Noise Reduction
1.0.0

حول المشروع
مكدس التكنولوجيا
بنية الملف
ابدء
النتائج والتوضيح
العمل المستقبلي
المساهمين
شكر وتقدير وموارد
رخصة
الضوضاء اللازمة لإزالتها والتي يتم إحداثها بشكل طبيعي مثل الضوضاء غير البيئية التي تتم إزالتها مع تقليل الإشارة. راجع هذا الوثائق أيضًا هذه المدونة على الحد من ضوضاء الذكاء الاصطناعي
يتم استخدام مكتبة Librosa ل manupulation الصوتية.
للإشارات الصوتية استخدمنا Scipy
يستخدم Matplotlib لمعالجة البيانات وتصور الإشارة.
الباقي هو numpy للعمليات الرياضية ، موجة للعمل على ملف الموجة.
Noise Reduction ├───docs ## Documents and Images │ └───Input Audio file ├─── Project Details │ | │ ├─── │ │ ├───Research papers │ │ ├───Linear Algebra │ │ ├───Neural networks & Deep Learning │ │ ├───Project Documentation │ │ ├───AI Noise Reduction Blog │ │ ├───AI Noise Reduction Report │ │ └───Code Implementation │ │ ├───AI Noise Reduction.py │ │ ├───audio.wav │ │ ├───Resources
تم اختباره على Windows
git clone https://github.com/dhriti03/noise-reduction.gitcd reduction
في دفتر الملاحظات ، قم بتثبيت بعض المكتبات
PIP تثبيت موجة PIP تثبيت Librosa PIP تثبيت scipy.io PIP تثبيت matplotlib.pyplot
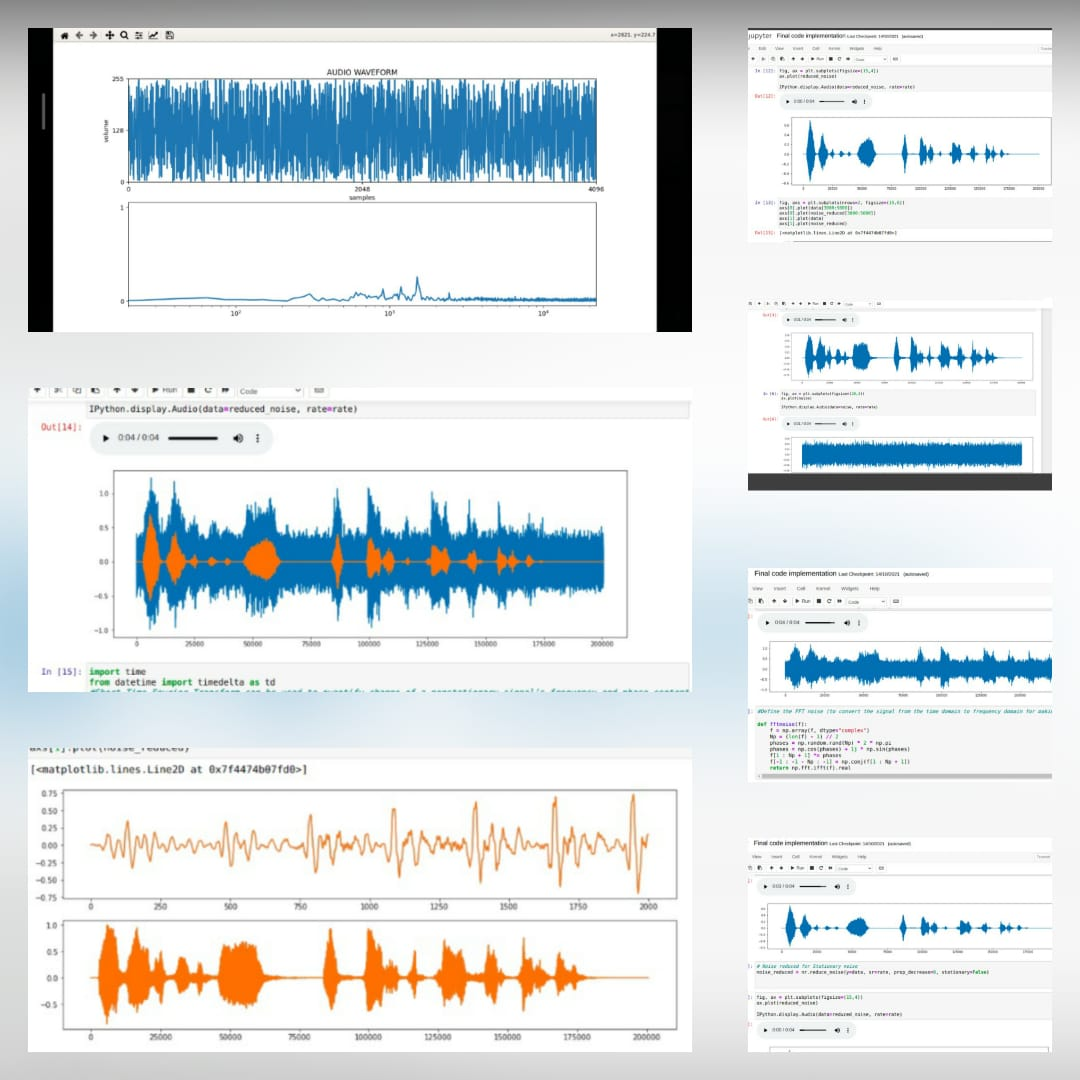
*هذا هو ملف الصوت الأصلي * 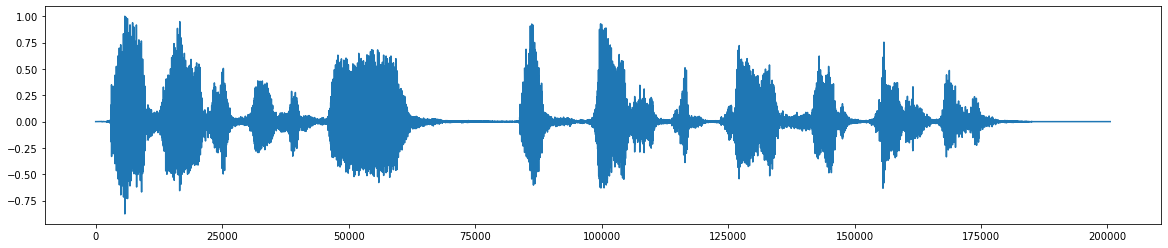 *بعد إضافة الضوضاء *
*بعد إضافة الضوضاء * 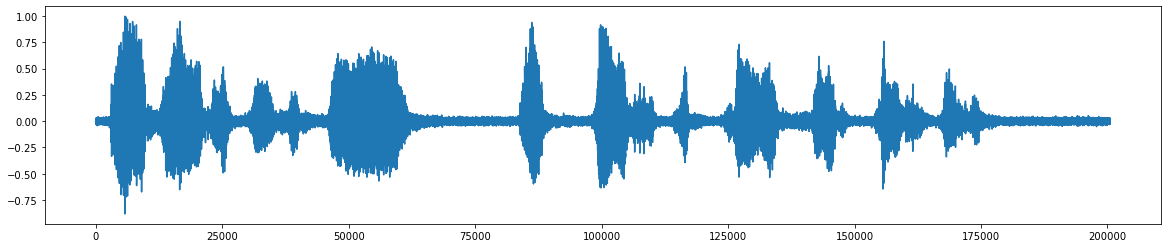 *إشارة الصوت النهائية بعد إزالة الضوضاء *
