streaming
v0.9.1
لقد قمنا ببناء DreamingDataset لجعل التدريب على مجموعات بيانات كبيرة من التخزين السحابي بأسرع ، رخيصة ، وقابلة للتطوير قدر الإمكان.
إنه مصمم خصيصًا للتدريب متعدد العقدة والموزعة للنماذج الكبيرة-ضمانات الصواب ، والأداء ، وسهولة الاستخدام. الآن ، يمكنك التدريب بكفاءة في أي مكان ، بغض النظر عن موقع بيانات التدريب الخاص بك. ما عليك سوى بث في البيانات التي تحتاجها ، عندما تحتاجها. لمعرفة المزيد حول سبب قيامنا ببناء DreamingDataset ، اقرأ مدونة الإعلان الخاصة بنا.
DreamingDataset متوافق مع أي نوع من البيانات ، بما في ذلك الصور والنص والفيديو والبيانات متعددة الوسائط .
مع دعم لمقدمي التخزين السحابي الرئيسيين (AWS ، OCI ، GCS ، Azure ، Databricks ، وأي متجر كائنات متوافق مع S3 مثل Cloudflare R2 ، CoreWeave ، Backblaze B2 ، وما إلى ذلك) ومصممة كبديل في Pytorch iterabledataset ، تدمج DreamingDataset بسلاسة في سير العمل التدريبي الحالي.

يمكن تثبيت التدفق مع pip :
PIP تثبيت Mosaicml-treaming
قم بتحويل مجموعة البيانات الخام إلى أحد تنسيقات البث المدعومة لدينا:
تنسيق MDS (Shard Data Shard) الذي يمكن أن يشفر وتفكيك أي كائن بيثون
CSV / TSV
JSONL
استيراد numpy مثل npfrom pil import Importfrom Dreaming استيراد mdswriter# الدليل المحلي أو عن بعد لتخزين ملفات الإخراج المضغوطة data_dir = 'path-to-dataset'# A Dictionary Mapping Fields to typescolumns = {'Image': 'jpeg' ، "class": 'int'}# shard compression ، إذا كان anycompression = 'ZSTD'# حفظ العينات كظهور باستخدام mdswriterwith mdswriter (out = data_dir ، أعمدة = أعمدة ، ضغط = ضغط) كـ out: for i in range (10000 (10000 ): عينة = {'image': image.fromarray (np.random.randint (0 ، 256 ، (32 ، 32 ، 3) ، np.uint8)) ، 'class': np.random.randint (10) ،
} out.write (عينة)قم بتحميل مجموعة بيانات الدفق الخاصة بك إلى التخزين السحابي الذي تختاره (AWS أو OCI أو GCP). فيما يلي مثال على تحميل دليل على دلو S3 باستخدام AWS CLI.
$ AWS S3 CP-PATH-TO-DATASET S3: // my-bucket/path-to-dataset
من Torch.Utils.data استيراد dataloaderfrom dreaming استيراد TreamingDataset# المسار البعيد حيث يتم استمرار مجموعة البيانات الكاملة = s3: // my-bucket/path-to-dataset '# dir المحلية حيث يتم تخزين DataSet أثناء التشغيل أثناء التشغيل ='/tmp /path-to-dataset '# إنشاء دفق dataSetDatAset = dreamingDatAset (محلي = محلي ، عن بعد = عن بعد ، خلط ورق اللعب = صحيح) '] cls = sample [' class ']
يمكن العثور على أدلة البدء ، والأمثلة ، ومراجع API ، وغيرها من المعلومات المفيدة في مستنداتنا.
لدينا دروس شاملة لتدريب نموذج على:
CIFAR-10
Facesynthetics
sintheticnlp
لدينا أيضًا رمز بداية لمجموعات البيانات الشائعة التالية ، والتي يمكن العثور عليها في دليل streaming :
| مجموعة البيانات | مهمة | يقرأ | يكتب |
|---|---|---|---|
| Laion-400m | النص والصورة | يقرأ | يكتب |
| ويب | النص والفيديو | يقرأ | يكتب |
| C4 | نص | يقرأ | يكتب |
| enwiki | نص | يقرأ | يكتب |
| كومة | نص | يقرأ | يكتب |
| ADE20K | تجزئة الصور | يقرأ | يكتب |
| CIFAR10 | تصنيف الصور | يقرأ | يكتب |
| كوكو | تصنيف الصور | يقرأ | يكتب |
| ImageNet | تصنيف الصور | يقرأ | يكتب |
لبدء التدريب على مجموعات البيانات هذه:
تحويل البيانات RAW إلى تنسيق .mds باستخدام البرنامج النصي المقابل من دليل convert .
