awesome RLHF
1.0.0
هذه مجموعة من الأوراق البحثية للتعلم التعزيز مع التعليقات البشرية (RLHF). وسيتم تحديث المستودع بشكل مستمر لتتبع حدود RLHF.
مرحبا بكم في متابعة ونجم!
RLHF رائع (RL مع ردود الفعل البشرية)
2024
2023
2022
2021
2020 وقبل
شرح مفصل
جدول المحتويات
نظرة عامة على RLHF
أوراق
Codebases
مجموعة البيانات
المدونات
دعم اللغة الآخر
المساهمة
رخصة
تتمثل فكرة RLHF في استخدام أساليب من التعلم التعزيز لتحسين نموذج اللغة مباشرة مع التعليقات البشرية. مكّن RLHF نماذج اللغة من البدء في مواءمة نموذج مدرب على مجموعة عامة من بيانات النص إلى تلك الموجودة في القيم الإنسانية المعقدة.
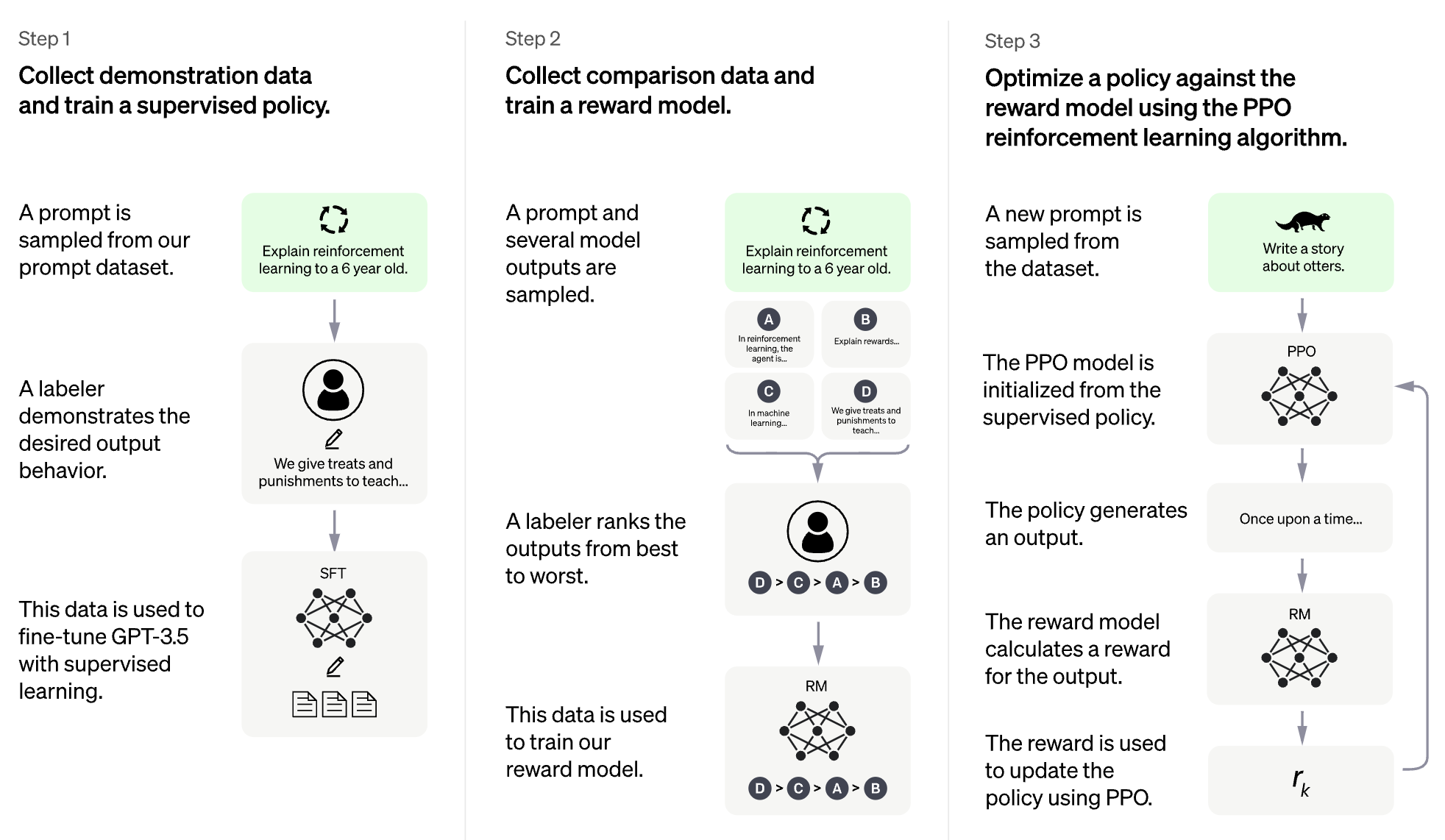
RLHF لنموذج اللغة الكبيرة (LLM)
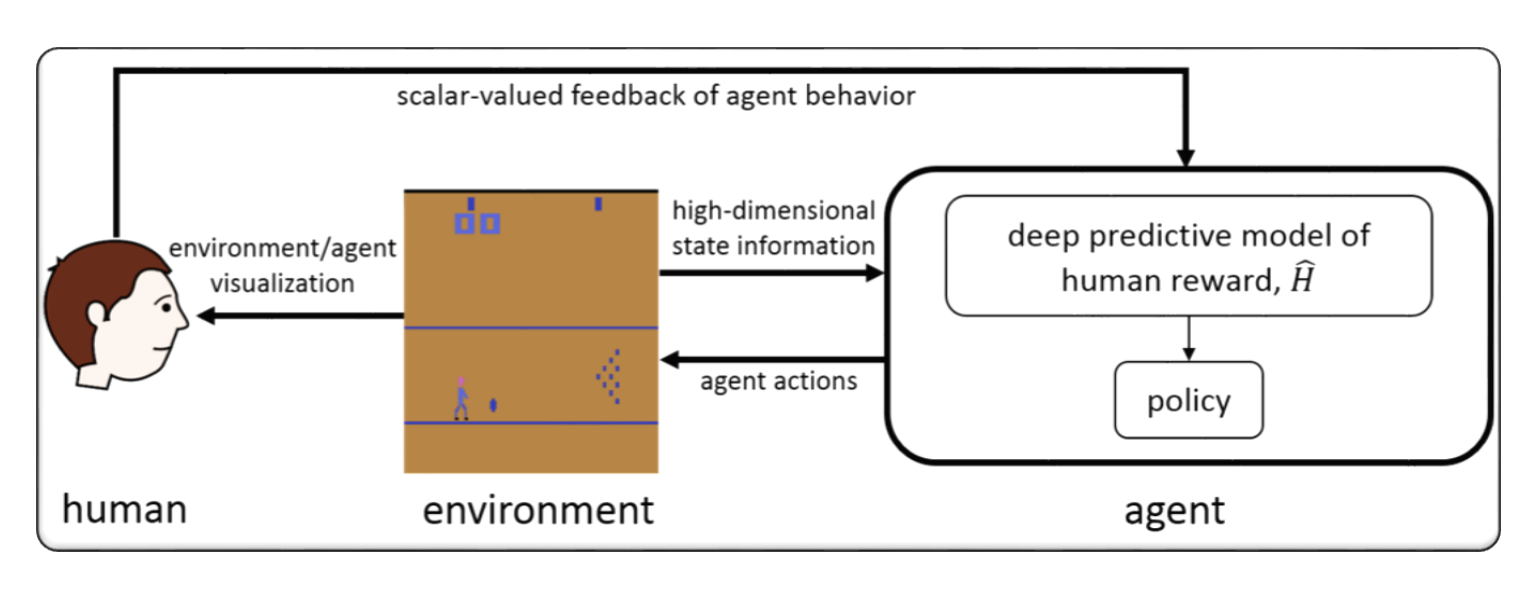
RLHF لألعاب الفيديو (مثل أتاري)
(تم إنشاء القسم التالي تلقائيًا بواسطة ChatGPT)
يشير RLHF عادة إلى "التعلم التعزيز مع التعليقات البشرية". التعلم التعزيز (RL) هو نوع من التعلم الآلي الذي يتضمن تدريب وكيل لاتخاذ القرارات بناءً على ردود الفعل من بيئتها. في RLHF ، يتلقى الوكيل أيضًا ملاحظات من البشر في شكل تصنيفات أو تقييمات لأفعاله ، والتي يمكن أن تساعدها في التعلم بسرعة وبدقة.