*إشارة الصوت النهائية بعد إزالة الضوضاء * 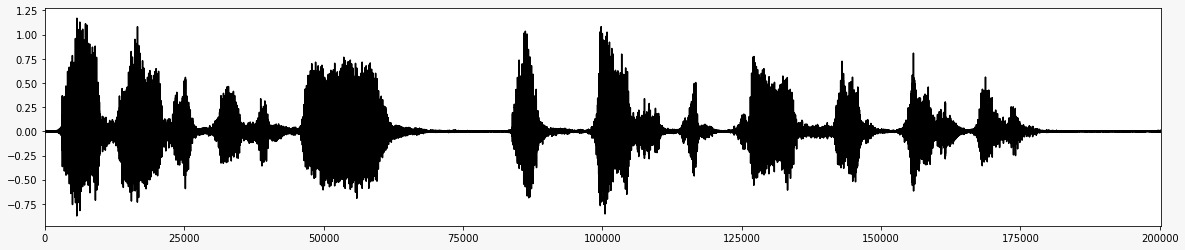 *مخطط انسيابي للمشروع *
*مخطط انسيابي للمشروع * 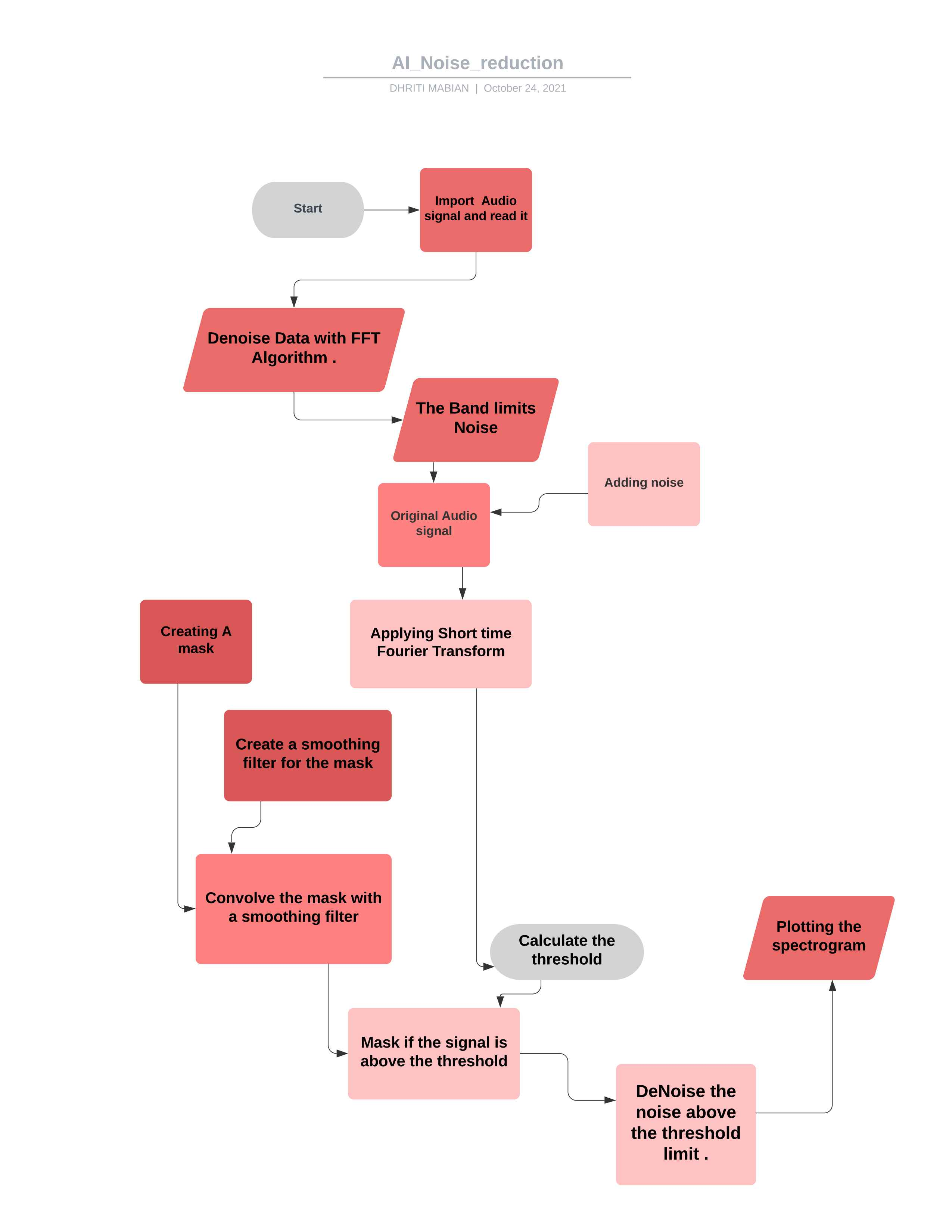
عند معالجة الكود وفقًا لمتطلباتك ، يمكنك استخدامه للتحكم في معظم علامات الصوت. ##نظرية
يتم حساب FFT على مقطع صوت الضوضاء
يتم حساب الإحصائيات على FFT من الضوضاء (في التردد)
يتم حساب العتبة بناءً على إحصائيات الضوضاء (والحساسية المطلوبة للخوارزمية)
يتم تحديد قناع من خلال مقارنة الإشارة FFT بالعتبة
يتم تنعيم القناع مع مرشح فوق التردد والوقت
يتم تعطيل القناع إلى FFT للإشارة ، ويتم قلبه
استيراد ipython من scipy.io import wavfileimport scipy.signalimport numpy كما
نحن هنا نستورد المكتبات مثل ipython lib المستخدمة لإنشاء بيئة شاملة للحوسبة التفاعلية والاستكشافية.