على سبيل المثال:
$ python -M Streaming.multimodal.convert.webvid -in <csv file> -out <mds directory>
استيراد فئة مجموعة البيانات لبدء تدريب النموذج.
من البث.
تجربة بسهولة مع مخاليط مجموعة البيانات مع Stream . يمكن التحكم في أخذ عينات مجموعة البيانات في نسبة (نسبة) أو مطلقة (تكرار أو عينات). أثناء التدفق ، يتم بث مجموعات البيانات المختلفة ، وخلطها ، وخلطها بسلاسة في الوقت المناسب.
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
ميزة فريدة لحلنا: العينات في نفس الترتيب بغض النظر عن عدد وحدات معالجة الرسومات أو العقد أو عمال وحدة المعالجة المركزية. هذا يجعل من الأسهل:
إعادة إنتاج وتصحيح التدريب ومسامير الخسارة
تحميل نقطة تفتيش مدربة على 64 وحدات معالجة الرسومات وتصحيح الأخطاء على 8 وحدات معالجة الرسومات مع استنساخ
راجع الشكل أدناه - تدريب نموذج على 1 أو 8 أو 16 أو 32 أو 64 وحدات معالجة الرسومات يعطي منحنى الخسارة نفسه بالضبط (حتى حدود الرياضيات النقطة العائمة!)
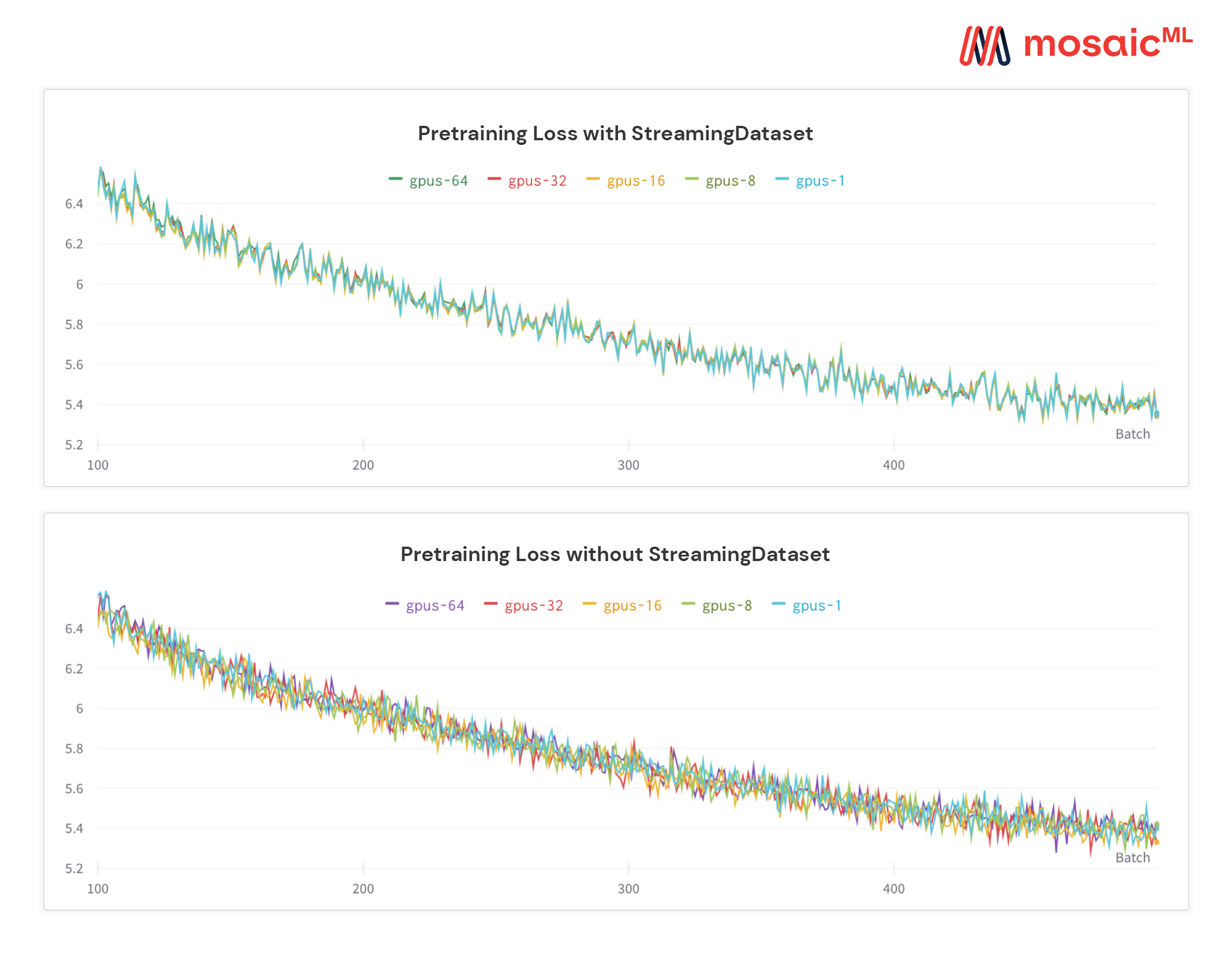
