
التنفيذ الرسمي لـ GFT ، وهو نموذج أساس للمهام المتقاطعة على الرسوم البيانية. يتم إنشاء الشعار بواسطة Dall · e 3.
تأليف من قبل زيهونغ وانغ ، تشايوان تشانغ ، نيتيش ضد تشاولا ، تشوكو تشانغ ، ويانفانغ يي.
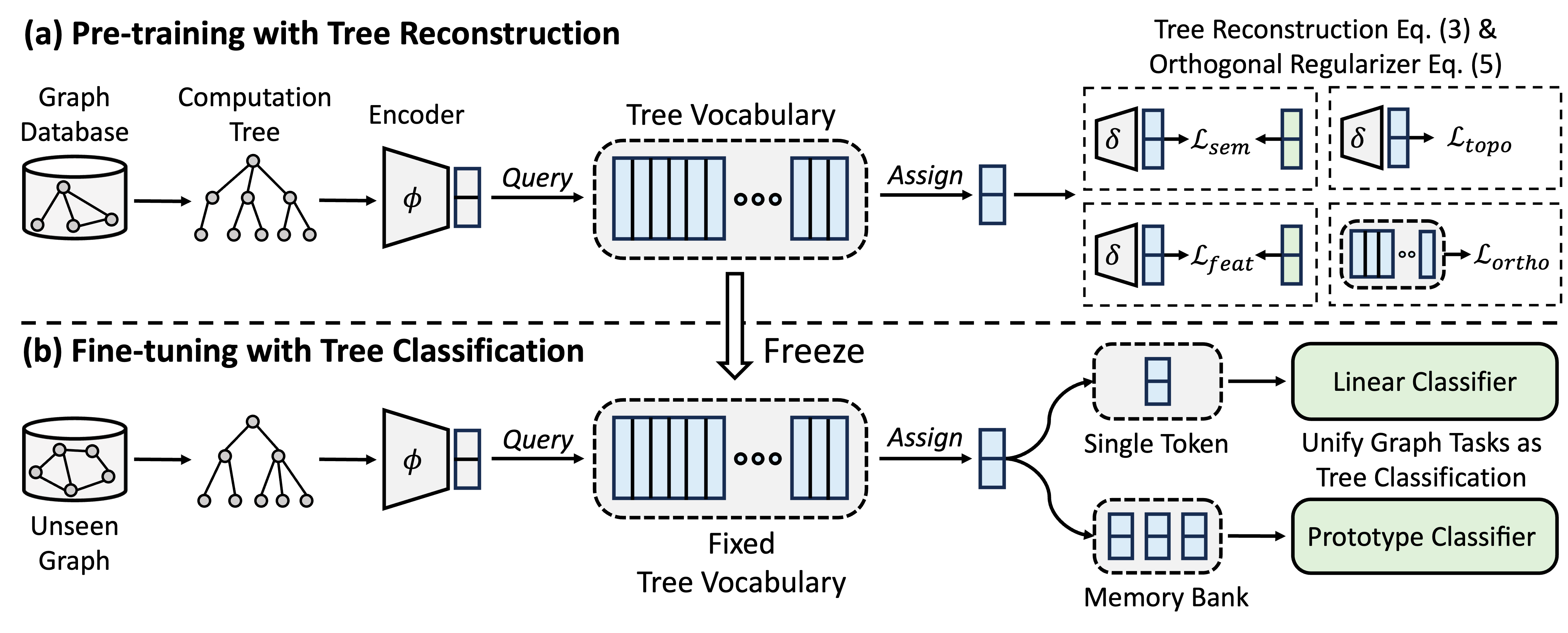
GFT عبارة عن نموذج مؤسسة مقلوب في مجال الرسم البياني ، والذي يعامل أشجار الحساب كأنماط قابلة للتحويل للحصول على مفردات شجرة قابلة للتحويل. علاوة على ذلك ، يوفر GFT إطارًا موحدًا لمحاذاة المهام المتعلقة بالرسومات ، مما يتيح نموذجًا واحدًا من الرسم البياني ، على سبيل المثال ، GNN ، للتعامل مع مهام مستوى العقدة بشكل مشترك ، على مستوى الحافة ، على مستوى الرسم البياني.
أثناء التدريب المسبق ، يقوم النموذج بترميز المعرفة العامة من قاعدة بيانات الرسم البياني إلى مفردات شجرة من خلال مهمة إعادة بناء الأشجار. في عملية ضبطها ، يتم تطبيق مفردات الأشجار المستفادة لتوحيد المهام المتعلقة بالرسوم البيانية كمهام تصنيف الأشجار ، وتكييف المعرفة العامة المكتسبة مع مهام محددة.