من مكتبة Scipy.io يتم استخدامها لمعالجة البيانات وتصور البيانات باستخدام مجموعة واسعة من أوامر Python.
يحتوي Numpy على مجموعة بيانات متعددة الأبعاد ومصفوفة. يمكن استخدامه لأداء عدد من العمليات الرياضية على المصفوفات مثل الروتينية المثلثية والإحصائية والجبرية ، وبالتالي فإن مكتبة مفيدة للغاية.
تساعد مكتبة Matplotlib.pyplot على فهم كمية البيانات الضخمة من خلال التصورات المختلفة.
تستخدم Librosa عندما نعمل مع بيانات الصوت كما هو الحال في توليد الموسيقى (باستخدام LSTM's) ، والتعرف على الكلام التلقائي. يوفر لبنات البناء اللازمة لإنشاء أنظمة استرجاع معلومات الموسيقى.
٪ matplotlib مضمّن لتمكين التخطيط المضمّن ، حيث سيتم عرض المخططات/الرسوم البيانية أسفل الخلية مباشرة حيث تتم كتابة أوامر التخطيط الخاصة بك. يوفر التفاعل مع الواجهة الخلفية في المقدمة مثل دفتر Jupyter.
wav_loc = r '/home/noise_reduction/downloads/wave/file.wav'rate ، data = wavfile.read (wav_loc ، mmap = false)
هنا نأخذ موقع مسار ملف WAW ثم نقرأ ملف WAW هذا مع وحدة WaveFile التي هي من مكتبة Scipy.io . باستخدام المعلمات (Filename - سلسلة أو مقبض الملف المفتوح وهو ملف WAV الإدخال.) ثم (MMAP: BOOL ، اختياريًا يمكن أن تقرأ البيانات على أنها مخطط للذاكرة (افتراضي: خطأ).
def fftnoise (f): f = np.array (f ، dtype = "complex") np = (len (f) - 1) // 2phases = np.random.rand (np) * 2 * np.piphases = np .cos (المراحل) + 1J * np.sin (المراحل) f [1: np + 1] * = fatsef [-1: -1 -np: -1] = np.conj (f [1: np + 1] ) return np.fft.ifft (f) .Real
نحن هنا أولاً نحدد وظيفة ضوضاء FFT باختصار ، وهو تحويل فورييه السريع (FFT) هو خوارزمية تحسب تحويل فورييه المنفصل (DFT) للتسلسل ، أو معكوس (IDFT). يقوم تحليل فورييه بتحويل إشارة من مجالها الأصلي (غالبًا ما يكون الوقت أو المساحة) إلى تمثيل في مجال التردد والعكس صحيح. يتم الحصول على DFT عن طريق تحلل سلسلة من القيم إلى مكونات من الترددات المختلفة.
باستخدام تحويل فورييه السريع وتحديد دالة نوع البيانات المركب وأخيراً حساب الجزء الحقيقي من الوظيفة. في هذا ، يتم تعيين عمليات التسخين التي تتراوح بين الحد الأدنى من التردد وتردد الحد الأقصى إلى 1 والراحة غير مرغوب فيها.