يمكن أن يكون مكلفًا - ومزعجًا - الانتظار حتى تستأنف وظيفتك بينما يدور Dataloader الخاص بك بعد فشل الأجهزة أو ارتفاع الخسارة. بفضل طلب العينة الحتمية لدينا ، يتيح لك StreamingDataset استئناف التدريب في ثوان ، وليس ساعات ، في منتصف التدريب الطويل.
يمكن أن يوفر تقليل زمن استجابة الاستئناف آلاف الدولارات في رسوم الخروج ووقت حساب GPU الخمول مقارنة بالحلول الحالية.
يقطع تنسيق MDS الخاص بنا العمل الغريب إلى العظام ، مما يؤدي إلى زمن انتقال عينة منخفضة للغاية وإنتاجية أعلى مقارنةً ببدائل لأعباء العمل التي تم فحصها بواسطة Dataloader.
| أداة | إنتاجية |
|---|---|
| TreamingDataset | ~ 19000 img/sec |
| ImageFolder | ~ 18000 img/sec |
| webdataset | ~ 16000 img/sec |
النتائج الموضحة من تدريب ImageNet + Resnet-50 ، يتم جمعها على 5 تكرار بعد تخزين البيانات بعد العصر الأول.
يعد التقارب النموذجي من استخدام DreamingDataset جيدًا مثل استخدام القرص المحلي ، وذلك بفضل خوارزمية خلطنا.
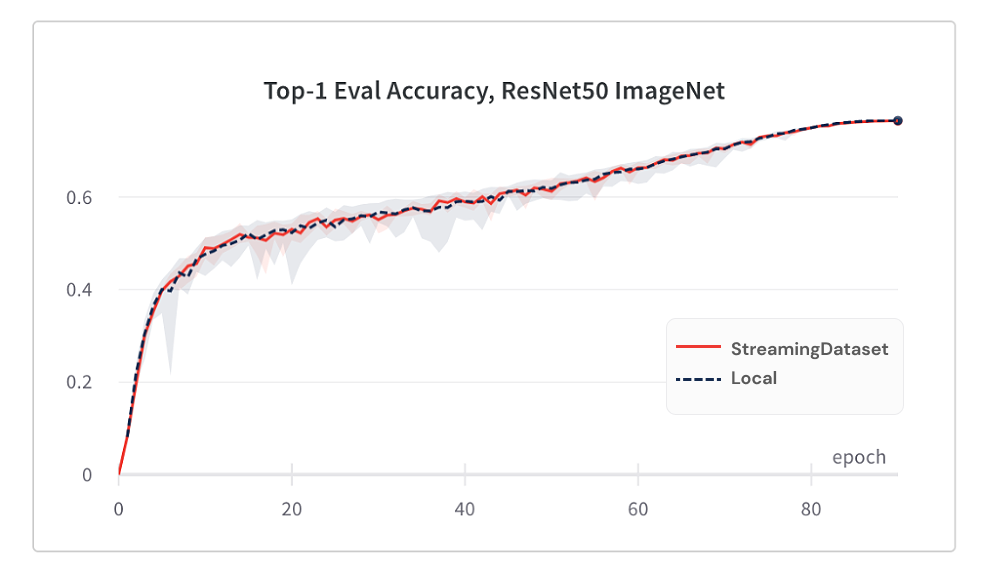
فيما يلي نتائج تدريب ImageNet + Resnet-50 ، تم جمعها على 5 تكرار.
