vision_transformer
1.0.0
في هذا المستودع نطلق نماذج من الأوراق
تم تدريب النماذج مسبقًا على مجموعات بيانات ImageNet و ImageNet-21K. نحن نقدم الرمز لضبط النماذج التي تم إصدارها في Jax/Flax.
تم تدريب النماذج من قاعدة قاعدة الشفرة هذه في الأصل على https://github.com/google-research/big_vision/ حيث يمكنك العثور على رمز أكثر تقدماً (على سبيل المثال التدريب متعدد المضيف) ، بالإضافة إلى بعض البرامج النصية التدريبية الأصلية (على سبيل المثال تكوين /vit_i21k.py للتدريب المسبق لـ VIT ، أو تكوين/transfer.py لنقل نموذج).
جدول المحتويات:
أدناه Colabs تشغيل كل من معالجة وحدات معالجة الرسومات ، و TPUS (8 نوى ، موازاة البيانات).
يوضح أول كولاب رمز Jax لمحولات الرؤية وخلاطات MLP. يتيح لك هذا colab تحرير الملفات من المستودع مباشرة في Colab UI ، ولديه خلايا كولاب شرحها التي تمشيك عبر الكود خطوة بخطوة ، وتتيح لك التفاعل مع البيانات.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
يتيح لك Colab الثاني استكشاف محول الرؤية> 50K ونقاط التفتيش الهجينة التي تم استخدامها لإنشاء بيانات الورقة الثالثة "كيفية تدريبك؟ ...". يتضمن COLAB رمزًا لاستكشاف ونقاط التفتيش وتحديده ، وللاستفادة من كل من رمز JAX من هذا الريبو ، وكذلك باستخدام مكتبة timm Pytorch الشهيرة التي يمكنها تحميل نقاط التفتيش هذه مباشرةً أيضًا. لاحظ أن حفنة من النماذج متاحة أيضًا مباشرة من TF-HUB: Sayakpaul/Collections/Vision_Transformer (المساهمة الخارجية من قبل Sayak Paul).
يتيح لك Colab الثاني أيضًا ضبط نقاط التفتيش على أي مجموعة بيانات TFDS ومجموعة البيانات الخاصة بك مع أمثلة في ملفات JPEG الفردية (القراءة مباشرة من Google Drive).
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
ملاحظة : كما هو الحال الآن (6/20/21) ، تدعم Google Colab فقط وحدة معالجة الرسومات (NVIDIA TESLA T4) ، و TPUS (حاليًا TPUV2-8) ترتبط بشكل غير مباشر بـ Colab VM والتواصل عبر الشبكة البطيئة ، مما يؤدي إلى Pretty Pretty سرعة التدريب السيئة. عادةً ما ترغب في إعداد آلة مخصصة إذا كان لديك كمية غير تافهة من البيانات لضبطها. لمزيد من التفاصيل ، راجع قسم التشغيل على السحابة.
تأكد من أن لديك Python>=3.10 مثبت على جهازك.
تثبيت تبعيات Jax و Python عن طريق التشغيل:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
للحصول على إصدارات أحدث من JAX ، اتبع الإرشادات المقدمة في المستودع المقابل المرتبط هنا. لاحظ أن تعليمات التثبيت الخاصة بوحدة المعالجة المركزية و GPU و TPU تختلف قليلاً.
قم بتثبيت Flaxformer ، اتبع الإرشادات المقدمة في المستودع المقابل المرتبط هنا.
لمزيد من التفاصيل ، ارجع إلى القسم الذي يعمل على السحابة أدناه.
يمكنك تشغيل صقل النموذج الذي تم تنزيله على مجموعة البيانات المثيرة للاهتمام. تشترك جميع النماذج في واجهة سطر الأوامر نفسها.