إعطاء موقع الملف
قراءة ملف WAV
-32767 إلى +32767 هو الصوت المناسب (ليكون متناظرًا) و 32768 يعني أن الصوت مقطوع في تلك النقطة
ملف WAV هو عدد صحيح 16 بت ، والنطاق هو [-32768 ، 32767] ، وبالتالي فإن تقسيمه على 32768 (2^15) سوف يعطي نطاق الاكتتداد المزدوج الصحيح لـ [-1 ، 1]
def band_limited_noise (min_freq ، max_freq ، العينات = 1024 ، أخذ العينات = 1): freqs = np.abs (np.fft.fftfreq (عينات ، 1 / عينات)) f = np.zeros (عينات) f > = min_freq ، freqs <= max_freq)] = 1Return fftnoise (f)
وظيفة أو سلسلة زمنية تقتصر تحويل فورييه على مجموعة محدودة من الترددات أو الأطوال الموجية.
تحديد Freq مع Freq القياسية مع الحد الأقصى والحد الأقصى.
noise_len = 2 # secondsnoise = band_limited_noise (min_freq = 4000 ، max_freq = 12000 ، عينات = len (data) ، samplerate = rate)*10noise_clip = noise [: rate*noise_len] audio_clip_band_limited = data+noise
تحدد كتلة الضوضاء البيضاء المحدودة النطاق طيفًا على الوجهين ، حيث تكون الوحدات هرتز.
حيث تتم مقارنة الحد الأقصى من 12000 و Min Freq من 4000 WRT الضوضاء والبيانات المقدمة.
نحن هنا نقوم بقص إشارة الضوضاء من خلال وجود منتج من المعدل و LEN لإشارة الضوضاء.
وبالتالي إضافة الضوضاء والبيانات المحددة
في الواقع ، تؤدي إضافة الضوضاء إلى توسيع حجم مجموعة بيانات التدريب.
تتم إضافة ضوضاء عشوائية إلى متغيرات الإدخال مما يجعلها مختلفة في كل مرة تتعرض فيها للنموذج.
إضافة الضوضاء إلى عينات الإدخال هي شكل بسيط من زيادة البيانات.
تعني إضافة الضوضاء أن الشبكة أقل قدرة على حفظ عينات التدريب لأنها تتغير طوال الوقت ،
مما يؤدي إلى أوزان الشبكة الأصغر وشبكة أكثر قوة لديها خطأ تعميم أقل.
استيراد Timefrom DateTime استيراد Timedelta كما TD
وقت استيراد هذه الوحدة توفر وظائف متعلقة بالوقت المختلفة. للاطلاع على الوظائف ذات الصلة ، راجع أيضًا وحدات DateTime والتقويم. فئة datetime.timedelta
مدة تعبر عن الفرق بين حالتين أو وقت أو مثيلات في وقت إلى دقة microsecond.
def _stft (y ، n_fft ، hop_length ، win_length): return librosa.stft (y = y ، n_fft = n_fft ، hop_length = hop_length ، win_length = win_length)
يمكن استخدام تحويل فورييه لفترة قصيرة لتحديد تغيير تردد الإشارة غير الثابتة ومحتوى الطور مع مرور الوقت.
يجب أن يشير طول القفزة إلى عدد العينات بين الإطارات المتتالية. لتحليل الإشارة ، يجب أن يكون طول القفزة أقل من حجم الإطار ، بحيث تتداخل الإطارات.
المعلمات ynp.ndarray [الشكل = (n ،)] ، إشارة الدخل ذات القيمة الحقيقية
n_fftint> 0 [القياس]
طول إشارة نافذة بعد الحشو مع الأصفار. عدد الصفوف في مصفوفة STFT D هو (1 + N_FFT/2) . القيمة الافتراضية ، N_FFT = 2048 عينات ، تتوافق مع المدة المادية البالغة 93 ميلي ثانية بمعدل عينة قدره 22050 هرتز ، أي معدل العينة الافتراضي في Librosa. تم تكييف هذه القيمة بشكل جيد لإشارات الموسيقى. ومع ذلك ، في معالجة الكلام ، تكون القيمة الموصى بها 512 ، تقابل 23 مللي ثانية بمعدل عينة قدره 22050 هرتز. في أي حال ، نوصي بتعيين N_FFT على قوة اثنين لتحسين سرعة خوارزمية تحويل فورييه السريعة (FFT).
hop_lengthint> 0 [القياس]
عدد عينات الصوت بين أعمدة STFT المجاورة.
