاز (وحدة المعالجة المركزية أو CUDA ، افتراضي: وحدة المعالجة المركزية)hidden-size - حجم المتجهات الكامنة (الافتراضي: 40)k - عدد المتجهات الكامنة (الافتراضي: 512)filename - الاسم الذي سيتم حفظ الملف به يولد شبكة 10*10 من الصور التي يتم حفظها في مجلد يدعى generatedImages .
يمكنك استخدام طراز مدرب مسبقًا عن طريق تنزيله من الرابط في model.txt .
يحتوي المستودع على الملفات التالية
modules.py - يحتوي على الوحدات المختلفة المستخدمة لصنع نموذجناVQ-VAE.py يحتوي على وظائف ورمز لتدريب نموذج VQ-VAE الخاص بناvector_quantizer.py - يتم تعريف فئات قياس الكميات المتجه في هذا الملفgenerate-py يولد صورًا جديدة من نموذج تدريب مسبقًاmodel.txt - يحتوي على رابط لنموذج مدرب مسبقًاREADME.md - ReadMe إعطاء نظرة عامة على الريبوreferences.txt - المراجع المستخدمة أثناء إنشاء هذا الريبوreadme_images - يحتوي على صور مختلفة لـ READMEMNIST - يحتوي على مجموعة بيانات MNIST المضغوطة (على الرغم من أنه سيتم تنزيلها تلقائيًا إذا لزم الأمر)Training track for VQ-VAE.txt يحتوي على قيم الخسارة أثناء تدريب نموذج VQ-VAE الخاص بناlogs_VQ-VAE يحتوي على سجلات اللوح المضغوط لنموذج VQ-VAE (تم إنشاؤه تلقائيًا بواسطة البرنامج)testers.py - يحتوي على بعض الوظائف لاختبار وحداتنا المحددةأمر لتشغيل Tensorboard (في Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
صورة التدريب
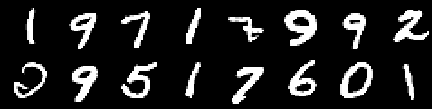
صورة من الفعل 0

الصورة من العصر الثاني
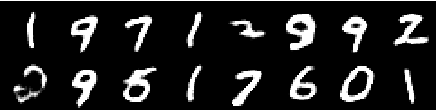
صورة من الفعل الرابع
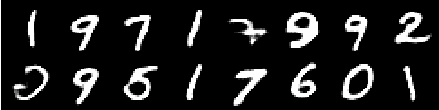
صورة من العصر السادس
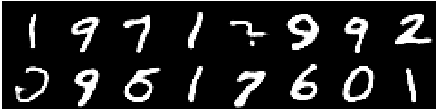
صورة من العصر الثامن
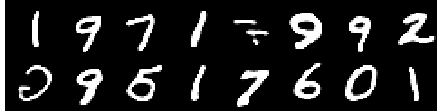
صورة من العاشرة
تستمر عمليات إعادة البناء في التحسن وفي النهاية تشبه تقريبًا صور التدريب التي تنعكس في قيم الخسارة (تحقق من Training track for VQ-VAE.txt ).
