Face Shape Classification using CNN
1.0.0

هذا هو مشروع تصنيف الصور لتحديد 5 أشكال الوجه الإناث باستخدام الشبكات العصبية التلافيفية (CNN) . أكملت هذا كمشروع Capstone الخاص بي لعلوم البيانات الغامرة مع الجمعية العامة (أكتوبر 2020).
يتم نشر هذا المشروع أيضًا كتطبيق ويب باستخدام Stremlit على Heroku. إذا كنت مهتمًا ، تحقق من شكل وجهك على myfaceshape.herokuapp.com
استنادًا إلى مراجعة المستهلك Deloitte ، يطالب المستهلكون بخبرة أكثر تخصيصًا ، ولكن لا تزال التجربة منخفضة. في صناعة الجمال والأزياء ، يهتم أكثر من 40 ٪ من البالغين الذين تتراوح أعمارهم بين 16 و 39 عامًا بالعرض الشخصي ، في حين أن التجربة هي 10 ٪ إلى 14 ٪ فقط. من بين المهتمين ، حوالي 80 ٪ على استعداد لدفع سعر أعلى بنسبة 10 ٪ على الأقل.
من خلال القدرة على تصنيف أشكال الوجه ، سيمكن العلامات التجارية من تقديم حلول مخصصة لزيادة رضا العملاء ، مع زيادة الهامش من تحديد المواقع المتميزة. مثال على حالات الاستخدام هو:
بالنسبة لهذا المشروع ، سأستخدم نهج التعلم العميق مع الشبكات العصبية التلافيفية (CNN) لتصنيف 5 أشكال مختلفة للوجه أنثى (القلب ، مستطيل ، بيضاوي ، مستدير ، مربع). سيتم اختيار النموذج الذي كان أعلى درجة دقة.
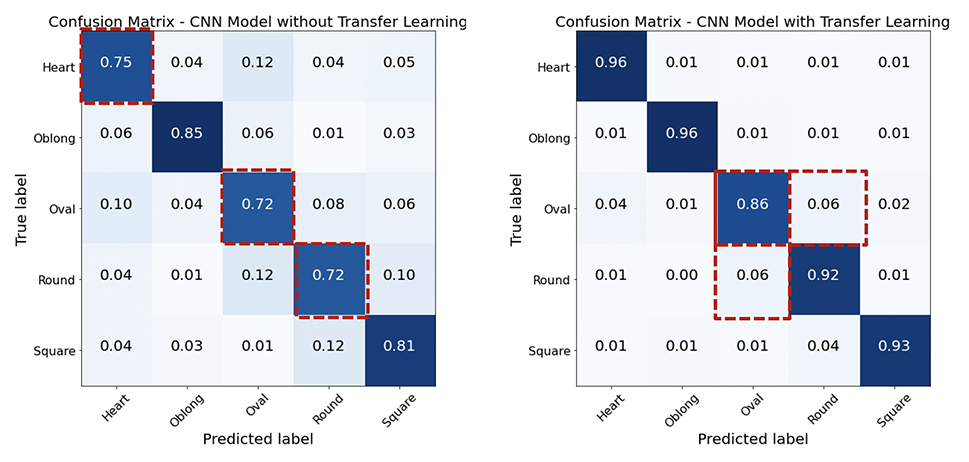
لقد استكشفت مقاربين من CNN عن طريق البناء من التعلم من البداية مقابل Trasfer مع بنية VGG-16 والأوزان التي تم تدريبها مسبقًا من VGGFACE. ساعد نهج التعلم في النقل على زيادة الدقة ، في حين أن شكل الوجه الأكثر سوءًا هو "بيضاوي".
لعبت المعالجة المسبقة للصور أيضًا دورًا مهمًا في الحد من الدقة المتزايدة وزيادة الصحة. برامج التشغيل الرئيسية هي:
مجموعة بيانات شكل الوجه هي مجموعة بيانات من Kaggle بواسطة Niten Lama.