على سبيل المثال ، لضبط VIT-B/16 (تم تدريبه مسبقًا على ImageNet21K) على CIFAR10 (لاحظ كيف نحدد b16,cifar10 كوسائط للتكوين ، وكيف نوجه الكود للوصول إلى النماذج مباشرة من دلو GCS بدلاً من تنزيلها أولاً في الدليل المحلي):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'من أجل ضبط خلاط/16 (تم تدريبه مسبقًا على ImageNet21k) على CIFAR10:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' تمت إضافة الورقة "كيفية تدريبك؟ ..." ، وهي نقاط تفتيش 50k التي يمكنك ضبطها باستخدام تكوين configs/augreg.py . عندما تحدد فقط اسم النموذج (قيمة config.name من configs/model.py ) ، يتم اختيار أفضل نقطة تفتيش I21K عن طريق دقة التحقق من الصحة في المنبع (نقطة التفتيش "الموصى بها" ، انظر القسم 4.5 من الورقة). لتحسين عقلك أي نموذج تريد استخدامه ، إلقاء نظرة على الشكل 3 في الورقة. من الممكن أيضًا اختيار نقطة تفتيش مختلفة (انظر Colab vit_jax_augreg.ipynb ) ثم حدد القيمة من عمود filename أو adapt_filename ، والذي يتوافق مع أسماء الملفات دون .npz من gs://vit_models/augreg .
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 حاليًا ، سيقوم الرمز تلقائيًا بتنزيل مجموعات بيانات CIFAR-10 و CIFAR-100. يمكن دمج مجموعات البيانات العامة أو المخصصة بسهولة ، باستخدام مكتبة مجموعات بيانات TensorFlow. لاحظ أنك ستحتاج أيضًا إلى تحديث vit_jax/input_pipeline.py لتحديد بعض المعلمات حول أي مجموعة بيانات مضافة.
لاحظ أن الكود الخاص بنا يستخدم جميع وحدات معالجة الرسومات/TPU المتاحة للضبط.
للاطلاع على قائمة مفصلة بجميع الأعلام المتاحة ، قم بتشغيل python3 -m vit_jax.train --help .
ملاحظات على الذاكرة:
--config.accum_steps=8 -بدلاً من ذلك ، يمكنك أيضًا تقليل- --config.batch=512 (وتقليل- --config.base_lr وفقًا لذلك).--config.shuffle_buffer=50000 . بقلم Alexey Dosovitskiy*† ، Lucas Beyer*، Alexander Kolesnikov*، Dirk Weissenborn*، Xiaohua Zhai*، Thomas Unterthiner ، Mostafa Dehghani ، Matthias Minderer ، Georg Heigold ، Sylvain Gelly ، Jakob Uszkoreit and Neil Houlsby*.
(*) مساهمة تقنية متساوية ، (†) تقديم المشورة المتساوية.
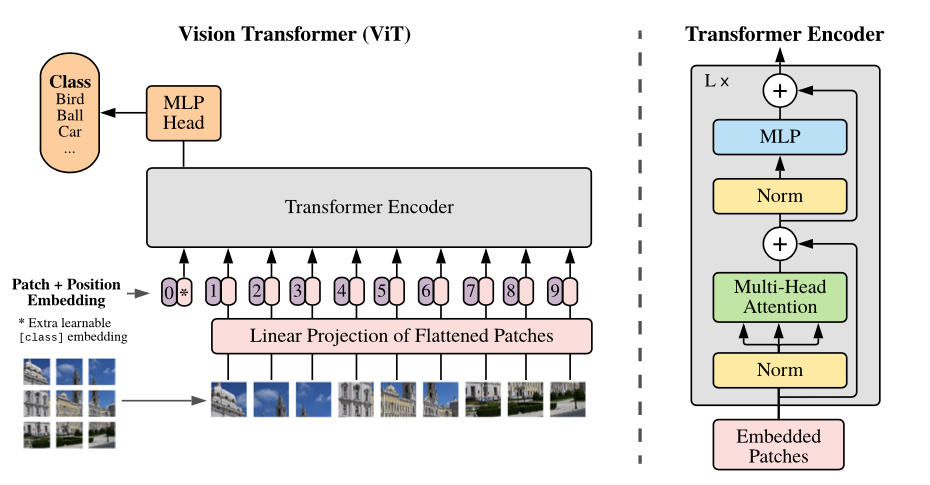
نظرة عامة على النموذج: نقسم صورة إلى تصحيحات ذات حجم ثابت ، ندمج كل منها خطيًا ، وإضافة تضمينات الموضع ، ونغذي التسلسل الناتج عن المتجهات إلى تشفير محول قياسي. من أجل إجراء التصنيف ، نستخدم النهج القياسي لإضافة "رمز تصنيف" قابل للتعلم إضافي إلى التسلسل.