RLHF هو مجال بحث نشط في الذكاء الاصطناعي ، مع تطبيقات في المجالات مثل الروبوتات والألعاب وأنظمة التوصيات الشخصية. يسعى إلى مواجهة تحديات RL في السيناريوهات حيث يتمتع الوكيل بالوصول المحدود إلى التعليقات من البيئة ويتطلب مدخلات الإنسان لتحسين أدائها.
التعلم التعزيز مع ردود الفعل البشرية (RLHF) هو مجال بحث سريع النمو في الذكاء الاصطناعي ، وهناك العديد من التقنيات المتقدمة التي تم تطويرها لتحسين أداء أنظمة RLHF. فيما يلي بعض الأمثلة:
Inverse Reinforcement Learning (IRL) : IRL هي تقنية تسمح للوكيل بتعلم وظيفة المكافأة من التعليقات البشرية ، بدلاً من الاعتماد على وظائف المكافأة المحددة مسبقًا. هذا يجعل من الممكن للوكيل أن يتعلم من إشارات التغذية المرتدة أكثر تعقيدًا ، مثل مظاهرات السلوك المطلوب.
Apprenticeship Learning : تعلم التدريب المهني هو تقنية تجمع بين IRL والتعلم الخاضع للإشراف لتمكين الوكيل من التعلم من كل من التعليقات البشرية ومظاهرات الخبراء. يمكن أن يساعد هذا الوكيل على التعلم بسرعة وفعالية ، لأنه قادر على التعلم من كل من التعليقات الإيجابية والسلبية.
Interactive Machine Learning (IML) : IML هي تقنية تتضمن تفاعلًا نشطًا بين الوكيل والخبير البشري ، مما يسمح للخبير بتقديم ملاحظات حول تصرفات الوكيل في الوقت الفعلي. يمكن أن يساعد ذلك الوكيل على التعلم بسرعة أكبر وكفاءة ، حيث يمكنه تلقي ملاحظات حول تصرفاته في كل خطوة من عملية التعلم.
Human-in-the-Loop Reinforcement Learning (HITLRL) : HITLRL هي تقنية تتضمن دمج التعليقات البشرية في عملية RL على مستويات متعددة ، مثل تكوين المكافآت ، واختيار العمل ، وتحسين السياسة. يمكن أن يساعد هذا في تحسين كفاءة وفعالية نظام RLHF من خلال الاستفادة من نقاط قوة كل من البشر والآلات.
فيما يلي بعض الأمثلة على التعلم التعزيز مع التعليقات البشرية (RLHF):
Game Playing : في لعب اللعبة ، يمكن أن تساعد التعليقات البشرية على تعلم الاستراتيجيات والتكتيكات التي تكون فعالة في سيناريوهات اللعبة المختلفة. على سبيل المثال ، في لعبة GO الشهيرة ، يمكن للخبراء البشريين تقديم ملاحظات للوكيل حول تحركاته ، مما يساعدها على تحسين اللعب واتخاذ القرارات.
Personalized Recommendation Systems : في أنظمة التوصية ، يمكن أن تساعد التعليقات البشرية الوكيل على تعلم تفضيلات المستخدمين الأفراد ، مما يجعل من الممكن تقديم توصيات مخصصة. على سبيل المثال ، يمكن للوكيل استخدام ملاحظات من المستخدمين على المنتجات الموصى بها لمعرفة الميزات الأكثر أهمية لهم.
Robotics : في الروبوتات ، يمكن أن تساعد التعليقات البشرية الوكيل على تعلم كيفية التفاعل مع البيئة المادية بطريقة آمنة وفعالة. على سبيل المثال ، يمكن أن يتعلم الروبوت التنقل في بيئة جديدة بسرعة أكبر مع ملاحظات من مشغل بشري على أفضل مسار لأخذها أو الأشياء التي يجب تجنبها.
Education : في التعليم ، يمكن أن تساعد التعليقات البشرية الوكيل على تعلم كيفية تعليم الطلاب بشكل أكثر فعالية. على سبيل المثال ، يمكن للمدرس المستند إلى الذكاء الاصطناعي استخدام ملاحظات من المعلمين الذين تعمل استراتيجيات التدريس بشكل أفضل مع طلاب مختلفين ، مما يساعد على تخصيص تجربة التعلم.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
Hybridflow: إطار RLHF مرن وفعال
Guangming Sheng ، Chi Zhang ، Zilingfeng Ye ، Xibin Wu ، Wang Zhang ، Ru Zhang ، Yanghua Peng ، Haibin Lin ، Chuan Wu
الكلمة الرئيسية: إطار عمل مرن وفعال ، RLHF
الرمز: رسمي
المنبه: مواءمة النماذج اللغوية عبر نمذجة المكافآت الهرمية
Yuhang Lai ، Siyuan Wang ، Shujun Liu ، Xuanjing Huang ، Zhongyu Wei
الكلمة الرئيسية: المكافأة الهرمية ، مهام توليد النص المفتوح
الرمز: رسمي
TLCR: مكافأة مستمرة على مستوى الرمز المميز لتعلم التعزيز الدقيق من التعليقات البشرية
Eunseop Yoon ، Hee Suk Yoon ، Soohwan Eom ، Gunso Han ، Daniel Wontae Nam ، Daejin Jo ، Kyoung-Woon On ، Mark A. Hasegawa-Johnson ، Sungwoong Kim ، Chang D. Yoo
الكلمة الرئيسية: مكافأة مستمرة على مستوى الرمز المميز ، RLHF
الرمز: رسمي
محاذاة نماذج متعددة الوسائط كبيرة مع RLHF المعززة في الواقع
Zhiqing Sun ، Sheng Shen ، Shengcao Cao ، Haotian Liu ، Chunyuan Li ، Yikang Shen ، Chuang Gan ، Liang-Yan Gui ، Yu-Xiong Wang ، Yiming Yang ، Kurt Keutzer ، Trevor Darrell
الكلمة الرئيسية: RLHF المعزز في الواقع ، الرؤية واللغة ، مجموعة بيانات التفضيلات البشرية
الرمز: رسمي
محاذاة نموذج اللغة الكبيرة المباشرة من خلال التقطير المطبق المتناقض ذاتيا
Aiwei Liu ، Haoping Bai ، Zhiyun Lu ، Xiang Kong ، Simon Wang ، Jiulong Shan ، Meng Cao ، Lijie Wen
الكلمة الرئيسية: بدون بيانات التفضيل البشري ، والمكافأة الذاتية ، DPO
الرمز: رسمي
التحكم الحسابي لـ LLMS لتفضيلات المستخدم المتنوعة: توافق تفضيلات الاتجاه مع المكافآت المتعددة الأهداف
Haoxiang Wang ، Yong Lin ، Wei Xiong ، Rui Yang ، Shizhe Dio ، Shuang Qiu ، Han Zhao ، Tong Zhang