تزيد القيم الأصغر من عدد الأعمدة في D دون التأثير على دقة تردد STFT.
إذا كانت غير محددة ، فإن الإعدادات الافتراضية لـ win_length // 4 (انظر أدناه).
win_lengthint <= n_fft [القياس]
يتم نافذة كل إطار من الصوت بواسطة نافذة ذات طول Win_length ثم مبطنة بأصفار لمطابقة N_FFT .
تعمل القيم الأصغر على تحسين الدقة الزمنية لـ STFT (أي القدرة على تمييز النبضات التي تكون متباعدة بشكل وثيق في الوقت المناسب) على حساب دقة التردد (أي القدرة على تمييز النغمات النقية التي تكون متباعدة بشكل وثيق في التردد). يُعرف هذا التأثير بمقايضة توطين التردد الزمني ويجب تعديله وفقًا لخصائص إشارة الإدخال Y.
إذا غير محدد ، فإن الإعدادات الافتراضية لـ win_length = n_fft .
إرجاع librorosa.istft (y ، hop_length ، win_length)
تحويل فورييه القصيرة الأوقات القصيرة (ISTFT). Converts ذات القيمة المعقدة STFT_Matrix إلى سلسلة زمنية Y عن طريق تقليل الخطأ التربيعي المتوسط بين STFT_Matrix و STFT من Y كما هو موضح في
بشكل عام ، يجب أن تكون وظيفة النافذة وطول القفزة والمعلمات الأخرى كما في STFT ، والتي تؤدي في الغالب إلى إعادة بناء مثالية لإشارة من STFT_Matrix غير المعدلة.
def _amp_to_db (x): return librorosa.core.amplitude_to_db (x ، ref = 1.0 ، amin = 1e-20 ، top_db = 80.0)
1.Convert مطياف سعة إلى الطيفية التي يقيدها DB. هذا يعادل power_to_db (s ** 2) ، ولكن يتم توفيره للراحة.
إرجاع librosa.core.db_to_amplitude (x ، المرجع = 1.0)
قم بتحويل طيفي من طيف DB إلى طيف سعة.
هذا ينقلب بشكل فعال amplitude_to_db:
db_to_amplitude (s_db) ~ = 10.0 (0.5* (s_db + log10 (Ref)/10)) **
def plot_spectrogram (إشارة ، العنوان): الشكل ، ax = plt.subplots (figsize = (20 ، 4)) cax = ax.matshow (إشارة ، أوريغ = "lower" ، isside = "auto" ، cmap = plt.cm. الزلزالية ، vmin = -1 * np.max (np.abs (إشارة)) ، vmax = np.max (np.abs (إشارة)) ،
)رسم الرماية مع الإشارة كمدخل.
تحتوي فئة Axes على معظم عناصر الشكل: المحور ، القراد ، Line2D ، النص ، المضلع ، وما إلى ذلك ، وتعيين نظام الإحداثيات.
يوفر خرائط ألوان متعددة في Matplotlib يمكن الوصول إليها عبر هذه الوظيفة .و ، ابحث عن تمثيل جيد في مساحة الألوان ثلاثية الأبعاد لمجموعة البيانات الخاصة بك.
FIG.COLORBAR (CAX) AX.SET_TITLE (العنوان)
أفضل طريقة لمعرفة ما يحدث ، هي إضافة ColorBar (plt.colorbar () ، بعد إنشاء مؤامرة مبعثرة). ستلاحظ أن القيم الخارجية بين 0 و 10000 كلها أقل من الجزء الأدنى من الشريط ، حيث تكون الأمور خضراء فاتحة للغاية.
بشكل عام ، سيتم تلوين القيم أدناه VMIN بأقل لون ، وستحصل القيم فوق VMAX على أعلى لون.