نحن نقدم مجموعة متنوعة من نماذج VIT في دلاء GCS المختلفة. يمكن تنزيل النماذج باستخدام مثل:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
تتوافق أسماء الملفات النموذجية (بدون امتداد .npz ) مع config.model_name في vit_jax/configs/models.py
gs://vit_models/imagenet21k نماذج تم تدريبها مسبقًا على ImageNet-21K.gs://vit_models/imagenet21k+imagenet2012 نماذج تم تدريبها مسبقًا على ImageNet-21K وضبطها على ImageNet.gs://vit_models/augreg تم تدريب النماذج مسبقًا على ImageNet-21K ، بتطبيق كميات متفاوتة من Augreg. تحسين الأداء.gs://vit_models/sam - نماذج تم تدريبها مسبقًا على ImageNet مع SAM.gs://vit_models/gsam - نماذج تم تدريبها مسبقًا على ImageNet مع GSAM.نوصي باستخدام نقاط التفتيش التالية ، المدربين مع Augreg التي لديها أفضل مقاييس ما قبل التدريب:
| نموذج | نقطة تفتيش تدريب قبل | مقاس | نقطة تفتيش ضبطها | دقة | IMG/ثانية | دقة ImageNet |
|---|---|---|---|---|---|---|
| ل/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85.59 ٪ |
| ب/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85.49 ٪ |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83.73 ٪ |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85.99 ٪ |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83.85 ٪ |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78.22 ٪ |
| ب/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83.59 ٪ |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79.58 ٪ |
| R+Ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 MIB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75.40 ٪ |
تم تكرار نتائج الورق الأصلي VIT (https://arxiv.org/abs/2010.11929) باستخدام النماذج من gs://vit_models/imagenet21k :