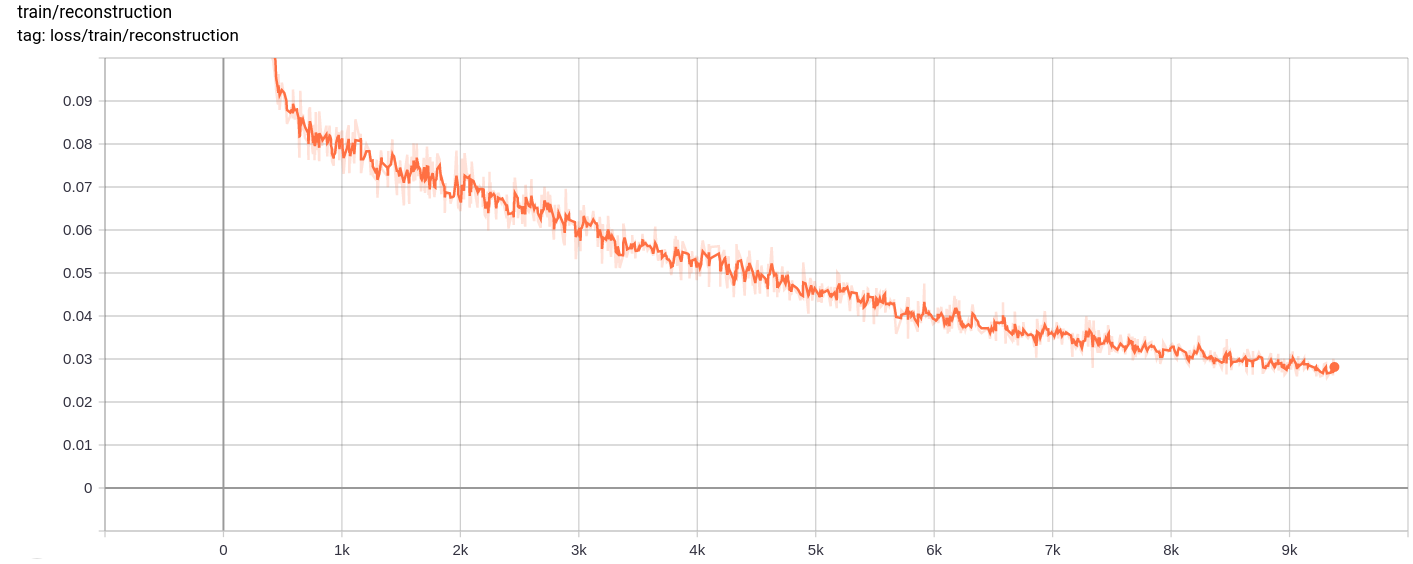
فقدان إعادة الإعمار
فقدان الكمي
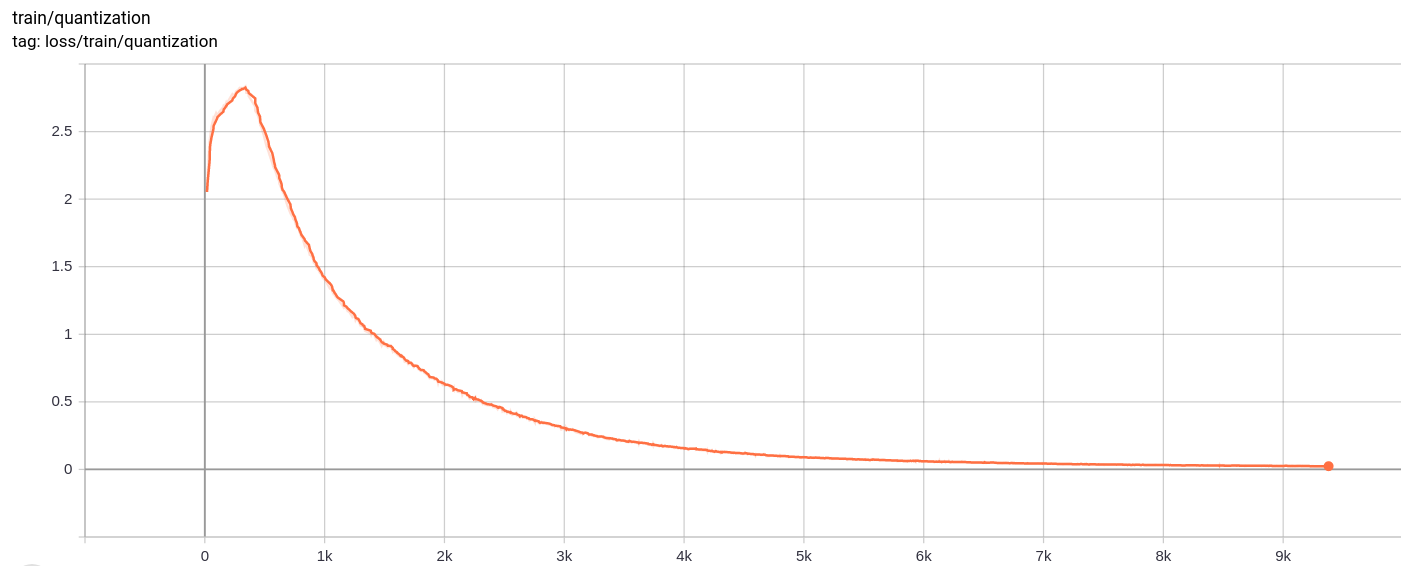
Total_loss