تضم مجموعة البيانات هذه ما مجموعه 5000 صورة للمشاهير الإناث من جميع أنحاء العالم والتي يتم تصنيفها وفقًا لشكل وجهها وهي:
تتكون كل فئة من 1000 صورة (800 للتدريب: 200 للاختبار)
تعتبر المعالجة المسبقة للصور عاملاً حاسماً في تقليل النموذج الذي يتفوق على مجموعة بيانات التدريب ، وزيادة دقة التحقق من الصحة. تم استكشاف الخطوات التالية:
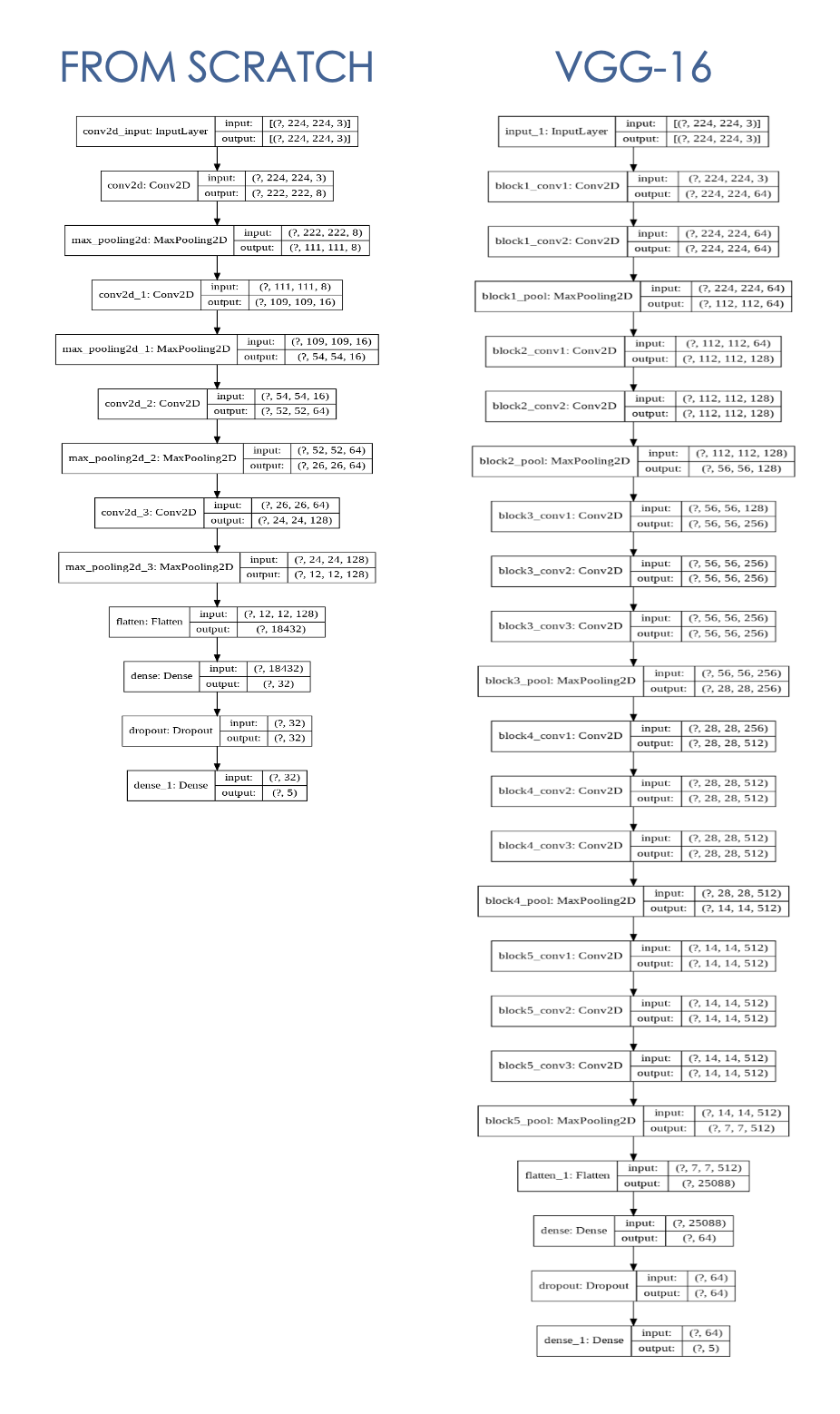
نموذج CNN الذي تم تصميمه من نقطة الصفر مع بيانات تدريب محدودة من 4000 صورة (800 صورة × 5 فئات) ، أقوم بإنشاء النموذج مع 4 طبقات تجميعية + MAX ، وطبقتين كثيفتين (تفاصيل أدناه).
يمكّنني نموذج CNN مع التعلم النقل من استخدام بنية VGG-16 أكثر تعقيدًا ، باستخدام الأوزان التي تم تدريبها مسبقًا من VGGface تم تدريبها على أكثر من 2.6 مليون صورة.
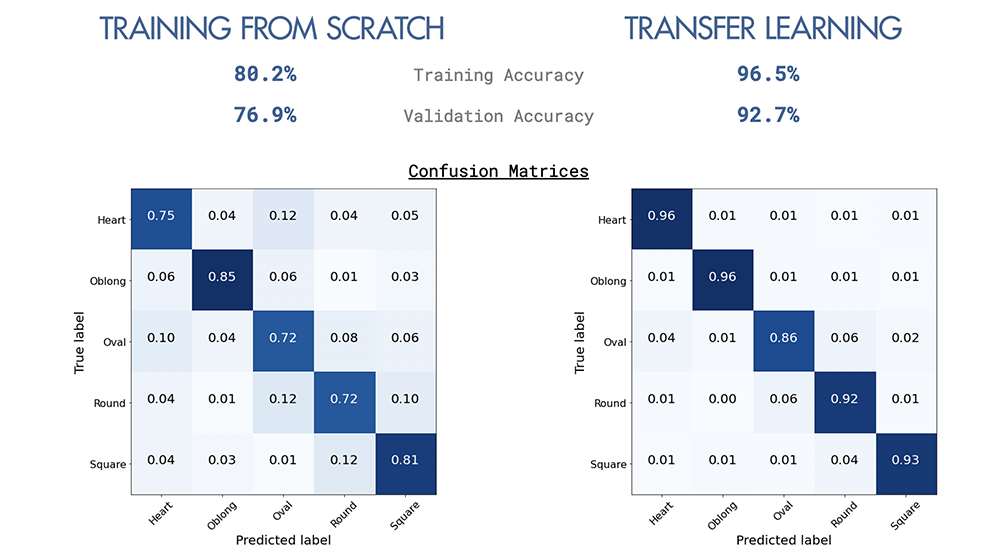
ساعد تعلم النقل على تحسين الدقة بشكل كبير ، من 76.9 ٪ إلى 92.7 ٪ ، بمساعدة الأوزان التي تم تدريبها مسبقًا على مجموعة بيانات أكبر.