| نموذج | مجموعة البيانات | التسرب = 0.0 | التسرب = 0.1 |
|---|---|---|---|
| R50+VIT-B_16 | CIFAR10 | 98.72 ٪ ، 3.9H (A100) ، TB.DEV | 98.94 ٪ ، 10.1H (V100) ، TB.Dev |
| R50+VIT-B_16 | CIFAR100 | 90.88 ٪ ، 4.1H (A100) ، TB.DEV | 92.30 ٪ ، 10.1H (V100) ، TB.Dev |
| R50+VIT-B_16 | ImageNet2012 | 83.72 ٪ ، 9.9h (A100) ، TB.Dev | 85.08 ٪ ، 24.2H (V100) ، TB.Dev |
| VIT-B_16 | CIFAR10 | 99.02 ٪ ، 2.2H (A100) ، TB.Dev | 98.76 ٪ ، 7.8H (V100) ، TB.Dev |
| VIT-B_16 | CIFAR100 | 92.06 ٪ ، 2.2H (A100) ، TB.Dev | 91.92 ٪ ، 7.8H (V100) ، TB.Dev |
| VIT-B_16 | ImageNet2012 | 84.53 ٪ ، 6.5h (A100) ، TB.Dev | 84.12 ٪ ، 19.3H (V100) ، TB.Dev |
| VIT-B_32 | CIFAR10 | 98.88 ٪ ، 0.8H (A100) ، TB.DEV | 98.75 ٪ ، 1.8H (V100) ، TB.Dev |
| VIT-B_32 | CIFAR100 | 92.31 ٪ ، 0.8H (A100) ، TB.Dev | 92.05 ٪ ، 1.8H (V100) ، TB.Dev |
| VIT-B_32 | ImageNet2012 | 81.66 ٪ ، 3.3H (A100) ، TB.Dev | 81.31 ٪ ، 4.9H (V100) ، TB.Dev |
| VIT-L_16 | CIFAR10 | 99.13 ٪ ، 6.9H (A100) ، TB.Dev | 99.14 ٪ ، 24.7H (V100) ، TB.Dev |
| VIT-L_16 | CIFAR100 | 92.91 ٪ ، 7.1H (A100) ، TB.Dev | 93.22 ٪ ، 24.4h (V100) ، TB.Dev |
| VIT-L_16 | ImageNet2012 | 84.47 ٪ ، 16.8H (A100) ، TB.Dev | 85.05 ٪ ، 59.7H (V100) ، TB.Dev |
| VIT-L_32 | CIFAR10 | 99.06 ٪ ، 1.9H (A100) ، TB.Dev | 99.09 ٪ ، 6.1H (V100) ، TB.Dev |
| VIT-L_32 | CIFAR100 | 93.29 ٪ ، 1.9H (A100) ، TB.Dev | 93.34 ٪ ، 6.2H (V100) ، TB.Dev |
| VIT-L_32 | ImageNet2012 | 81.89 ٪ ، 7.5h (A100) ، TB.Dev | 81.13 ٪ ، 15.0H (V100) ، TB.Dev |
