flash attention
v2.7.0
يوفر هذا المستودع التنفيذ الرسمي لـ Flashattention و Flashattention-2 من الأوراق التالية.
Flashattention: اهتمام سريع وفعال الذاكرة مع الوعي IO
Tri Dao ، Daniel Y. Fu ، Stefano Ermon ، Atri Rudra ، Christopher Ré
ورقة: https://arxiv.org/abs/2205.14135
مقالة IEEE Spectrum حول تقديمنا إلى معيار MLPERF 2.0 باستخدام Flashattention. 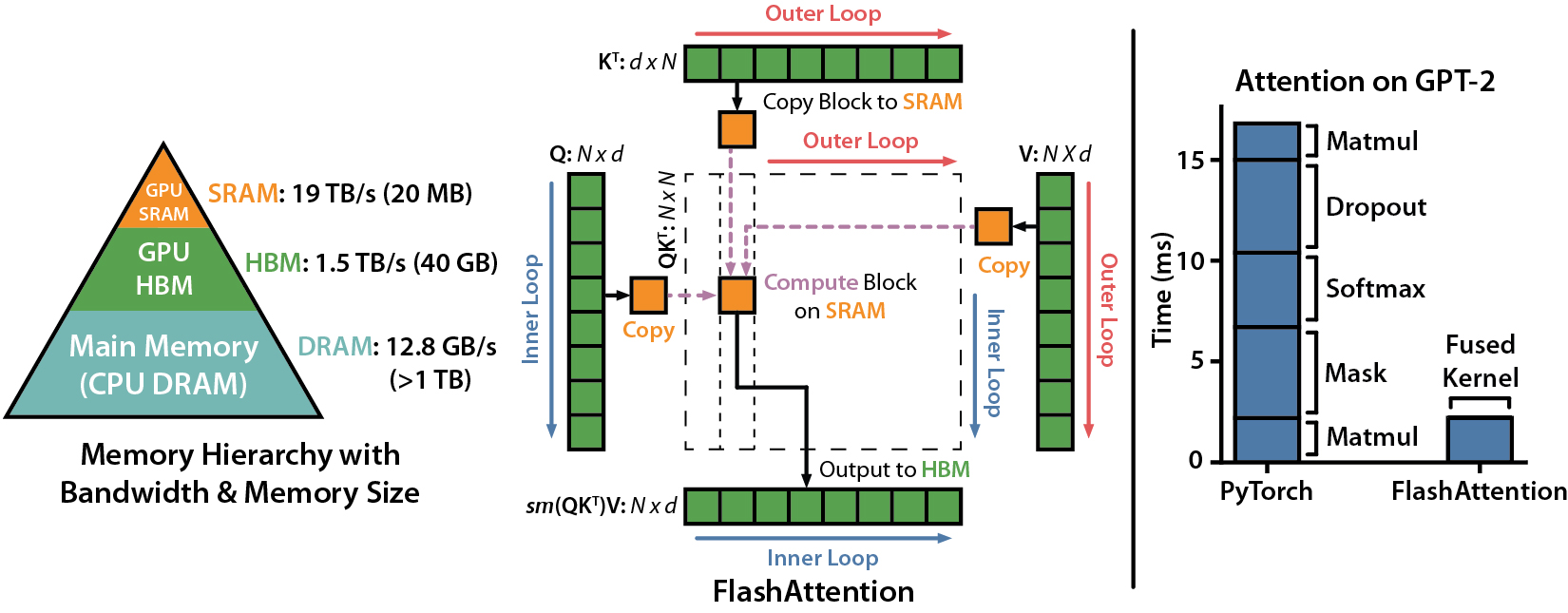
Flashattention-2: اهتمام أسرع مع التوازي الأفضل وتقسيم العمل
تري داو
ورقة: https://tridao.me/publications/flash2/flash2.pdf

لقد كنا سعداء للغاية برؤية Flashattention يتم تبنيها على نطاق واسع في مثل هذا الوقت القصير بعد إصدارها. تحتوي هذه الصفحة على قائمة جزئية من الأماكن التي يتم فيها استخدام Flashattention.