إذا قمت بتعيين VMAX أصغر من VMIN ، فسيتم تبديلها داخليًا. على الرغم من ذلك ، بناءً على الإصدار الدقيق من Matplotlib والوظائف الدقيقة المسمى ، قد يعطي Matplotlib تحذيرًا خطأ. لذلك ، من الأفضل تعيين VMin دائمًا أقل من VMAX.
def plot_statistics_and_filter (mean_freq_noise ، std_freq_noise ، noise_thresh ، smoothing_filter): fig ، ax = plt.subplots (ncols = 2 ، figsize = (20 ، 4)) plt_std ، = ass [0] .plot (std_freq_noise ، label = "std. std. من الضوضاء ")
plt_std ، = ax [0] .plot (noise_thresh ، label = "عتبة الضوضاء (حسب التردد)") ax [0] .set_title ("عتبة القناع")
AX [0] .Legend () cax = ax [1] .Matshow (smoothing_filter ، Origin = "lower") fig.colorbar (cax) ax [1] .set_title ("مرشح لقناع تنعيم")مخططات الإحصاءات الأساسية للحد من الضوضاء.
نسبة الإشارة إلى الضوضاء (SNR أو S/N) هي مقياس يستخدم في العلوم والهندسة يقارن مستوى الإشارة المطلوبة بمستوى ضوضاء الخلفية.
يتم تعريف SNR على أنها نسبة طاقة الإشارة إلى قوة الضوضاء ، وغالبًا ما يتم التعبير عنها في ديسيبل.
تشير نسبة أعلى من 1: 1 (أكبر من 0 ديسيبل) إلى إشارة أكثر من الضوضاء.
إعداد تردد العتبة لإخفاء الضوضاء.
يشير عتبة التقنيع إلى عملية يصبح فيها صوتًا غير مسموع بسبب وجود صوت آخر.
لذا فإن عتبة التقنيع هي مستوى ضغط الصوت للصوت اللازم لجعل الصوت مسموعًا في وجود ضوضاء أخرى تسمى "قناع"
وهكذا أضاف العتبة.
إشارات ضوضاء طمس مع مختلف مرشحات المرور المنخفضة
قم بتطبيق المرشحات المخصصة على الصور (الالتفاف ثنائي الأبعاد)
def removenoise ( # إلى متوسط الإشارة (الجهد) للجزء الإيجابي المنحدر (الارتفاع) لموجة مثلث لمحاولة إزالة أكبر قدر ممكن من الضوضاء. Audio_clip ، # هذه المقاطع هي المعلمات المستخدمة عليها Operations noise_clip ، n_grad_freq = 2 ، # كم عدد قنوات التردد التي يجب تنعيمها باستخدام mask.n_grad_time = 4 ، # كم عدد القنوات الزمنية التي يجب تنعيمها باستخدام mask.n_fft = 2048 2048 ، # يتم إطار كل إطار من الصوت بواسطة "Window ()`. N_STD_THRESH = 1.5 ، # كم عدد الانحرافات المعيارية بصوت أعلى من متوسط DB للضوضاء (في كل مستوى تردد) المراد اعتباره signprop_decrease = 1.0 ، # إلى أي مدى يجب أن تقلل من الضوضاء (1 = الكل ، 0 = لا شيء) ، يتيح لك Flag # كتابة تعبيرات منتظمة تبدو قابلة للتصوير المرئي = false ،
def removenoise ( إلى متوسط الإشارة (الجهد) للجزء الإيجابي المنحدر (الارتفاع) لموجة مثلث لمحاولة إزالة أكبر قدر ممكن من الضوضاء.
Audio_clip ،
هذه المقاطع هي المعلمات المستخدمة التي سنقوم بها العمليات المعنية
noise_clip ، n_grad_freq = 2 كم عدد قنوات التردد التي يجب تنعيمها مع القناع.
n_grad_time = 4 ، كم عدد القنوات التي يجب تنعيمها مع القناع.
N_FFT = 2048
عدد الصوت من الإطارات بين أعمدة STFT.
Win_length = 2048 ، يتم نافذة كل إطار من الصوت بواسطة window() . ستكون النافذة ذات طول win_length ثم مبطنة بأصفار لمطابقة n_fft ..