نود أيضًا التأكيد على أنه يمكن تحقيق النتائج عالية الجودة من خلال جداول تدريب أقصر وتشجيع مستخدمي الكود لدينا على اللعب مع المعلمات المفرطة لدقة المفاضلة والميزانية الحسابية. يتم عرض بعض الأمثلة لمجموعات بيانات CIFAR-10/100 في الجدول أدناه.
| المنبع | نموذج | مجموعة البيانات | Total_steps / tradup_steps | دقة | وقت الحائط | وصلة |
|---|---|---|---|---|---|---|
| ImageNet21k | VIT-B_16 | CIFAR10 | 500 /50 | 98.59 ٪ | 17m | Tensorboard.dev |
| ImageNet21k | VIT-B_16 | CIFAR10 | 1000 /100 | 98.86 ٪ | 39m | Tensorboard.dev |
| ImageNet21k | VIT-B_16 | CIFAR100 | 500 /50 | 89.17 ٪ | 17m | Tensorboard.dev |
| ImageNet21k | VIT-B_16 | CIFAR100 | 1000 /100 | 91.15 ٪ | 39m | Tensorboard.dev |
بقلم إيليا تولستيخين*، نيل هولسبي*، ألكساندر كولسنيكوف*، لوكاس باير*، شياووا تشاي ، توماس يونترثينر ، جيسيكا يونغ ، أندرياس شتاينر ، دانييل كيسرس ، جاكوب أوزيكوريت ، ماريو لوسيتش ، ألكسي دوسوفيتسكي.
(*) مساهمة متساوية.
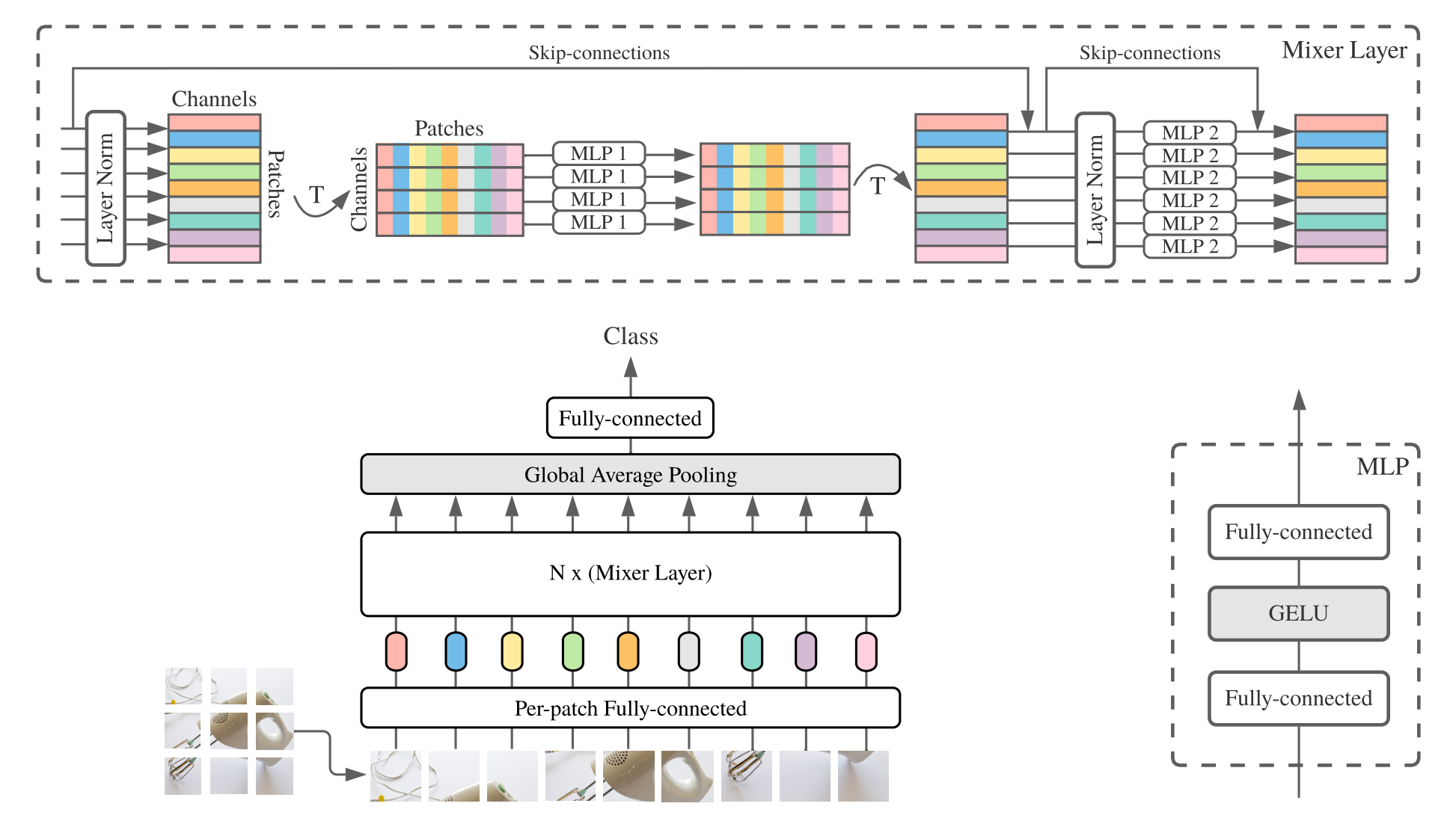
يتكون MLP-Mixer ( الخلاط لفترة قصيرة) من تضمينات خطية لكل نقطة وطبقات خلاط ورأس مصنف. تحتوي طبقات الخلاط على MLP المبللة الرمزية و MLP واحد MLP ، كل منها يتكون من طبقتين متصلتين بالكامل وخطية جيلو. وتشمل المكونات الأخرى: Skip-Connections و Strperout و Linear Classifier Head.
للتثبيت ، اتبع نفس الخطوات على النحو الوارد أعلاه.
نحن نقدم نماذج Mixer-B/16 و Mixer-L/16 التي تم تدريبها مسبقًا على مجموعات بيانات ImageNet و ImageNet-21K. يمكن العثور على التفاصيل في الجدول 3 من ورق الخلاط. يمكن العثور على جميع النماذج في:
https://console.cloud.google.com/storage/mixer_models/
لاحظ أن هذه النماذج متاحة أيضًا مباشرة من TF-HUB: Sayakpaul/Collections/MLP-Mixer (مساهمة خارجية من قبل Sayak Paul).