Flashattention و Flashattention-2 مجانيون في الاستخدام والتعديل (انظر الترخيص). يرجى الاستشهاد والائتمان flashattention إذا كنت تستخدمه.
تم تحسين Flashattention-3 ل GPUs Hopper (على سبيل المثال H100).
blogpost: https://tridao.me/blog/2024/flash3/
ورقة: https://tridao.me/publications/flash3/flash3.pdf
هذا إصدار تجريبي للاختبار / القياس قبل أن ندمج ذلك مع بقية الريبو.
صدر حاليا:
المتطلبات: H100 / H800 GPU ، CUDA> = 12.3.
في الوقت الحالي ، نوصي بشدة CUDA 12.3 للحصول على أفضل أداء.
للتثبيت:
cd hopper
python setup.py installلتشغيل الاختبار:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.pyمتطلبات:
packaging Python Package ( pip install packaging )ninja ( pip install ninja ) * * تأكد من تثبيت ninja وأنه يعمل بشكل صحيح (على سبيل المثال ninja --version ثم echo $? يجب إرجاع رمز الخروج 0). إذا لم يكن (في بعض الأحيان ( ninja --version ثم echo $? إرجاع رمز خروج غير صفري) ، قم بإلغاء التثبيت ثم أعد تثبيت ninja ( pip uninstall -y ninja && pip install ninja ). بدون ninja ، يمكن أن يستغرق التجميع وقتًا طويلاً جدًا (2H) لأنه لا يستخدم نوى وحدة المعالجة المركزية المتعددة. مع تجميع ninja يستغرق 3-5 دقائق على جهاز 64 نواة باستخدام مجموعة أدوات CUDA.
للتثبيت:
pip install flash-attn --no-build-isolationبدلاً من ذلك ، يمكنك التجميع من المصدر:
python setup.py install إذا كان لدى جهازك أقل من 96 جيجابايت من ذاكرة الوصول العشوائي والكثير من نوى وحدة المعالجة المركزية ، فقد يدير ninja الكثير من وظائف التجميع الموازية التي يمكن أن تستنفد كمية ذاكرة الوصول العشوائي. للحد من عدد وظائف التجميع المتوازية ، يمكنك تعيين متغير البيئة MAX_JOBS :
MAX_JOBS=4 pip install flash-attn --no-build-isolation الواجهة: src/flash_attention_interface.py
متطلبات:
نوصي بحاوية Pytorch من Nvidia ، والتي لديها جميع الأدوات المطلوبة لتثبيت Flashattention.
تدعم Flashattention-2 مع CUDA حاليًا:
يستخدم إصدار ROCM Composable_Kernel كأحد الخلفية. ويوفر تنفيذ flashattention -2.
متطلبات:
نوصي بحاوية Pytorch من ROCM ، والتي لديها جميع الأدوات المطلوبة لتثبيت Flashattention.
تدعم Flashattention-2 مع ROCM حاليًا:
تنفذ الوظائف الرئيسية انتباه منتج DOT المحجوز (softmax (q @ k^t * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""لمعرفة كيفية استخدام هذه الوظائف في طبقة اهتمام متعددة الرأس (والتي تشمل إسقاط QKV ، وإسقاط الإخراج) ، راجع تطبيق MHA.
الترقية من Flashattention (1.x) إلى Flashattention-2
تم إعادة تسمية هذه الوظائف:
flash_attn_unpadded_func -> flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func -> flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func -> flash_attn_varlen_kvpacked_funcإذا كان للمدخلات نفس أطوال التسلسل في نفس الدفعة ، فسيكون استخدام هذه الوظائف بشكل أبسط وأسرع:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )إذا كان SEQLEN_Q! = SEQLEN_K وسببي = صحيح ، يتم محاذاة القناع السببي إلى الركن الأيمن السفلي من مصفوفة الانتباه ، بدلاً من الزاوية العلوية اليسرى.
على سبيل المثال ، إذا كان seqlen_q = 2 و seqlen_k = 5 ، القناع السببي (1 = الحفاظ ، 0 = ملثمين) هو:
v2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
إذا كان seqlen_q = 5 و seqlen_k = 2 ، فإن القناع السببي هو:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
إذا كان صف القناع صفرًا ، فسيكون الإخراج صفرًا.