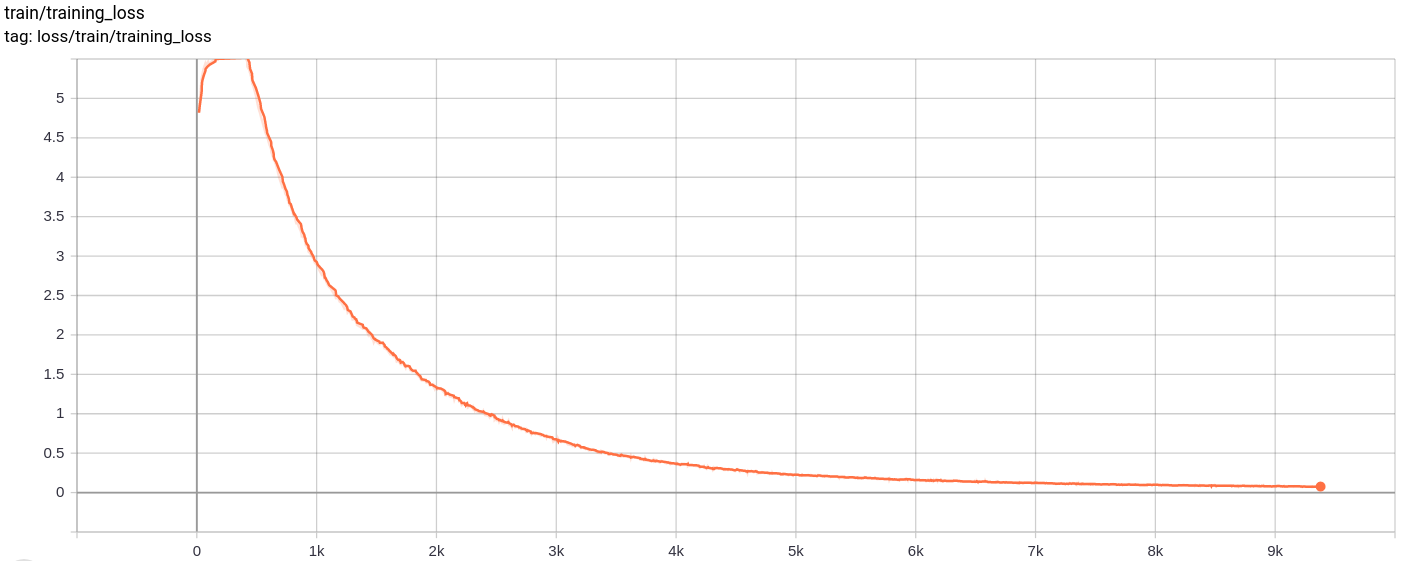
الخسارة الكلية ، وفقدان إعادة الإعمار وفقدان القياس انخفاض بشكل موحد كما هو متوقع.