قمنا بتشغيل رمز الضبط على جهاز Google Cloud مع أربعة من وحدات معالجة الرسومات V100 مع معلمات التكيف الافتراضية من هذا المستودع. ها هي النتائج:
| المنبع | نموذج | مجموعة البيانات | دقة | wall_clock_time | وصلة |
|---|---|---|---|---|---|
| ImageNet | خلاط ب/16 | CIFAR10 | 96.72 ٪ | 3.0H | Tensorboard.dev |
| ImageNet | Mixer-L/16 | CIFAR10 | 96.59 ٪ | 3.0H | Tensorboard.dev |
| ImageNet-21k | خلاط ب/16 | CIFAR10 | 96.82 ٪ | 9.6H | Tensorboard.dev |
| ImageNet-21k | Mixer-L/16 | CIFAR10 | 98.34 ٪ | 10.0H | Tensorboard.dev |
للحصول على تفاصيل ، راجع منشور مدونة Google AI مضاءة: إضافة فهم اللغة إلى نماذج الصور ، أو اقرأ ورقة CVPR "LIT: ZERO-Shot Transfer مع ضبط النص المقفل" (https://arxiv.org/abs/2111.07991 ).
لقد نشرنا نموذج محول B/16 مع دقة ImageNet Zeroshot بنسبة 72.1 ٪ ، ونموذج L/16-large مع دقة ImageNet Zeroshot بنسبة 75.7 ٪. لمزيد من التفاصيل حول هذه النماذج ، يرجى الرجوع إلى بطاقة Model Lit.
نحن نقدم عرضًا تجريبيًا في المستعرض مع ترميزات نصية صغيرة للاستخدام التفاعلي (يجب أن تعمل النماذج الأصغر على الهاتف الخليوي الحديث):
https://google-research.github.io/vision_transformer/lit/
وأخيراً كولاب لاستخدام نماذج Jax مع كل من ترميز الصور والنص:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
لاحظ أن أيًا من النماذج المذكورة أعلاه يدعم المدخلات متعددة اللغات حتى الآن ، لكننا نعمل على نشر مثل هذه النماذج وسوف نقوم بتحديث هذا المستودع بمجرد توفرها.
يحتوي هذا المستودع فقط على رمز التقييم للنماذج المضاءة. يمكنك العثور على رمز التدريب في مستودع big_vision :
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
نتائج Zeroshot المتوقعة من model_cards/lit.md (لاحظ أن تقييم Zeroshot يختلف قليلاً عن التقييم المبسط في كولاب):
| نموذج | B16B_2 | L16L |
|---|---|---|
| ImageNet Zero-Shot | 73.9 ٪ | 75.7 ٪ |
| ImageNet v2 Zero-Shot | 65.1 ٪ | 66.6 ٪ |
| CIFAR100 صفر | 79.0 ٪ | 80.5 ٪ |
| Pets37 صفر | 83.3 ٪ | 83.3 ٪ |
| RESISC45 صفر | 25.3 ٪ | 25.6 ٪ |
| MS-COCO Captions صورة إلى نص نص | 51.6 ٪ | 48.5 ٪ |
| MS-COCO Captions استرجاع النص إلى صورة | 31.8 ٪ | 31.1 ٪ |
على الرغم من أن كولابز مفيدة للغاية للبدء ، إلا أنك ترغب عادة في التدريب على آلة أكبر مع مسرعات أكثر قوة.
يمكنك استخدام الأوامر التالية لإعداد VM مع وحدات معالجة الرسومات على Google Cloud:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEبدلاً من ذلك ، يمكنك استخدام الأوامر المماثلة التالية لإعداد Cloud VM مع TPUs متصلة بها (أوامر أدناه نسخ من البرنامج التعليمي TPU):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME ثم جلب المستودع وتثبيت التبعيات (بما في ذلك jaxlib مع دعم TPU) كالمعتاد:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateإذا كنت متصلاً بـ VM مع وحدات معالجة الرسومات المرفقة ، فقم بتثبيت Jax والتبعيات الأخرى مع الأمر التالي:
pip install -r vit_jax/requirements.txtإذا كنت متصلاً بـ VM مع TPUs المرفقة ، فقم بتثبيت JAX وتبعيات أخرى مع الأمر التالي:
pip install -r vit_jax/requirements-tpu.txtقم بتثبيت Flaxformer ، اتبع الإرشادات المقدمة في المستودع المقابل المرتبط هنا.