الكلمة الرئيسية: تفضيل المستخدم ، نموذج مكافأة متعدد الأفكار ، ورفض أخذ العينات
الرمز: رسمي
العودة إلى الأساسيات: إعادة النظر في تعزيز تحسين الأسلوب للتعلم من التعليقات البشرية في LLMS
أراش أحمديان ، كريس كريمر ، ماتياس غالي ، مارزيه فادا ، جوليا كريتزر ، أوليفييه بيتكين ، أحمد أوستون ، سارة هوكر
الكلمة الرئيسية: تحسين RL عبر الإنترنت ، التكلفة الحسابية المنخفضة
الرمز: رسمي
تحسين نماذج اللغة الكبيرة عبر تعلم التعزيز الدقيق مع الحد الأدنى من قيود التحرير
Zhipeng Chen ، Kun Zhou ، Wayne Xin Zhao ، Junchen Wan ، Fuzheng Zhang ، Di Zhang ، Ji-Rong Wen
الكلمة الرئيسية: مكافأة على مستوى الرمز المميز ، LLM
الرمز: رسمي
RLAIF مقابل RLHF: التحجيم التعزيز التعلم من ردود الفعل البشرية مع ملاحظات الذكاء الاصطناعي
هاريسون لي ، سمرات فياتالي ، حسن منصور ، توماس ميسنارد ، يوهان فيريت ، كيلي رن لو ، كولتون بيشوب ، إيثان هول ، فيكتور كاربون ، أبهيناف راستوجي ، سوشانت براكاش
الكلمة الرئيسية: RL من ملاحظات الذكاء الاصطناعي
الرمز: رسمي
الأساليب المبدئية القائمة على العقوبة لتعلم التعزيز بالفتحة و RLHF
هان شين ، تشوران يانغ ، تياني تشن
الكلمة الرئيسية: التحسين Bilevel
الرمز: رسمي
مكافأة كثيفة مجانا في التعلم التعزيز من ردود الفعل البشرية
أليكس جيمس تشان ، هاو صن ، صموئيل هولت ، ميهلا فان دير شار
الكلمة الرئيسية: تشكيل المكافآت ، RLHF
الرمز: رسمي
نهج الحد الأدنى من العوامل التعليمية للتعلم من التعليقات البشرية
جوكول سوامي ، كريستوف دان ، راهول كيدامبي ، ستيفن وو ، أليخ أغاروال
الكلمة الرئيسية: الفائز Minimax ، تحسين تفضيل الذات
الرمز: رسمي
RLHF-V: نحو MLLMs جديرة بالثقة عن طريق محاذاة السلوك من ردود الفعل البشرية الإصلاحية الدقيقة
Tianyu Yu ، Yuan Yao ، Haoye Zhang ، Taiwen He ، Yifeng Han ، Ganqu Cui ، Jinyi Hu ، Zhiyuan Liu ، Hai-Tao Zheng ، Maosong Sun ، Tat-Seng Chua
الكلمة الرئيسية: نماذج لغة كبيرة متعددة الوسائط ، مشكلة الهلوسة ، تعلم التعزيز من ردود الفعل البشرية
الرمز: رسمي
سير العمل RLHF: من نمذجة المكافآت إلى RLHF عبر الإنترنت
Hanze Dong ، Wei Xiong ، Bo Pang ، Haoxiang Wang ، Han Zhao ، Yingbo Zhou ، Nan Jiang ، Doyen Sahoo ، Caiming Xiong ، Tong Zhang
الكلمة الرئيسية: RLHF التكراري عبر الإنترنت ، نمذجة التفضيل ، نماذج لغة كبيرة
الرمز: رسمي
Maxmin-RLHF: نحو محاذاة منصفة لنماذج اللغة الكبيرة ذات التفضيلات البشرية المتنوعة
Souradip Chakraborty ، Jiahao Qiu ، Hui Yuan ، Alec Koppel ، Furong Huang ، Dinesh Manocha ، Amrit Singh Bedi ، Mengdi Wang
الكلمة الرئيسية: مزيج من توزيعات التفضيل ، هدف محاذاة maxmin
الرمز: رسمي
تحسين سياسة إعادة تعيين مجموعة البيانات لـ RLHF
جوناثان دي تشانغ ، وينهاو تشان ، أوين أويرتيل ، كيانتي برانتلي ، ديبيندرا ميسرا ، جيسون دي ، وين صن
الكلمة الرئيسية: تحسين سياسة إعادة تعيين مجموعة البيانات
الرمز: رسمي
وجهة نظر مكافأة كثيفة على محاذاة نشر النص إلى الصورة مع التفضيل
Shentao Yang ، Tianqi Chen ، Mingyuan Zhou
الكلمة الرئيسية: RLHF لتوليد نص إلى صورة ، وتحسين مكافأة كثيف من DPO ، محاذاة فعالة
الرمز: رسمي
التشغيل الذاتي ، يحول الضبط النماذج الضعيفة النماذج اللغوية إلى نماذج لغة قوية
Zixiang Chen ، Yihe Deng ، Huizhuo Yuan ، Kaixuan Ji ، Quanquan Gu
الكلمة الرئيسية: صقل اللعب الذاتي
الرمز: رسمي
فك تشفير RLHF: تحليل نقدي لتعلم التعزيز من ردود الفعل البشرية لـ LLMS
شرياس شودري ، برانجال أغاروال ، فيشفاك موراهاري ، تانماي راجبوروهيت ، آشوين كاليان ، كارثيك ناراسيمهان ، أميت ديسباندي ، برونو كاسترو دا سيلفا
الكلمة الرئيسية: RLHF ، مكافأة Oracular ، تحليل نموذج المكافأة ، المسح
مواجهة الإفراط في المكافأة لنماذج الانتشار: منظور التحيزات الاستقرائية والسبالة
Ziyi Zhang ، Sen Zhang ، Yibing Zhan ، Yong Luo ، Yonggang Wen ، Dacheng Tao
الكلمة الرئيسية: نماذج الانتشار ، المحاذاة ، التعلم التعزيز ، RLHF ، مكافأة الإفراط في التحيز في الأسبقية
الرمز: رسمي
على التفضيلات المتنوعة لمحاذاة نموذج اللغة الكبيرة
Dun Zeng ، Yong Dai ، Pengyu Cheng ، Tianhao Hu ، Wanshun Chen ، Nan Du ، Zenglin Xu
الكلمة الرئيسية: محاذاة التفضيل المشترك ، مكافأة نمذجة مقاييس ، LLM
الرمز: رسمي
مواءمة ردود فعل الحشد عبر نمذجة مكافأة التفضيل التوزيعي
Dexun Li ، Cong Zhang ، Kuicai Dong ، Derrick Goh Xin Deik ، Ruiming Tang ، Yong Liu
الكلمة الرئيسية: RLHF ، توزيع التفضيل ، المحاذاة ، LLM
ما وراء المحاذاة المترابحة من كل ما يرجع إلى التحويل: تحسين التفضيل المباشر متعدد الأهداف
Zhanhui Zhou ، Jie Liu ، Chao Yang ، Jing Shao ، Yu Liu ، Xiangyu Yue ، Wanli Ouyang ، Yu Qiao
الكلمة الرئيسية: RLHF متعدد الأهداف بدون نمذجة المكافآت ، DPO
الرمز: رسمي
Disalignment المحاكاة: قد تكون محاذاة السلامة لنماذج اللغة الكبيرة بنتائج عكسية!