يمكنك استخدام كوندا لتثبيت البيئة. يرجى تشغيل البرنامج النصي التالي. نقوم بتشغيل جميع التجارب على وحدة معالجة الرسومات A40 48G واحدة ، ومع ذلك فإن وحدة معالجة الرسومات مع ذاكرة 24 جرام تكفي للتعامل مع جميع مجموعات البيانات باستخدام مزارع صغير.
conda env create -f environment.yml
conda activate GFT
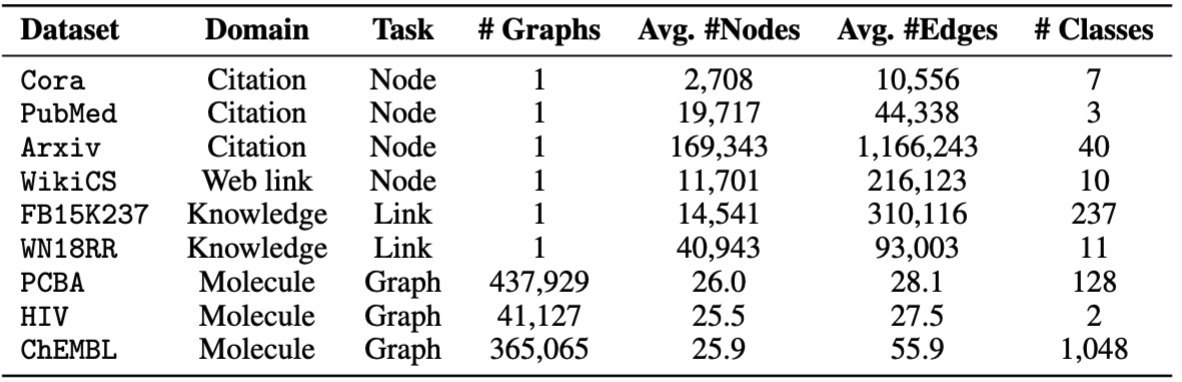
نستخدم مجموعات البيانات التي توفرها OFA. يمكنك تشغيل pretrain.py لتنزيل مجموعات البيانات تلقائيًا ، والتي سيتم تنزيلها على /data افتراضيًا. سيقوم خط الأنابيب تلقائيًا بمعالجة مجموعات البيانات عن طريق تحويل الأوصاف النصية إلى التضمينات النصية.
بدلاً من ذلك ، يمكنك تنزيل مجموعات البيانات المعالجة مسبقًا وفك الضغط على مجلد /data .
يتم تقديم رمز GFT في المجلد /GFT . الهيكل كما يلي.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
يمكنك تشغيل pretrain.py لتدرج على مجموعة واسعة من الرسوم البيانية و finetune.py للتكيف مع بعض المهام المصب مع التعلم الأساسي أو التعلم قليل.
لإعادة إنتاج النتائج ، نحن نقدم المعلمات المفرطة التفصيلية لكل من التدريب والتخلي عن المحافظة على config/pretrain.yaml و config/finetune.yaml ، على التوالي. للاستفادة من المعلمات المفرطة الافتراضية ، نقدم أمرًا- --use_params لكل من presrain و finetune.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
من أجل Finetuning ، نقدم ثماني مجموعات بيانات ، بما في ذلك cora و pubmed و wikics و arxiv و WN18RR و FB15K237 و chemhiv و chempcba .
بدلاً من ذلك ، يمكنك تشغيل البرنامج النصي لإعادة إنتاج التجارب.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
ملاحظة: سيتم تخزين النموذج المسبق في ckpts/pretrain_model/ افتراضيًا.
# The basic command for pretraining GFT
python GFT/pretrain.py
عندما تقوم بتشغيل pretrain.py ، يمكنك تخصيص مجموعات البيانات المسبقة والمجالات المفرطة.
يمكنك استخدام --pretrain_dataset (أو --pt_data ) لتعيين مجموعات بيانات ما قبل الأثرية المستخدمة والأوزان المقابلة. تكوين البيانات المحدد مسبقًا في config/pt_data.yaml ، مع الهياكل التالية.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
في الحالة أعلاه ، all هو اسم الإعداد ، وهذا يعني أن جميع مجموعات البيانات تستخدم في pretring. لكل مجموعة بيانات ، هناك أزواج ذات قيمة رئيسية ، حيث يكون المفتاح هو اسم مجموعة البيانات والقيمة هي وزن أخذ العينات. على سبيل المثال ، cora: 5 يعني أن مجموعة بيانات cora سيتم أخذ عينات منها 5 مرات في عصر واحد. يمكنك تصميم مجموعة مجموعات البيانات الخاصة بك من أجل GFT PRETREING.