لكل من وحدات معالجة الرسومات و TPUs ، تحقق من أن Jax يمكنه الاتصال مع مسرعات المرفقة مع الأمر:
python -c ' import jax; print(jax.devices()) 'وأخيراً ، قم بتنفيذ أحد الأوامر المذكورة في القسم الذي يصطف نموذجًا.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
بالترتيب الزمني العكسي:
2022-08-18: تمت إضافة طراز Lit-B16B_2 الذي تم تدريبه على 60 ألف خطوة (LIT_B16B: 30K) بدون رأس خطي على جانب الصورة (LIT_B16B: 768) ولديه أداء أفضل.
2022-06-09: أضيفت نماذج VIT و MIXER المدربة من نقطة الصفر باستخدام GSAM على ImageNet دون زيادة بيانات قوية. تتفوق VITs الناتجة على تلك ذات الأحجام المماثلة المدربة باستخدام Adamw Optimizer أو خوارزمية SAM الأصلية ، أو مع زيادة البيانات القوية.
2022-04-14: نماذج مضافة وكولاب للنماذج المضاءة.
2021-07-29: تمت إضافة نماذج Vit-B/8 Augreg (3 نقاط تفتيش في المنبع والتكيف مع الدقة = 224).
2021-07-02: تمت إضافة ورقة "عندما تتفوق محولات الرؤية على Resnets ..."
2021-07-02: تمت إضافة SAM (التقليل من الحدة إلى الحد الأدنى) إلى نقاط تفتيش VIT و MLP-mixer.
2021-06-20: أضافت ورقة "كيفية تدريبك؟ ..." ، وكولاب جديد لاستكشاف نقاط التفتيش التي تم تدريبها مسبقًا و 50 ألفًا المذكورة في الورقة.
2021-06-18: أعيد كتابة هذا المستودع لاستخدام API الكتان الكتاني و ml_collections.ConfigDict للتكوين.
2021-05-19: مع نشر ورقة "كيفية تدريبك؟ ..." ، أضفنا أكثر من 50 كيلو فولت ونماذج هجينة تدربت مسبقًا على ImageNet و ImageNet-21K مع درجات مختلفة من زيادة البيانات وتنظيم النموذج ، وضبطها على ImageNet و Pets37 و Kitti-Distance و CIFAR-100 و RESISC45. تحقق من vit_jax_augreg.ipynb للتنقل هذا الكنز من النماذج! على سبيل المثال ، يمكنك استخدام هذا Colab لجلب أسماء الملفات لنقاط التفتيش الموصى بها مسبقًا والمثقة من عمود i21k_300 من الجدول 3 في الورقة.
2020-12-01: أضاف نموذج R50+VIT-B/16 الهجين (VIT-B/16 أعلى العمود الفقري RESNET-50). عندما تم تجهيزه على ImageNet21K ، يحقق هذا النموذج أداء نموذج L/16 تقريبًا مع أقل من نصف تكلفة التكلفة الحاسوبية. لاحظ أن "R50" تم تعديله إلى حد ما للمتغير B/16: يحتوي Resnet-50 الأصلي على كتل [3،4،6،3] ، كل منها يقلل من دقة الصورة بعامل اثنين. بالاقتران مع جذع RESNET ، فإن هذا سيؤدي إلى تقليل 32x ، لذلك حتى مع حجم التصحيح من (1،1) ، لا يمكن تحقيق متغير VIT-B/16 بعد الآن. لهذا السبب ، نستخدم بدلاً من ذلك [3،4،9] كتل لمتغير R50+B/16.
2020-11-09: أضاف نموذج VIT-L/16.
2020-10-29: تم إضافة نماذج VIT-B/16 و VIT-L/16 على ImageNet-21K ثم تم ضبطها على ImageNet بدقة 224x224 (بدلاً من الافتراضي 384x384). هذه النماذج لها لاحقة "-224" باسمها. من المتوقع أن يحققوا 81.2 ٪ و 82.7 ٪ من أعلى 1 دقة على التوالي.
إصدار مفتوح المصدر أعده أندرياس شتاينر.
ملاحظة: تم تشويه هذا المستودع وتعديله من Google-Research/Big_transfer.
هذا ليس منتج Google الرسمي.