Zhanhui Zhou ، Jie Liu ، Zhichen Dong ، Jiaheng Liu ، Chao Yang ، Wanli Ouyang ، Yu Qiao
الكلمة الرئيسية: هجوم وقت الاستدلال LLM ، DPO ، إنتاج LLMs الضارة دون تدريب
الرمز: رسمي
تحليل نظري لتعلم ناش من ردود الفعل البشرية في ظل التفضيل العام KL
Chenlu Ye ، Wei Xiong ، Yuheng Zhang ، Nan Jiang ، Tong Zhang
الكلمة الرئيسية: RLHF المستندة إلى اللعبة ، Nash Learning ، المحاذاة تحت Oracle خالية من النماذج
تخفيف ضريبة المحاذاة من RLHF
Yong Lin ، Hangyu Lin ، Wei Xiong ، Shizhe Dio ، Jianmeng Liu ، Jipeng Zhang ، Rui Pan ، Haoxiang Wang ، Wenbin Hu ، Hanning Zhang ، Hanze Dong ، Renjie Pi ، Han Zhao ، Nan Jang ، Heng Ji ، Yuan Yao
الكلمة الرئيسية: RLHF ، ضريبة المحاذاة ، النسيان الكارثي
نماذج نشر التدريب مع التعلم التعزيز
كيفن بلاك ، مايكل جانر ، ييلون دو ، إيليا كوستريكوف ، سيرجي ليفين
الكلمة الرئيسية: التعلم التعزيز ، RLHF ، نماذج الانتشار
الرمز: رسمي
محاذاة: محاذاة تفضيلات الإنسان المتنوعة عن طريق نموذج الانتشار الذي يقدر بالسلوك
Zibin Dong ، Yifu Yuan ، Jianye Hao ، Fei Ni ، Yao Mu ، Yan Zheng ، Yujing Hu ، Tangjie LV ، Changjie Fan ، Zhipeng Hu
الكلمة الرئيسية: التعلم التعزيز ؛ نماذج الانتشار RLHF ؛ تفضيل المحاذاة
الرمز: رسمي
مكافأة كثيفة مجانا في التعلم التعزيز من ردود الفعل البشرية
أليكس ج. تشان ، هاو صن ، صموئيل هولت ، ميهلا فان دير شار
الكلمة الرئيسية: RLHF
الرمز: رسمي
تحويل المكافآت ودمجها لمحاذاة نماذج اللغة الكبيرة
Zihao Wang ، Chirag Nagpal ، Jonathan Berant ، Jacob Eisenstein ، Alex D'Amour ، Sanmi Koyejo ، Victor Veitch
الكلمة الرئيسية: RLHF ، محاذاة ، LLM
المعلمة فعالة التعزيز التعزيز من ردود الفعل البشرية
حكيم سيداهد ، سمرات فاتال ، أليكس هاتشيسون ، تشونان لين ، تشانغ تشن ، زاك يو ، جارفيس جين ، سمرال تشودري ، رومان كوماريتيا ، كريستيان أهلهايم ، يونغو تشو ، بوين لي ، ، أبيناف راستوجي ، لوكاس ديكسون
الكلمات الرئيسية: RLHF ، طريقة فعالة للمعلمة ، التكلفة الحسابية المنخفضة ، LLM ، VLM
تحسين التعلم التعزيز من ردود الفعل البشرية مع فرقة نموذج مكافأة فعالة
Shun Zhang ، Zhenfang Chen ، Sunli Chen ، Yikang Shen ، Zhiqing Sun ، Chuang Gan
الكلمات الرئيسية: RLHF ، فرقة المكافأة ، طريقة الفرقة الفعالة
نموذج نظري عام لفهم التعلم من التفضيلات البشرية
محمد غشلاغي آزار ، مارك رولاند ، بلال بيوت ، دانييل قوه ، دانييلي كالاندرييلو ، ميشال فالكو ، ريمي مونوس
الكلمات الرئيسية: RLHF ، تفضيل زوجي
تعطي ردود الفعل البشرية ذات الحبيبات الدقيقة مكافآت أفضل للتدريب على نموذج اللغة
Zeqiu Wu ، Yushi Hu ، Weijia Shi ، Nouha Dziri ، Alane Suhr ، Prithviraj Ammanabrolu ، Noah A. Smith ، Mari Ostendorf ، Hannananh Hajishirzi
الكلمة الرئيسية: RLHF ، مكافأة على مستوى الجملة ، LLM
الرمز: رسمي
إرشادات على مستوى الرمز المميز المتفضي
Shentao Yang ، Shujian Zhang ، Congying Xia ، Yihao Feng ، Caiming Xiong ، Mingyuan Zhou
الكلمة الرئيسية: RLHF ، إرشادات التدريب على مستوى الرمز المميز ، إطار تدريب بديل/عبر الإنترنت ، أهداف التدريب الحد الأدنى
الرمز: رسمي
مكافآت رائعة وكيفية ترويضها: دراسة حالة حول تعلم المكافأة لأنظمة الحوار الموجهة للمهمة
Yihao Feng*، Shentao Yang*، Shujian Zhang ، Jianguo Zhang ، Caiming Xiong ، Mingyuan Zhou ، Huan Wang
الكلمة الرئيسية: RLHF ، تعلم وظيفة المكافأة الجيرية ، استخدام وظائف المكافأة ، نظام الحوار الموجهة نحو المهمة ، التعلم إلى الرتبة
الرمز: رسمي
التعلم التفضيلي العكسي: RL القائم على التفضيل بدون وظيفة مكافأة
جوي هيجنا ، دورسا ساديلي
الكلمة الرئيسية: التعلم التفضيلي العكسي ، بدون نموذج مكافأة
الرمز: رسمي
ALPACAFARM: إطار محاكاة للطرق التي تتعلم من ردود الفعل البشرية
يان دوبوا ، تشن شن شويشن لي ، روهان تاوري ، تيانيي تشانغ ، إيشان جولراجاني ، جيمي با ، كارلوس غوسترين ، بيرسي س. ليانغ ، تاتسونوري ب.