من النماذج التي تم إنشاؤها من نقطة الصفر ، تم أداء جميع النماذج بشكل أفضل من خط الأساس بنسبة 20 ٪ (5 فئات متوازنة بـ 20 ٪ لكل منها).
ملخص لجميع النماذج أدناه.

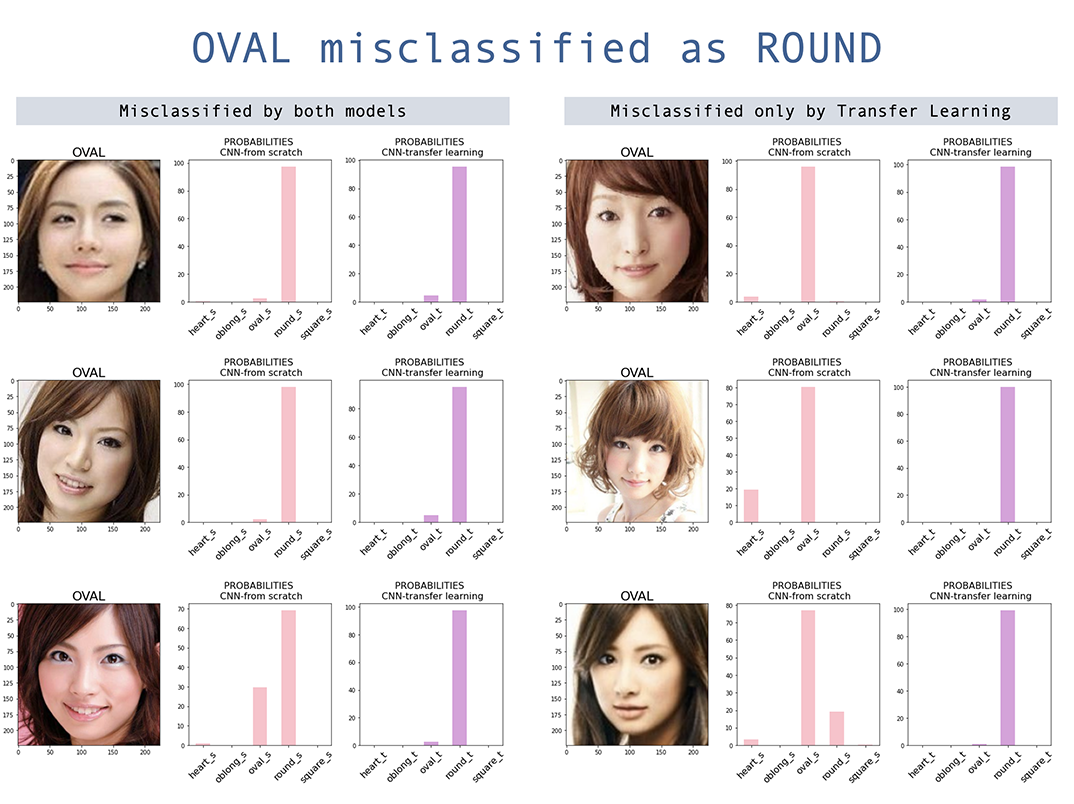
كلا النموذجين لهما أعلى تصنيف على شكل الوجه البيضاوي . على الرغم من أن نموذج التعلم النقل قد أدى إلى تحسين دقة النموذج المبني من نقطة الصفر ، إلا أن البيضاوي لا يزال الأكثر سوءًا ، حيث يتم تصنيف الأغلبية على أنها جولة. ومن المثير للاهتمام ، أن الوجه الدائري أيضًا يسيء تصنيفه في الغالب على أنه بيضاوي ، على الرغم من أن التصنيف الإجمالي لشكل الوجه المستدير منخفض. الالتباس بين البيضاوي والجولة في الغالب الوجوه الآسيوية ، وأكثر من ذلك مع التعلم النقل. هذا على الأرجح لأن الأوزان المسبقة لديها صور آسيوية أقل.