Hop_length = 512 ، صوت عدد الإطارات بين أعمدة STFT.
N_STD_THRESH = 1.5 كم عدد الانحرافات المعيارية بصوت أعلى من متوسط DB للضوضاء (في كل مستوى تردد) يجب اعتباره إشارة
prop_decrease = 1.0 ، إلى أي مدى يجب أن تقلل من الضوضاء (1 = الكل ، 0 = لا شيء)
مطول = خطأ ،
يسمح لك Flag بكتابة تعبيرات منتظمة تبدو مرئية قابلة للتقدم = خطأ ، #لترسم خطوات الخوارزمية):
noise_stft = _stft (noise_clip ، n_fft ، hop_length ، win_length) noise_stft_db = _amp_to_db (np.abs (noise_stft))
STFT على الضوضاء
تحويل إلى DB
mean_freq_noise = np.mean (noise_stft_db ، axis = 1) std_freq_noise = np.std (noise_stft_db ، axis = 1) noise_thresh = mean_freq_noise + std_noise * n_std_thresh
حساب الإحصاءات على الضوضاء
نحن هنا للضوضاء العتبة نضيف الوسط والضوضاء القياسية وضوضاء N_STD.
sig_stft = _stft (audio_clip ، n_fft ، hop_length ، win_length) sig_stft_db = _amp_to_db (np.abs (sig_stft))
STFT على إشارة
mask_gain_db = np.min (_amp_to_db (np.abs (sig_stft)))
حساب القيمة لإخفاء DB
smoothing_filter = np.outer (np.concatenate (
[np.linspace (0 ، 1 ، n_grad_freq + 1 ، endpoint = false) ، np.linspace (1 ، 0 ، n_grad_freq + 2) ،
]
) [1: -1] ، np.concatenate (
[np.linspace (0 ، 1 ، n_grad_time + 1 ، endpoint = false) ، np.linspace (1 ، 0 ، n_grad_time + 2) ،
]
) [1: -1] ،
) smoothing_filter = smoothing_filter / np.sum (smoothing_filter)قم بإنشاء مرشح تجانس للقناع في الوقت والتردد
db_thresh = np.repeat (np.reshape (noise_thresh ، [1 ، len (mean_freq_noise)]) ، np.shape (sig_stft_db) [1] ، Axis = 0 ،
) .tاحسب العتبة لكل سلة التردد/الوقت
sig_mask = sig_stft_db <db_thresh
قناع للإشارة
sig_mask = scipy.signal.fftconvolve (sig_mask ، smoothing_filter ، mode = "same") sig_mask = sig_mask * prop_decrease
قناع الالتواء مع مرشح السلس
# قناع الإشارات _stft_db_masked = (sig_stft_db * (1 - sig_mask)+ np.ons (np.shape (mask_gain_db)) _to_amp (SIG_STFT_DB_MASKED) * NP.SIGN (SIG_STFT)) + (1J * SIG_IMAG_MASKED)
قناع الإشارة
# استعادة signalRecovered_signal = _istft (sig_stft_amp ، hop_length ، win_length) recovered_spec = _amp_to_db (np.abs (_stft (Recovered_signal ، n_fft ، hop_length))
)استرداد الإشارة
وبالتالي ، قم بتطبيق القناع إذا كانت الإشارة أعلى من العتبة
حل القناع بفلتر تنعيم
تطبيق خوارزف تقليل الضوضاء لملف WAV الذي تم تنزيله بالفعل.
تطبيق FFT على التسجيل المباشر للإشارة الصوتية.
مزيد من التنفيذ العميق لوكالة الذكاء الاصطناعى لإلغاء الضوضاء.
تطبيق خوارزف تقليل الضوضاء لتنسيقات مختلفة من ملفات الصوت.
إشارة الصوت المباشر مع الميكروفون و ESP32 ، وبالتالي ستحصل على ملف WAV لمزيد من الحساب ومعالجة الإشارات.
Dhriti mabian
بريال أوينكار
*sra vjti_eklavya 2021
شرياس أتري
شاه قاسي
الجرأة
طريقة إلغاء الضوضاء
أخذت الغلاية من مارتن هاينز
تيم سينبرج
رخصة