الكلمة الرئيسية: RLHF ، إطار المحاكاة
الرمز: رسمي
تفضيل ترتيب التحسين لمحاذاة الإنسان
أغنية Feifan ، Bowen Yu ، Minghao Li ، Haiyang Yu ، Fei Huang ، Yongbin Li ، Houfeng Wang
الكلمة الرئيسية: تحسين تصنيف التفضيل
الرمز: رسمي
تحسين التفضيلات
Pengyu Cheng ، Yifan Yang ، Jian Li ، Yong Dai ، Nan du
الكلمة الرئيسية: RLHF ، GAN ، ألعاب الخصومة
الرمز: رسمي
التفضيل التكراري التعلم من ردود الفعل البشرية: سد نظرية وممارسة RLHF تحت استفسار KL
Wei Xiong ، Hanze Dong ، Chenlu Ye ، Ziqi Wang ، Han Zhong ، Heng Ji ، Nan Jiang ، Tong Zhang
الكلمة الرئيسية: RLHF ، DPO التكراري ، الأساس الرياضي
عينة من التعلم التعزيز الفعال من التعليقات البشرية عبر الاستكشاف النشط
Viraj Mehta ، Vikramjeet Das ، Ojash Neopane ، Yijia Dai ، Ilija Bogunovic ، Jeff Schneider ، Willie Neiswanger
الكلمة الرئيسية: RLHF ، عينة فعالية ، استكشاف
التعلم التعزيز من ردود الفعل الإحصائية: الرحلة من اختبار AB إلى اختبار النمل
Feiyang Han ، Yimin Wei ، Zhaofeng Liu ، Yanxing Qi
الكلمة الرئيسية: RLHF ، AB Testing ، RLSF
تحليل أساسي لقدرة نماذج المكافآت على تحليل نماذج الأساس بدقة ضمن تحول التوزيع
بن بيكوس ، ويل ليفين ، توني تشن ، شون هندريكس
الكلمة الرئيسية: RLHF ، OOD ، تحول التوزيع
محاذاة فعالة للبيانات لنماذج اللغة الكبيرة مع ردود الفعل البشرية من خلال اللغة الطبيعية
دي جين ، شيكيب مهري ، ديفامانيو هازاريكا ، إيشواريا بادماكومار ، سونغجين لي ، يانغ ليو ، مهدي نامازيفار
الكلمة الرئيسية: RLHF ، فعال البيانات ، المحاذاة
دعونا نعزز خطوة بخطوة
سارة بان ، فلاديسلاف ليالين ، شيرين موكاتيرا ، آنا رومشيسكي
الكلمة الرئيسية: RLHF ، المنطق
تحسين السياسة القائمة على التفضيل المباشر دون نمذجة المكافآت
Gaon An ، Junhyeok Lee ، Xingdong Zuo ، Norio Kosaka ، Kyung-Min Kim ، Hyun Oh Song
الكلمة الرئيسية: RLHF بدون نمذجة المكافآت ، التعلم التباين ، التعلم غير المتصلة بالإنترنت
محاذاة: محاذاة تفضيلات الإنسان المتنوعة عن طريق نموذج الانتشار الذي يقدر بالسلوك
Zibin Dong ، Yifu Yuan ، Jianye Hao ، Fei Ni ، Yao Mu ، Yan Zheng ، Yujing Hu ، Tangjie LV ، Changjie Fan ، Zhipeng Hu
الكلمة الرئيسية: RLHF ، المحاذاة ، نموذج الانتشار
يوريكا: تصميم المكافآت على مستوى الإنسان عن طريق ترميز نماذج اللغة الكبيرة
Yecheng Jason Ma ، William Liang ، Guanzhi Wang ، De-An Huang ، Osbert Bastani ، Dinesh Jayaraman ، Yuke Zhu ، Linxi Fan ، Anima Anandkumar
الكلمة الرئيسية: LLM على أساس ، تصميم وظائف المكافأة
RLHF الآمن: التعرف على التعزيز الآمن من ردود الفعل البشرية
Josef Dai ، Xuehai Pan ، Ruiyang Sun ، Jiaming JI ، Xinbo Xu ، Mickel Liu ، Yizhou Wang ، Yaodong Yang
الكلمة الرئيسية: Sale RL ، LLM Fine-Ture
تنوع الجودة من خلال ردود الفعل البشرية
لي دينغ ، جيني تشانغ ، جيف كلون ، لي سبيكتور ، جويل ليمان
الكلمة الرئيسية: تنوع الجودة ، نموذج الانتشار
Remax: طريقة تعلم تعزيز بسيطة وفعالة وفعالة لمحاذاة نماذج اللغة الكبيرة
Ziniu Li ، Tian Xu ، Yushun Zhang ، Yang Yu ، Ruoyu Sun ، Zhi-Quan Luo
الكلمة الرئيسية: الكفاءة الحسابية ، تقنية تقليل التباين
ضبط نماذج رؤية الكمبيوتر مع مكافآت المهمة
أندريه سوزانو بينتو ، ألكساندر كولسنيكوف ، يوج شي ، لوكاس باير ، شياووا تشاي
الكلمة الرئيسية: مكافأة ضبط في رؤية الكمبيوتر
حكمة بعد فوات الأوان تجعل نماذج اللغة أفضل تعليمات متابعين
تيانجون تشانغ ، فانغشن ليو ، جوستين وونغ ، بيتر أبيل ، جوزيف إي. غونزاليس
الكلمة الرئيسية: إعادة توزيع التعليمات ، نظام RLHF ، لا يوجد شبكة قيمة مطلوبة
الرمز: رسمي
تم تعليمات اللغة التعليمية التعليمية للتنسيق البشري AA
Hengyuan Hu ، Dorsa Sadigh
الكلمة الرئيسية: تنسيق الإنسان-AI ، محاذاة التفضيل البشري ، التعليمات المضيئة RL
محاذاة نماذج اللغة مع التعلم التعزيز دون اتصال من ردود الفعل البشرية
جيان هو ، لي تاو ، يونيو يانغ ، تشاندلر تشو
الكلمة الرئيسية: المحاذاة القائمة على محول القرار ، التعلم التعزيز غير المتصلة ، نظام RLHF
تفضيل ترتيب التحسين لمحاذاة الإنسان
أغنية Feifan ، Bowen Yu ، Minghao Li ، Haiyang Yu ، Fei Huang ، Yongbin Li و Houfeng Wang
الكلمة الرئيسية: محاذاة التفضيل البشري الخاضع للإشراف ، تمديد ترتيب التفضيل
الرمز: رسمي
سد الفجوة: دراسة استقصائية حول دمج التعليقات (البشرية) لتوليد اللغة الطبيعية
باتريك فرنانديس ، أمان ماداان ، إيمي ليو ، أنطونيو فارينهاس ، بيدرو هنريك مارتينز ، أماندا بيرتش ، خوسيه جي سي دي سوزا ، شويان تشو ، تونغشوانغ وو ، جراهام نيوبيج ، أندريه ف.