قم بتحسين الاستدلال (فك التشفير التكراري) عندما يكون للاستعلام طول تسلسل صغير جدًا (على سبيل المثال ، طول تسلسل الاستعلام = 1). عنق الزجاجة هنا هو تحميل ذاكرة التخزين المؤقت KV بأسرع وقت ممكن ، ونقسم التحميل عبر كتل الخيوط المختلفة ، مع kernel منفصلة لدمج النتائج.
راجع الوظيفة flash_attn_with_kvcache مع المزيد من الميزات للاستدلال (أداء التضمين الدوار ، وتحديث ذاكرة التخزين المؤقت KV في مكان).
بفضل فريق Xformers ، وخاصة دانييل هاززا ، على هذا التعاون.
تنفيذ اهتمام النافذة المنزلق (أي الاهتمام المحلي). بفضل MISTRAL AI وخاصة تيموثي Lacroix لهذه المساهمة. تم استخدام نافذة انزلاق في نموذج 7B Mistral.
تنفيذ alibi (Press et al. ، 2021). بفضل Sanghun Cho من Kakao Brain على هذه المساهمة.
تنفيذ تمريرة متخلفة حتمية. بفضل المهندسين من ميتوان على هذه المساهمة.
دعم ذاكرة التخزين المؤقت KV (أي ، Pagedattention). بفضل beginlner لهذه المساهمة.
دعم الانتباه مع SoftCapping ، كما هو مستخدم في نماذج GEMMA-2 و Grok. بفضل narsil و @lucidRains لهذه المساهمة.
بفضل @ani300 لهذه المساهمة.
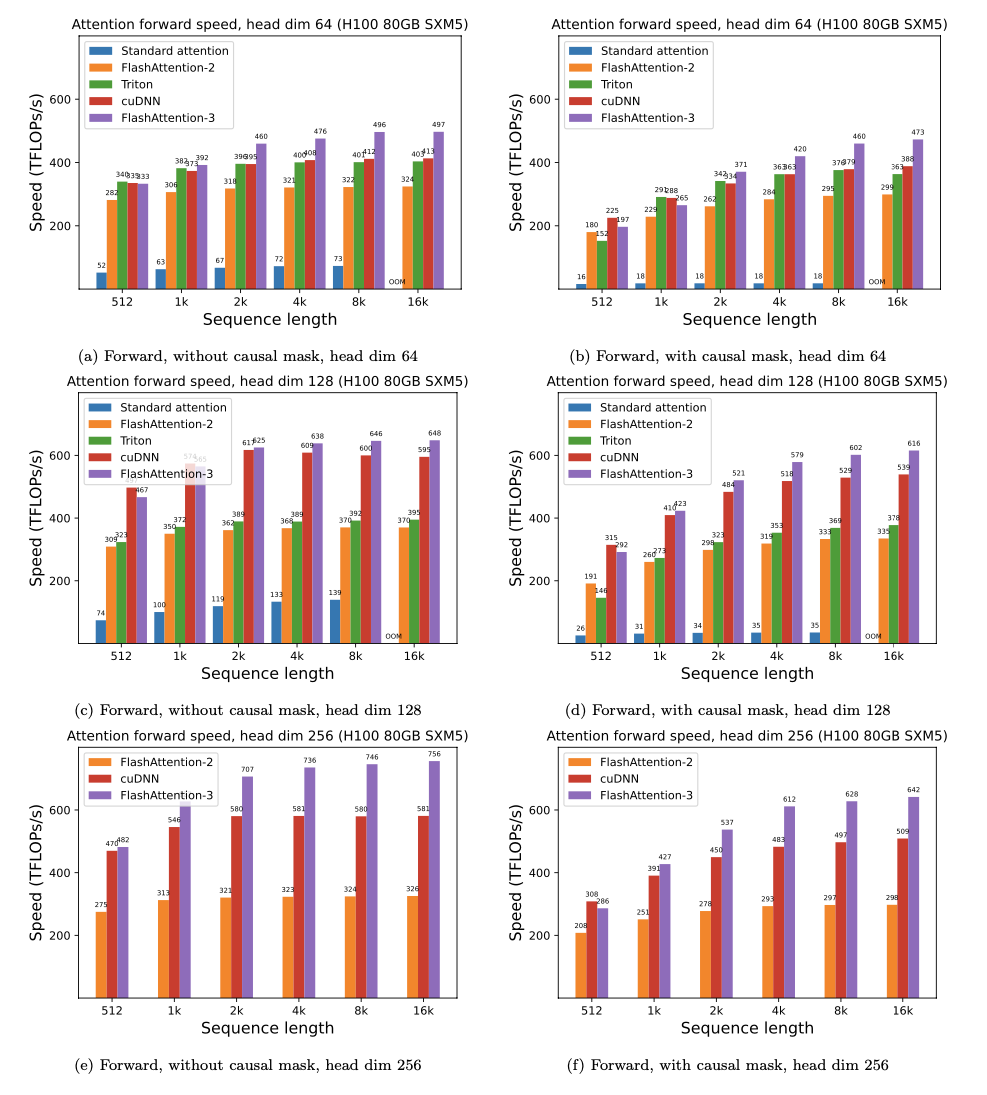
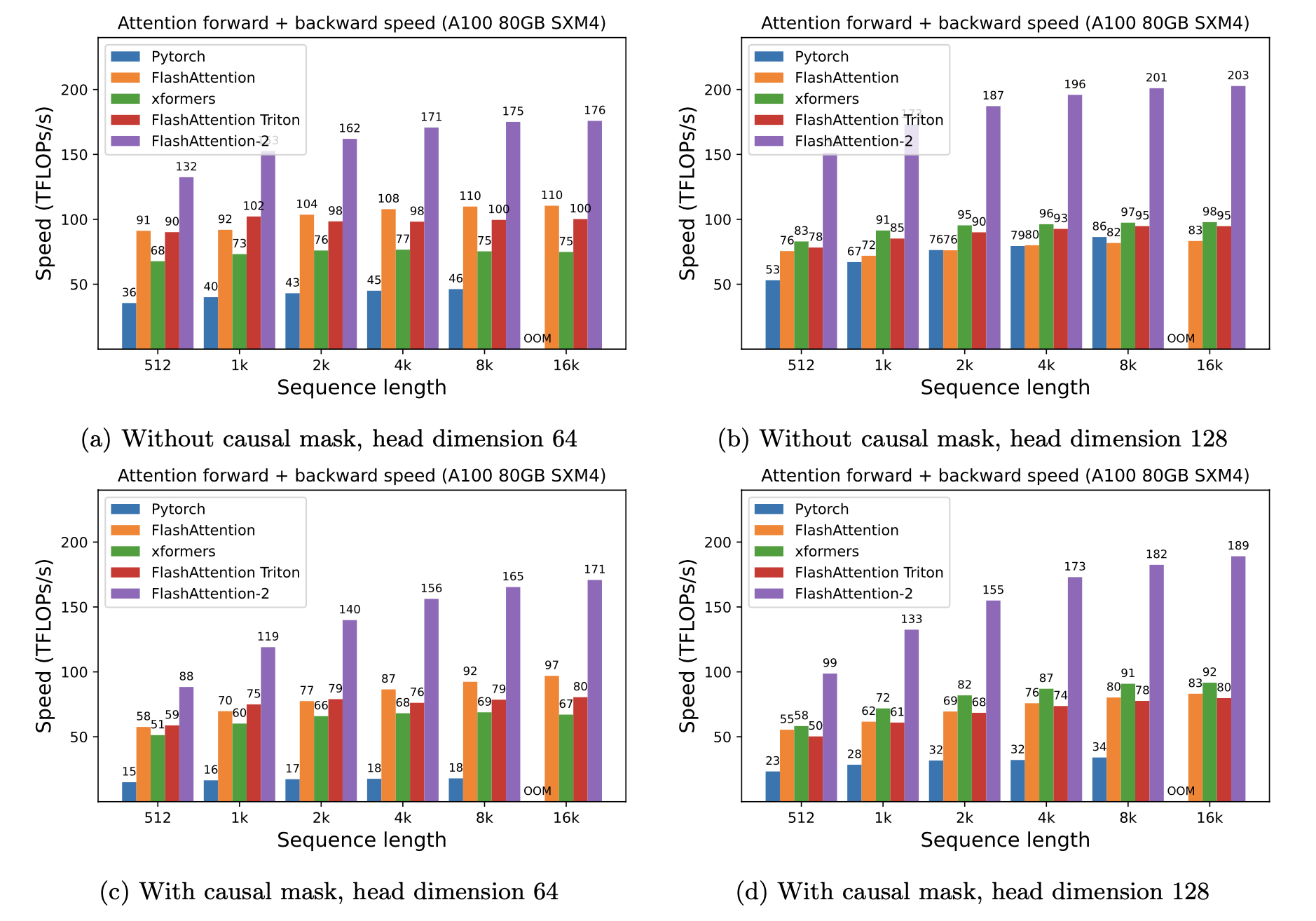
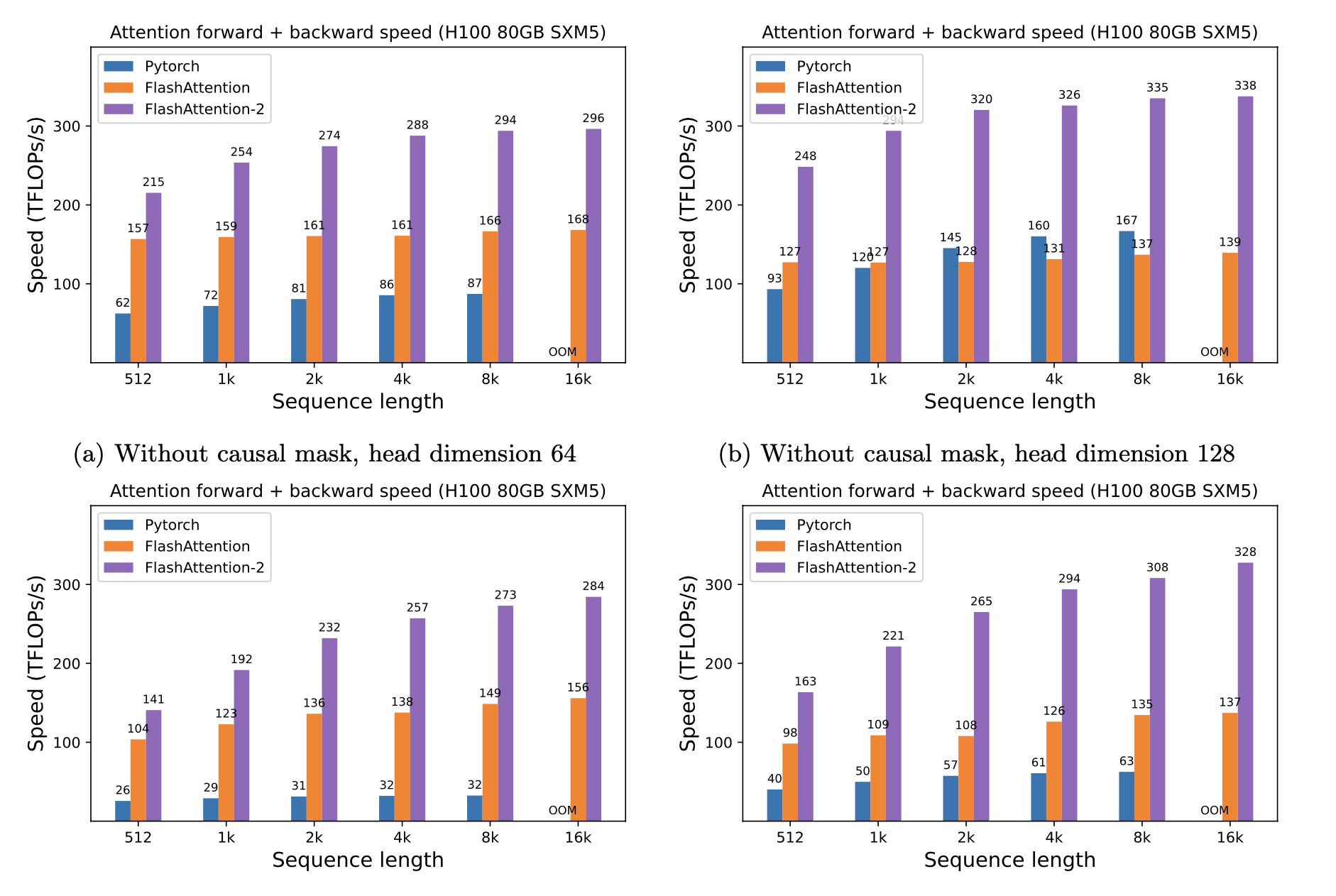
نقدم Speedup المتوقعة (تم تجميعها إلى الأمام + المرور للخلف) وتوفير الذاكرة من استخدام Flashattention مقابل الاهتمام القياسي Pytorch ، اعتمادًا على طول التسلسل ، على وحدات معالجة الرسومات المختلفة (تعتمد التسريع على عرض النطاق الترددي للذاكرة - نرى المزيد من التسريع على ذاكرة GPU أبطأ).