| أداة | أعلى 1 دقة |
|---|---|
| TreamingDataset | 76.51 ٪ +/- 0.09 |
| ImageFolder | 76.57 ٪ +/- 0.10 |
| webdataset | 76.23 ٪ +/- 0.17 |
تتخلف DreamingDataset عبر جميع العينات المعينة للعقدة ، في حين أن الحلول البديلة فقط خلط عينات في تجمع أصغر (ضمن عملية واحدة). خلط عبر تجمع أوسع ينتشر العينات المجاورة أكثر. بالإضافة إلى ذلك ، تقلل خوارزمية خلطنا من العينات المنخفضة. لقد وجدنا كلا من هذه الميزات الخلطية المفيدة لتقارب النموذج.
الوصول إلى البيانات التي تحتاجها عند الحاجة إليها.
حتى إذا لم يتم تنزيل عينة حتى الآن ، فيمكنك الوصول إلى dataset[i] للحصول على نموذج i . سيتم تشغيل التنزيل على الفور وسيتم إرجاع النتيجة عند الانتهاء - على غرار مجموعة بيانات Pytorch على غرار الخريطة مع عينات مرقمة يمكن الوصول إليها بأي ترتيب.
DataSet = DreamingDatAset (...) نموذج = مجموعة البيانات [19543]
سوف يتكرر DreamingDataset بسعادة على أي عدد من العينات. ليس عليك حذف العينات إلى الأبد بحيث تكون مجموعة البيانات قابلة للقسمة على عدد من الأجهزة المخبوزة. بدلاً من ذلك ، يتم تكرار كل حقبة مجموعة مختلفة من العينات (لا شيء يتم إسقاطها) بحيث يعالج كل جهاز نفس العدد.
DataSet = DreamingDatAset (...) dl = dataloader (DataSet ، num_workers = ...)
حذف بشكل ديناميكي شظايا أقل استخدامًا مؤخرًا من أجل الحفاظ على استخدام القرص تحت حد محدد. يتم تمكين هذا عن طريق تعيين CACHE_LIMIT cache_limit . انظر دليل خلط لمزيد من التفاصيل.
dataset = StreamingDataset( cache_limit='100gb', ... )
فيما يلي بعض المشاريع والتجارب التي استخدمت StreamingDataset. هل لديك شيء لإضافته؟ أرسل بريدًا إلكترونيًا إلى [email protected] أو انضم إلى مجتمعنا.
Biomedlm: نموذج لغة كبير محدد المجال للطب الحيوي بواسطة Mosaicml و Stanford CRFM
نماذج انتشار الفسيفساء: تدريب انتشار مستقر من تكاليف الصفر <160 ألف دولار
Mosaic LLMS: GPT-3 Quality مقابل <500 ألف دولار
Mosaic Resnet: تدريب على رؤية الكمبيوتر السريع مع الفسيفساء Resnet و Composer
Mosaic Deeplabv3: 5x تدريب تجزئة الصور الأسرع مع وصفات Mosaicml
... المزيد في المستقبل! ابقوا متابعين!
نرحب بأي مساهمات أو طلبات أو مشكلات.
لبدء المساهمة ، راجع صفحتنا المساهمة.
ملاحظة: نحن نتعاقد!
إذا كنت تحب هذا المشروع ، فاعطنا نجمًا وتحقق من مشاريعنا الأخرى:
الملحن - مكتبة Pytorch الحديثة التي تجعل التدريب على الشبكة العصبية قابلة للتطوير وفعالة سهلة
أمثلة MOSAICML - أمثلة مرجعية لتدريب نماذج ML بسرعة ودقة عالية - تتميز برمز بداية لنماذج اللغة GPT / كبيرة ، الانتشار المستقر ، BERT ، RESNET -50 ، و DEEPLABV3
Mosaicml Cloud- منصة التدريب الخاصة بنا المصممة لتقليل تكاليف التدريب لنماذج LLMs ، ونماذج الانتشار ، والنماذج الكبيرة الأخرى-التي تتميز بتنسيق متعدد السحرة ، وتوسيع متعدد العقدة بدون مجهود ، وتحسينات تحت الغطاء لتسريع وقت التدريب
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