الكلمة الرئيسية: توليد اللغة الطبيعية ، تكامل التعليقات البشرية ، التغذية الراجعة الرسمية والتصنيف ، ردود الفعل من الذكاء الاصطناعي والأحكام القائمة على المبادئ
GPT-4 التقرير الفني
Openai
الكلمة الرئيسية: نموذج واسع النطاق متعدد الوسائط ، نموذج محول ، RLHF المستخدمة
الرمز: رسمي
Dataset: Drop ، Winogrande ، Hellaswag ، Arc ، Humaneval ، GSM8K ، MMLU ، struduleqa
الطوف: مكافأة تصنف Finetuning لمحاذاة نموذج الأساس التوليدي
هانزي دونغ ، وي شيونج ، ديبانشو غويال ، روي بان ، شيزهي ديو ، جيبينغ تشانغ ، كاشون شوم ، تونغ تشانغ
الكلمة الرئيسية: الرفض أخذ عينات Finetuning ، بديل لـ PPO ، نموذج الانتشار
الرمز: رسمي
RRHF: ترتيب الاستجابات لمحاذاة نماذج اللغة مع التعليقات البشرية بدون دموع
Zheng Yuan ، Hongyi Yuan ، Chuanqi Tan ، Wei Wang ، Songfang Huang ، Fei Huang
الكلمة الرئيسية: نموذج جديد لـ RLHF
الرمز: رسمي
تفضيل قليلة التعلم للإنسان في الحلقة RL
جوي هيجنا ، دورسا ساديلي
الكلمة الرئيسية: التعلم التفضيلي ، التعلم التفاعلي ، التعلم متعدد المهام ، توسيع مجموعة البيانات المتاحة من خلال عرض الإنسان في الحلقة RL
الرمز: رسمي
أفضل محاذاة نماذج نص إلى الصورة مع التفضيل البشري
Xiaoshi Wu ، Keqiang Sun ، Feng Zhu ، Rui Zhao ، Hongsheng Li
الكلمة الرئيسية: نموذج الانتشار ، نص إلى صورة ، جمالية
الرمز: رسمي
Imagereward: تعلم وتقييم التفضيلات البشرية لتوليد النص إلى صورة
Jiazheng Xu ، Xiao Liu ، Yuchen Wu ، Yuxuan Tong ، Qinkai Li ، Ming Ding ، Jie Tang ، Yuxiao Dong
الكلمة الرئيسية: تفضيلات الإنسان من النص إلى الصورة للأغراض العامة ، وتقييم النماذج التوليدية من النص إلى صورة
الرمز: رسمي
مجموعة البيانات: Coco ، DiffusionDB
محاذاة نماذج من النص إلى صورة باستخدام ردود الفعل البشرية
كيمين لي ، هاو ليو ، مونكيونج ريو ، أوليفيا واتكينز ، يوكينغ دو ، كريج بوتيلير ، بيتر أبيل ، محمد غافامزاده ، شيكسيانغ شين غو
الكلمة الرئيسية: نص إلى صورة ، نموذج نشر مستقر ، وظيفة المكافأة التي تتنبأ بالتعليقات البشرية
chatgpt المرئي: الحديث والرسم والتحرير مع نماذج الأساس المرئي
Chenfei Wu ، Shengming Yin ، Weizhen Qi ، Xiaodong Wang ، Zecheng Tang ، Nan Duan
الكلمة الرئيسية: نماذج الأساس المرئي ، chatgpt المرئي
الرمز: رسمي
نماذج لغة ما قبل التدريب مع التفضيلات البشرية (PHF)
Tomasz Korbak ، Kejian Shi ، Angelica Chen ، Rasika Bhalerao ، Christopher L. Buckley ، Jason Phang ، Samuel R. Bowman ، Ethan Perez
الكلمة الرئيسية: ما قبل الحجم ، RL ، محول القرار
الرمز: رسمي
مواءمة نماذج اللغة مع التفضيلات من خلال تقليل التقليل من التقليل من التقليل (F-DPG)
Dongyoung Go ، Tomasz Korbak ، Germán Kruszewski ، Jos Rozen ، Nahyeon Ryu ، Marc Dymetman
الكلمة الرئيسية: F-Divergence ، RL مع عقوبات KL
تعلم التعزيز المبدئي مع ردود الفعل البشرية من مقارنات زوجية أو k-wise
Banghua Zhu ، Jiantao Jiao ، Michael I. Jordan
الكلمة الرئيسية: MLE المتشائم ، Max-Enropy IRL
القدرة على التصحيح الذاتي الأخلاقي في نماذج اللغة الكبيرة
الإنسان
الكلمة الرئيسية: تحسين قدرة التصحيح الذاتي الأخلاقي عن طريق زيادة تدريب RLHF
مجموعة البيانات الشواء
هل تعلم التعزيز (ليس) لمعالجة اللغة الطبيعية؟: المعايير ، وخطوط الأساس ، وكتل البناء لتحسين سياسة اللغة الطبيعية (NLPO)
Rajkumar Ramamurthy ، Prithviraj Ammanabrolu ، Kianté ، Brantley ، Jack Hessel ، Rafet Sifa ، Christian Bauckhage ، Hannaneh Hajishirzi ، Yejin Choi
الكلمة الرئيسية: تحسين مولدات اللغة مع RL ، المعيار ، خوارزمية RL Performant
الرمز: رسمي
DataSet: IMDB ، Commongen ، CNN Daily Mail ، Totto ، WMT-16 (EN-DE) ، NarrativeQa ، DailyDialog
تحجيم قوانين نموذج المكافأة المفرط
ليو جاو ، جون شولمان ، يعقوب هيلتون
الكلمة الرئيسية: نموذج مكافأة القطار للمكافأة الذهبية ، حجم مجموعة البيانات ، حجم معلمة السياسة ، بون ، PPO
تحسين محاذاة وكلاء الحوار عبر الأحكام البشرية المستهدفة (العصفور)
أميليا جلايز ، نات ماكاليز ، ماجا ترينباكز ، وآخرون.
الكلمة الرئيسية: وكيل حوار البحث عن المعلومات ، قم بتقسيم الحوار الجيد إلى قواعد اللغة الطبيعية ، DPC ، يتفاعل مع النموذج لاستنباط انتهاك قاعدة محددة (التحقيق العددي)
مجموعة البيانات: أسئلة طبيعية ، ELI5 ، الجودة ، Triviaqa ، Winobias ، BBQ
نماذج لغة الفريق الأحمر لتقليل الأضرار: الأساليب ، وسلوكيات التحجيم ، والدروس المستفادة
Deep Ganguli ، Liane Lovitt ، Jackson Kernion ، وآخرون.
الكلمة الرئيسية: نموذج لغة الفريق الأحمر ، التحقيق في سلوكيات التحجيم ، قراءة مجموعة بيانات الجمهور
الرمز: رسمي
التخطيط الديناميكي في الحوار المفتوح باستخدام التعلم التعزيز
ديبورا كوهين ، مونكيونج ريو ، يينلام تشاو ، أورجاد كيلر ، إدو غرينبرغ ، أفيناتان هاسيديم ، مايكل فينك ، يوسي ماتياس ، إيدان زبيكتور ، كريج بوتيلير ، غال إيليدان
الكلمة الرئيسية: نظام الحوار في الوقت الفعلي ، يتزخل في التضمين المختصرة لحالة المحادثة بواسطة نماذج اللغة ، CAQL ، CQL ، Bert
Quark: توليد نصوص يمكن التحكم فيه مع عدم التعرف على المعزز
Ximing Lu ، Sean Welleck ، Jack Hessel ، Liwei Jiang ، Lianhui Qin ، Peter West ، Prithviraj Ammanabrolu ، Yejin Choi
الكلمة الرئيسية: ضبط نموذج اللغة على إشارات ما لا يجب القيام به ، Transformer ، LLM ضبط مع PPO
الرمز: رسمي
مجموعة البيانات: الكتابة ، SST-2 ، Wikitext-103
تدريب مساعد مفيد وغير ضار مع التعلم التعزيز من ردود الفعل البشرية
Yuntao Bai ، Andy Jones ، Kamal Ndousse ، et al.
الكلمة الرئيسية: المساعدين غير الضارين ، الوضع عبر الإنترنت ، متانة تدريب RLHF ، اكتشاف OOD.
الرمز: رسمي
Dataset: Triviaqa ، Hellaswag ، Arc ، OpenBookqa ، Lambada ، Humaneval ، Mmlu ، struduleqa
تدريس نماذج اللغة لدعم الإجابات مع اقتباسات تم التحقق منها (gophercite)
يعقوب مينيك ، ماجا تريباكز ، فلاديمير ميكوليك ، جون أسلانيدس ، فرانسيس سونج ، مارتن تشادويك ، ميا جلايز ، سوزانا يونغ ، لوسي كامبل جيلينغهام ، جيفري إيرفينغ ، نات مكاليز
الكلمة الرئيسية: إنشاء إجابات نقلاً
مجموعة البيانات: أسئلة طبيعية ، eli5 ، الجودة ، regalfqa
نماذج لغة التدريب لمتابعة التعليمات مع ردود الفعل البشرية (instructGPT)
Long Ouyang ، Jeff Wu ، Xu Jiang ، et al.
الكلمة الرئيسية: نموذج لغة كبير ، محاذاة نموذج اللغة بقصد الإنسان
الرمز: رسمي
DataSet: reuctulaqa ، realtoxicityprompts
الذكاء الاصطناعي الدستوري: إلحاق الضرر من ردود الفعل من الذكاء الاصطناعي
Yuntao Bai ، Saurav Kadavath ، Sandipan Kundu ، Amanda Askell ، Jackson Kernion ، et al.