لدينا حاليًا معايير لهذا وحدات معالجة الرسومات:
نعرض تسريع Flashattention باستخدام هذه المعلمات:
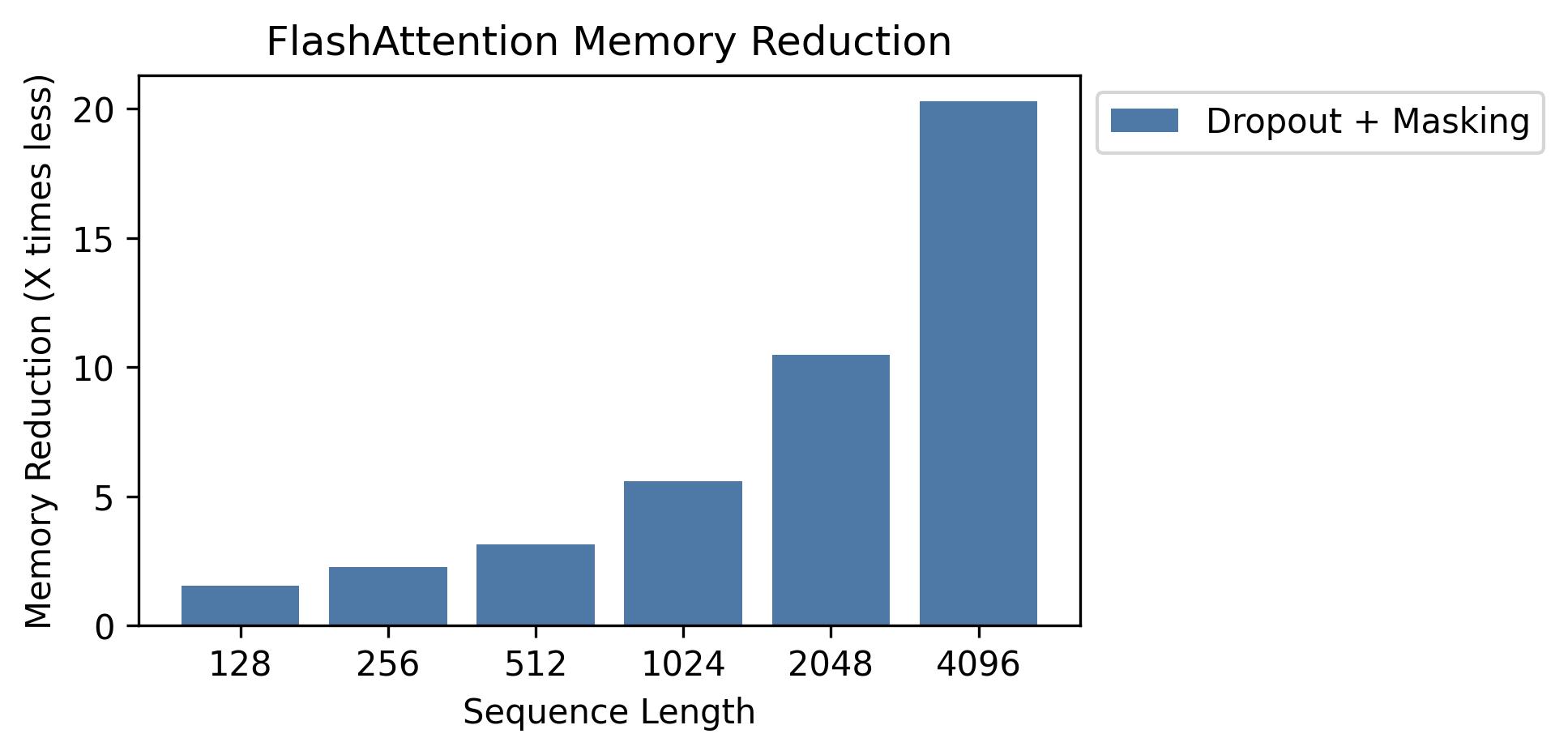
نعرض توفير الذاكرة في هذا الرسم البياني (لاحظ أن بصمة الذاكرة هي نفسها بغض النظر عما إذا كنت تستخدم التسرب أو التقنيع). تتناسب مدخرات الذاكرة مع طول التسلسل - نظرًا لأن الاهتمام القياسي له ذاكرة تربيعية في طول التسلسل ، في حين أن Flashattention لها الذاكرة الخطية في طول التسلسل. نرى توفير 10x الذاكرة بطول تسلسل 2K ، و 20x في 4K. نتيجة لذلك ، يمكن أن تتوسع Flashattention إلى أطوال تسلسل أطول بكثير.
لقد أصدرنا تطبيق نموذج GPT الكامل. نحن نقدم أيضًا تطبيقات محسّنة للطبقات الأخرى (على سبيل المثال ، MLP ، Layernorm ، فقدان الإدخال المتقاطع ، التضمين