يمكنك تخصيص مرحلة ما قبل التدريب عن طريق تغيير المقاييس المفرطة للتشفير ، والكمية المتجهات ، والتدريب النموذجي.
--pretrain_dataset : أشر إلى مجموعة البيانات المسبقة. نفس الشيء إلى ما سبق.--use_params : استخدم المعلمات المفرطة المحددة مسبقًا.--seed : البذور المستخدمة للتدريب.--hidden_dim : البعد في الطبقة المخفية من GNNs.--num_layers : طبقات GNN.--activation : وظيفة التنشيط.--backbone : العمود الفقري gnn.--normalize : طبقة التطبيع.--dropout : تسرب طبقة GNN.--code_dim : بُعد كل رمز في المفردات.--codebook_size : عدد الرموز في المفردات.--codebook_head : عدد رؤساء الكودون. إذا كان الرقم أكبر من 1 ، فستستخدم بشكل مشترك مفردات متعددة.--codebook_decay : معدل تحلل الرموز.--commit_weight : وزن مصطلح الالتزام.--pretrain_epochs : عدد الحقبة.--pretrain_lr : معدل التعلم.--pretrain_weight_decay : وزن المنظم L2.--pretrain_batch_size : حجم الدُفعة.--feat_p : معدل فساد الميزة.--edge_p : معدل الفساد الحافة/الهيكل.--topo_recon_ratio : يجب إعادة بناء نسبة الحواف.--feat_lambda : وزن فقدان الميزة.--topo_lambda : وزن فقدان الطوبولوجيا.--topo_sem_lambda : وزن فقدان الطوبولوجيا في ميزات حافة إعادة الإعمار.--sem_lambda : وزن الخسارة الدلالية.--sem_encoder_decay : معدل تحديث الزخم للمشفر الدلالي. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
يمكنك تعيين- --dataset للإشارة إلى مجموعة البيانات المصب ، و- --use_params لاستخدام المقاييس المفرطة المحددة مسبقًا لكل مجموعة بيانات. يتم تقديم علامات باراميرات أخرى يمكنك الإشارة إليها على النحو التالي.
بالنسبة للرسوم البيانية ذات الانقسام 1 المحدد مسبقًا ، يمكنك ضبط --repeat لإجراء تجارب متعددة.
--hidden_dim : البعد في الطبقة المخفية من GNNs.--num_layers : طبقات GNN.--activation : وظيفة التنشيط.--backbone : العمود الفقري gnn.--normalize : طبقة التطبيع.--dropout : تسرب طبقة GNN.--code_dim : بُعد كل رمز في المفردات.--codebook_size : عدد الرموز في المفردات.--codebook_head : عدد رؤساء الكودون. إذا كان الرقم أكبر من 1 ، فستستخدم بشكل مشترك مفردات متعددة.--codebook_decay : معدل تحلل الرموز.--commit_weight : وزن مصطلح الالتزام.--finetune_epochs : عدد الحصر.--finetune_lr : معدل التعلم.--early_stop : الحد الأقصى لوقف التوقف المبكر.--batch_size : إذا تم تعيينه على 0 ، قم بإجراء التدريب على الرسم البياني الكامل. --lambda_proto : وزن مصنف النموذج الأولي في Finetuning.
--lambda_act : وزن المصنف الخطي في Finetuning.
--trade_off : المفاضلة بين استخدام النموذج الأولي أو استخدام المصنف الخطي في الاستدلال.
يمكنك إضافة --no_lin_clf أو --no_proto_clf لتجنب استخدام المصنف الخطي أو مصنف النموذج الأولي ، على التوالي. لاحظ أن هذين المصطلحين يتعارضان ، حيث يجب عليك استخدام مصنف واحد على الأقل.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
يمكنك تعيين- --dataset للإشارة إلى مجموعة البيانات المصب ، و- --use_params لاستخدام المقاييس المفرطة المحددة مسبقًا لكل مجموعة بيانات. يتم تقديم علامات باراميرات أخرى يمكنك الإشارة إليها على النحو التالي.