الكلمة الأساسية: RL من AI Feedback (RLAIF) ، تدريب مساعد AI غير ضار من خلال SelfProvement ، سلسلة الفكر ، والتحكم في سلوك الذكاء الاصطناعي بشكل أكثر دقة
الرمز: رسمي
اكتشاف سلوكيات نموذج اللغة مع تقييمات مكتوبة النموذج
إيثان بيريز ، سام رينجر ، كاميل لوكوتاي ، كارينا نغوين ، إدوين تشن ، وآخرون.
الكلمة الرئيسية: إنشاء تقييمات تلقائيًا باستخدام LMS ، المزيد
الرمز: رسمي
DataSet: BBQ ، Winogender Schemas
نمذجة المكافآت غير الماركوفيان من ملصقات المسار عبر تعلم مثيل متعدد القابل للتفسير
جوزيف في وقت مبكر ، توم بيلي ، كريستين إيفرز ، سارفابالي رامشورن
الكلمة الرئيسية: نمذجة المكافآت (RLHF) ، غير ماركوفيان ، تعلم مثيل متعدد ، تفسير ،
الرمز: رسمي
WebGPT: إجابة أسئلة بمساعدة المتصفح مع التعليقات البشرية (WebGPT)
Reiichiro Nakano ، Jacob Hilton ، Suchir Balaji ، et al.
الكلمة الرئيسية: ابحث عن النموذج على الويب وقدم مرجعًا , التعلم المقلد , قبل الميلاد ، سؤال طويل الشكل
Dataset: ELI5 ، Triviaqa ، struduleqa
تلخيص الكتب بشكل متكرر مع ردود الفعل البشرية
Jeff Wu ، Long Ouyang ، Daniel M. Ziegler ، Nisan Stiennon ، Ryan Lowe ، Jan Leike ، Paul Christiano
الكلمة الرئيسية: نموذج مدرب على مهمة صغيرة لمساعدة الإنسان على تقييم مهمة أوسع ، قبل الميلاد
مجموعة البيانات: Booksum ، NarrativeQa
إعادة النظر في نقاط ضعف التعلم التعزيز للترجمة الآلية العصبية
صموئيل كيجلاند ، جوليا كريتزر
الكلمة الرئيسية: نجاح التدرج السياسي هو بسبب المكافأة بدلاً من شكل توزيع الإخراج ، وترجمة الآلة ، NMT ، تكيف المجال
الرمز: رسمي
مجموعة البيانات: WMT15 ، IWSLT14
تعلم تلخيص من ردود الفعل البشرية
Nisan Stiennon ، Long Ouyang ، Jeff Wu ، Daniel M. Ziegler ، Ryan Lowe ، Chelsea Voss ، Alec Radford ، Dario Amodei ، Paul Christiano
الكلمة الرئيسية: تهتم بجودة الموجزة ، وفقدان التدريب يؤثر على سلوك النموذج ، ونموذج المكافأة يعتمد على مجموعات البيانات الجديدة
الرمز: رسمي
مجموعة البيانات: TL ؛ DR ، CNN/DM
نماذج لغة صقلها من التفضيلات البشرية
دانييل م. زيغلر ، نيسان ستينيون ، جيفري وو ، توم بي براون ، أليك رادفورد ، داريو أمودي ، بول كريستيانو ، جيفري إيرفينج
الكلمة الرئيسية: التعلم المكافأة للغة ، والنص المستمر مع المشاعر الإيجابية ، والمهمة الملخص ، والوصف الفعلي
الرمز: رسمي
مجموعة البيانات: TL ؛ DR ، CNN/DM
محاذاة الوكيل القابل للتطوير عبر نمذجة المكافآت: اتجاه البحث
جان ليك ، ديفيد كروجر ، توم إيفريت ، ميلان مارتيك ، فيشال مايني ، شين ليج
الكلمة الرئيسية: مشكلة محاذاة الوكيل ، تعلم المكافأة من التفاعل ، وتحسين المكافأة مع RL ، ونمذجة المكافآت العودية
الرمز: رسمي
بيئة: أتاري
مكافأة التعلم من التفضيلات البشرية والمظاهرات في أتاري
بورجا إبارز ، جان ليك ، توبياس بوهلين ، جيفري إيرفينغ ، شين ليج ، داريو أمودي
الكلمة الرئيسية: تفضيلات مسار العرض التوضيحي الخبراء مشكلة القرصنة ، الضوضاء في التسمية البشرية
الرمز: رسمي
بيئة: أتاري
تامر عميق: عامل تفاعلي في مساحات الحالة عالية الأبعاد
غاريت وارنيل ، نيكولاس وايتوشيتش ، فيرنون لورن ، بيتر ستون
الكلمة الرئيسية: حالة ذات أبعاد عالية ، والاستفادة من مدخلات المدرب البشري
الرمز: طرف ثالث
بيئة: أتاري
تعلم التعزيز العميق من التفضيلات البشرية
بول كريستيانو ، جان ليك ، توم براون ، ميلجان مارتيك ، شين ليج ، داريو أمودي
الكلمة الرئيسية: استكشف الهدف المحدد في التفضيلات البشرية بين أزواج تجزئة المسارات ، وتعرف على شيء أكثر تعقيدًا من التعليقات البشرية
الرمز: رسمي
ENV: أتاري ، Mujoco
التعلم التفاعلي من ردود الفعل البشرية المعتمدة على السياسة
جيمس ماكلاشان ، مارك ك هو ، روبرت لوفتين ، بي بينج ، جوان وانغ ، ديفيد روبرتس ، ماثيو تايلور ، مايكل ل. ليتمان
الكلمة الرئيسية: يتأثر القرار بالسياسة الحالية بدلاً من التعليقات البشرية ، والتعلم من التعليقات التي تعتمد على السياسة التي تتقارب إلى الأمثل المحلي
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
فيرل: تعلم تعزيز محرك البركان من أجل LLM
Bytedance Seed Mlsys Team & HKU: Guangming Sheng ، Chi Zhang ، Zinglfeng Ye ، Xibin Wu ، Wang Zhang ، Ru Zhang ، Yanghua Peng ، Haibin Lin ، Chuan Wu
الكلمة الرئيسية: إطار عمل مرن وفعال ، RLHF
المهام: RLHF ، مهام التفكير بما في ذلك الرياضيات والرمز.
OpenRlhf
OpenRlhf
الكلمة الرئيسية: 70B ، RLHF ، Deepspeed ، Ray ، Vllm
المهمة: إطار RLHF سهل الاستخدام وقابل للتطوير وعالي الأداء (دعم 70B+ Tuning & Lora & Mixtral & KTO).
Palm + RLHF - Pytorch
Phil Wang ، Yachine Zahidi ، Ikko Eltociear Ashimine ، Eric Alcaide
الكلمة الرئيسية: المحولات ، بنية النخيل
مجموعة البيانات: ENWIK8
LM-Human-preferences
دانييل م. زيغلر ، نيسان ستينيون ، جيفري وو ، توم بي براون ، أليك رادفورد ، داريو أمودي ، بول كريستيانو ، جيفري إيرفينج
الكلمة الرئيسية: التعلم المكافأة للغة ، والنص المستمر مع المشاعر الإيجابية ، والمهمة الملخص ، والوصف الفعلي
مجموعة البيانات: TL ؛ DR ، CNN/DM
فيما يلي-أدى إلى التراجع عن البشر
Long Ouyang ، Jeff Wu ، Xu Jiang ، et al.