الدوار). بشكل عام ، يسرع هذا التدريب بمقدار 3-5x مقارنة بالتنفيذ الأساسي من Huggingface ، حيث يصل إلى 225 TFLOPS/SEC لكل A100 ، أي ما يعادل 72 ٪ من استخدام النماذج (لا نحتاج إلى أي تفتيش تنشيط).
ندرج أيضًا برنامج تدريب لتدريب GPT2 على OpenWebText و GPT3 على الوبر.
لدى Phil Tillet (Openai) تنفيذ تجريبي لـ Flashattention في Triton: https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
نظرًا لأن Triton هي لغة ذات مستوى أعلى من CUDA ، فقد يكون من الأسهل فهمها وتجربة. الترميزات في تطبيق Triton أقرب أيضًا إلى ما هو مستخدم في ورقتنا.
لدينا أيضًا تنفيذ تجريبي في Triton يدعم تحيز الانتباه (مثل Alibi): https://github.com/dao-ailab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
نختبر أن Flashattention ينتج نفس الإخراج والتدرج كتطبيق مرجعي ، حتى بعض التسامح العددي. على وجه الخصوص ، نتحقق من أن الحد الأقصى للخطأ العددي في الفلاش هو على الأكثر ضعف الخطأ العددي لتنفيذ خط الأساس في Pytorch (لأبعاد الرأس المختلفة ، دخول DTYPE ، طول التسلسل ، السببية / غير العجلة).
لتشغيل الاختبارات:
pytest -q -s tests/test_flash_attn.pyتم اختبار هذا الإصدار الجديد من Flashattention-2 على عدة طرز على طراز GPT ، ومعظمها على وحدات معالجة الرسومات A100.
إذا واجهت الأخطاء ، يرجى فتح مشكلة github!
لتشغيل الاختبارات:
pytest tests/test_flash_attn_ck.pyإذا كنت تستخدم قاعدة البيانات هذه ، أو وجدت عملنا ذا قيمة أخرى ، فيرجى الاستشهاد:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