المفردات المفرطة المخصصة للتعلم قليلًا
--n_train : عدد مثيلات التدريب لكل فصل لتصنيع النموذج. لاحظ أن n_train الصغير يحقق الأداء المرغوب فيه --n_task : عدد المهام التي تم أخذ عينات منها.--n_way : عدد الطرق.--n_query : حجم الاستعلام في كل طريقة.--n_shot : حجم مجموعة الدعم لكل طريقة.--hidden_dim : البعد في الطبقة المخفية من GNNs.--num_layers : طبقات GNN.--activation : وظيفة التنشيط.--backbone : العمود الفقري gnn.--normalize : طبقة التطبيع.--dropout : تسرب طبقة GNN.--code_dim : بُعد كل رمز في المفردات.--codebook_size : عدد الرموز في المفردات.--codebook_head : عدد رؤساء الكودون. إذا كان الرقم أكبر من 1 ، فستستخدم بشكل مشترك مفردات متعددة.--codebook_decay : معدل تحلل الرموز.--commit_weight : وزن مصطلح الالتزام.--finetune_epochs : عدد الحصر.--finetune_lr : معدل التعلم.--early_stop : الحد الأقصى لوقف التوقف المبكر.--batch_size : إذا تم تعيينه على 0 ، قم بإجراء التدريب على الرسم البياني الكامل. --lambda_proto : وزن مصنف النموذج الأولي في Finetuning.
--lambda_act : وزن المصنف الخطي في Finetuning.
--trade_off : المفاضلة بين استخدام النموذج الأولي أو استخدام المصنف الخطي في الاستدلال.
يمكنك إضافة --no_lin_clf أو --no_proto_clf لتجنب استخدام المصنف الخطي أو مصنف النموذج الأولي ، على التوالي. لاحظ أن هذين المصطلحين يتعارضان ، حيث يجب عليك استخدام مصنف واحد على الأقل.
قد تختلف النتائج التجريبية بسبب التهيئة العشوائية أثناء التدريب. نحن نقدم النتائج التجريبية باستخدام بذور عشوائية مختلفة (أي 1-5) في ما قبل التدريب لإظهار التأثير المحتمل للتهيئة العشوائية.
| كورا | PubMed | ويكي-CS | arxiv | wn18rr | FB15K237 | فيروس العوز المناعي البشري | PCBA | متوسط | |
|---|---|---|---|---|---|---|---|---|---|
| البذور = 1 | 78.58 ± 0.90 | 77.55 ± 1.54 | 79.38 ± 0.57 | 72.24 ± 0.16 | 91.56 ± 0.33 | 89.67 ± 0.35 | 72.69 ± 1.93 | 78.24 ± 0.23 | 79.99 |
| البذور = 2 | 78.27 ± 1.26 | 76.41 ± 1.36 | 79.36 ± 0.62 | 72.13 ± 0.24 | 91.72 ± 0.19 | 89.66 ± 0.31 | 71.62 ± 2.45 | 78.20 ± 0.33 | 79.67 |
| البذور = 3 | 78.16 ± 1.62 | 76.28 ± 1.37 | 79.32 ± 0.65 | 72.13 ± 0.30 | 91.57 ± 0.44 | 89.78 ± 0.23 | 71.58 ± 2.28 | 78.12 ± 0.37 | 79.62 |
| البذور = 4 | 78.42 ± 1.37 | 75.76 ± 1.58 | 79.44 ± 0.62 | 72.36 ± 0.34 | 91.70 ± 0.24 | 89.73 ± 0.21 | 72.57 ± 2.46 | 78.34 ± 0.27 | 79.79 |
| البذور = 5 | 78.56 ± 1.62 | 76.49 ± 2.00 | 79.27 ± 0.55 | 72.18 ± 0.26 | 91.47 ± 0.39 | 89.80 ± 0.19 | 72.27 ± 0.93 | 78.31 ± 0.34 | 79.79 |
| ذكرت | 78.62 ± 1.21 | 77.19 ± 1.99 | 79.39 ± 0.42 | 71.93 ± 0.12 | 91.91 ± 0.34 | 89.72 ± 0.20 | 72.67 ± 1.38 | 77.90 ± 0.64 | 79.92 |
لضمان استنساخ أفضل ، نقدم نقاط التفتيش من البذور = 1 في هذا الرابط. نختار هذا بسبب أفضل أداء متوسطه. يمكنك إلغاء ضغط الملف الذي تم تنزيله في PATH ckpts/pretrain_model/ ، وتعيين --pt_seed 1 عند استخدام finetune.py للاستفادة من نقاط التفتيش المقدمة بدقة.
يرجى الاتصال [email protected] أو فتح مشكلة إذا كانت لديك أسئلة.
إذا وجدت أن الريبو مفيد لبحثك ، فيرجى الاستشهاد بالورقة الأصلية بشكل صحيح.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}يعتمد هذا المستودع على قاعدة بيانات OFA و PYG و OGB و VQ. شكرا لمشاركتهم!