testing_loss
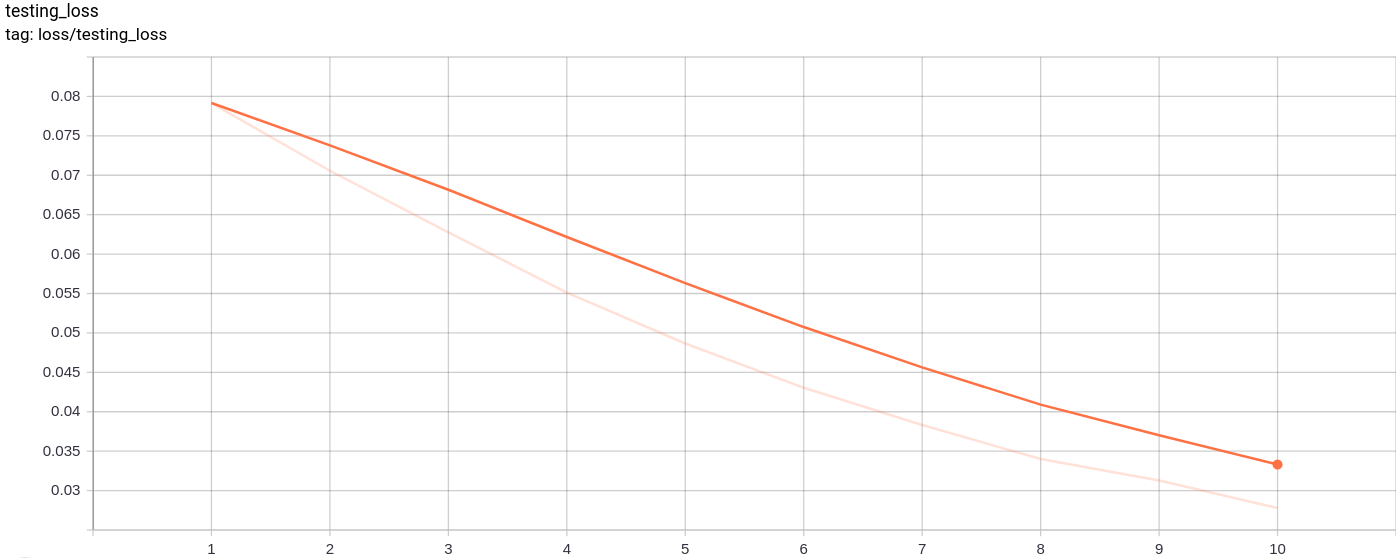
انخفاض فقدان الاختبار بشكل موحد كما هو متوقع.
تم إنشاء شبكة الصورة التالية بعد تمرير صور mnist كمدخلات:

الجيل جيد جدا.
تم إنشاء شبكات الصورة التالية بعد تمرير أخذ العينات من AZ بشكل عشوائي من وحدة غاوسية كمدخلات للنموذج ثم تم تمريرها عبر وحدة فك الترميز


الصور لا تبدو مثالية. يمكن أن يساعد ضبط أبعاد المساحة الكامنة وعدد ناقلات التضمين وما إلى ذلك في توليد صور عشوائية أفضل.
تم تدريب النموذج على Google Colab لمدة 10 عصر ، مع حجم الدُفعة 128.
بعد تدريب ، تمكن النموذج من إعادة بناء صور الإدخال جيدًا ، وكان قادرًا أيضًا على إنشاء صور جديدة على الرغم من أن الصور التي تم إنشاؤها ليست جيدة جدًا.
كما استمر التدريب وكذلك فقدان الاختبار في الانخفاض تقريبًا.
لاحظت أن تدريب النموذج لأكثر من 10-20 حقبة أنتجت نتائج اقترحت علامة محتملة على التورط في النموذج. أيضا ، جربت أبعاد مختلفة من مساحة listynt وفي dimension = 40 أنتجت أفضل النتائج. جاء أفضل نطاق للبعد بين 16-42.
ساعدت المصادر التالية كثيرًا في جعل هذا المستودع