الكلمة الرئيسية: نموذج لغة كبير ، محاذاة نموذج اللغة بقصد الإنسان
DataSet: proviewqa realtoxicityprompts
تعلم تعزيز المحولات (TRL)
Leandro von Werra ، Younes Belkada ، Lewis Tunstall ، et al.
الكلمة الرئيسية: Train LLM مع RL ، PPO ، Transformer
المهمة: مشاعر IMDB
تعلم تعزيز المحولات X (TRLX)
جوناثان توف ، لياندرو فون ويرا ، وآخرون.
الكلمة الرئيسية: إطار تدريب موزع ، نماذج لغة تعتمد على T5 ، Train LLM مع RL ، PPO ، ILQL
المهمة: Tuning LLM مع RL باستخدام وظيفة المكافأة المقدمة أو مجموعة البيانات المسمى المكافأة
RL4LMS (مكتبة RL وحدات لضبط نماذج اللغة لتفضيلات الإنسان)
Rajkumar Ramamurthy ، Prithviraj Ammanabrolu ، Kianté ، Brantley ، Jack Hessel ، Rafet Sifa ، Christian Bauckhage ، Hannaneh Hajishirzi ، Yejin Choi
الكلمة الرئيسية: تحسين مولدات اللغة مع RL ، المعيار ، خوارزمية RL Performant
DataSet: IMDB ، Commongen ، CNN Daily Mail ، Totto ، WMT-16 (EN-DE) ، NarrativeQa ، DailyDialog
Lamda-Rlhf-Pytorch
فيل وانغ
الكلمة الرئيسية: لامدا ، آلية الانتباه
المهمة: تنفيذ مفتوح المصدر قبل التدريب لورقة أبحاث لامدا من Google في Pytorch
Textrl
إريك لام
الكلمة الرئيسية: محول Huggingface
المهمة: توليد النص
ENV: PFRL ، صالة الألعاب الرياضية
minrlhf
ثومفوستر
الكلمة الرئيسية: PPO ، مكتبة الحد الأدنى
المهمة: أغراض تعليمية
الدردشة العميقة
Microsoft
الكلمة الرئيسية: تدريب RLHF بأسعار معقولة
الجمل العربي
IBM
الكلمة الرئيسية: الحد الأدنى من الإشراف على الإنسان ، محاذاة ذاتيا
المهمة: نموذج لغة محاذاة ذاتيا مدرب مع الحد الأدنى من الإشراف على الإنسان
FG-RLHF
Zeqiu Wu ، Yushi Hu ، Weijia Shi ، et al.
الكلمة الرئيسية: RLHF الدقيق ، الذي يوفر مكافأة بعد كل قطاع ، يتضمن ردمات متعددة مرتبطة بأنواع التغذية المرتدة المختلفة
المهمة: إطار يمكّن التدريب والتعلم من وظائف المكافآت التي تكون جيدة الحبيبات في الكثافة و RMS-Safe-RLHF
Xuehai Pan ، Ruiyang Sun ، Jiaming JI ، et al.
الكلمة الرئيسية: دعم النماذج الشائعة التي تم تدريبها مسبقًا ، ومجموعة بيانات كبيرة ذات علامات إنسان ، ومقاييس متعددة النطاق للتحقق من قيود السلامة ، والمعلمات المخصصة
المهمة: LLM ذات القيمة المقيدة عبر RLHF آمن
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
بن مان ، جانجولي العميق
الكلمة الرئيسية: مجموعة بيانات التفضيلات البشرية ، بيانات الفريق الأحمر ، المكتوبة بالآلة
المهمة: مجموعة بيانات مفتوحة المصدر لبيانات التفضيل البشري حول المساعدة وعدم الضرر
مجموعة بيانات التفضيلات البشرية في ستانفورد (SHP)
Ethayarajh ، Kawin و Zhang ، Heidi و Wang ، Yizhong و Jurafsky ، دان
الكلمة الرئيسية: مجموعة بيانات تحدث بشكل طبيعي ومكتوبة الإنسان ، 18 مجالًا مختلفًا
المهمة: المقصود لاستخدامه في تدريب نماذج مكافأة RLHF
ProdeSource
ستيفن هـ.
الكلمة الرئيسية: مجموعات بيانات اللغة الإنجليزية المطلوبة ، ورسم خرائط مثال البيانات في اللغة الطبيعية
المهمة: مجموعة أدوات لإنشاء ومشاركة واستخدام مطالبات اللغة الطبيعية
مجموعات موارد أسس المعرفة المنظمة (SKG)
Tianbao Xie ، Chen Henry Wu ، Peng Shi et al.
الكلمة الرئيسية: تأريض المعرفة المنظم
المهمة: ترتبط جمع مجموعات البيانات بتأسيس المعرفة المنظم
مجموعة فلان
Longpre Shayne ، Hou Le ، Vu Tu et al.
المهمة: جمع مجموعات البيانات من Flan 2021 ، P3 ، تعليمات فائقة الطبيعية
RLHF-Reward-Datasets
يينغ شي
الكلمة الرئيسية: مجموعة البيانات المكتوبة بالآلة
webgpt_comparisons
Openai
الكلمة الرئيسية: مجموعة بيانات مكتوبة الإنسان ، إجابة أسئلة طويلة النموذج
المهمة: قم بتدريب نموذج إجابة أسئلة طويلة على شكل أسئلة على التوافق مع التفضيلات البشرية
تلخيص _from_feedback
Openai
الكلمة الرئيسية: مجموعة بيانات مكتوبة الإنسان ، تلخيص
المهمة: تدريب نموذج تلخيص للتوافق مع التفضيلات البشرية
dahoas/synthetic-instruct-gptj-pairwise
Dahoas
الكلمة الرئيسية: مجموعة بيانات مكتوبة الإنسان ، مجموعة بيانات صناعية
محاذاة مستقرة - التعلم المحاذاة في الألعاب الاجتماعية
Ruibo Liu ، Ruixin (Ray) Yang ، Qiang Peng
الكلمة الرئيسية: بيانات التفاعل المستخدمة للتدريب على المحاذاة ، تشغيل في صندوق الرمل
المهمة: تدريب على بيانات التفاعل المسجلة في الألعاب الاجتماعية المحاكاة
ليما
ميتا منظمة العفو الدولية
الكلمة الرئيسية: بدون أي RLHF ، القليل من المطالبات والردود المنسقة بعناية
المهمة: مجموعة البيانات المستخدمة لتدريب نموذج ليما
[Openai] Chatgpt: تحسين نماذج اللغة للحوار
[معانقة الوجه] توضح التعلم التعزيز من ردود الفعل البشرية (RLHF)
[Zhihu] 通向 agi 之路 : 大型语言模型 (llm) 技术精要
[Zhihu] : : 现象与解释
[Zhihu] 中文 hh-rlhf 数据集上的 ppo 实践
[W&B متصل بالكامل] فهم التعرف على التعزيز من ردود الفعل البشرية (RLHF)
[DeepMind] التعلم من خلال التعليقات البشرية
[فكرة] 深入理解语言模型的突现能力
[فكرة] 拆解追溯 gpt-3.5 各项能力的起源
[جوهر] التعلم التعزيز لنماذج اللغة
[يوتيوب] جون شولمان - التعلم التعزيز من ردود الفعل البشرية: التقدم والتحديات
[Openai / Arize] Openai على التعلم التعزيز مع ردود الفعل البشرية
[Encord] دليل لتعزيز التعلم من التعليقات البشرية (RLHF) لرؤية الكمبيوتر
[Weixun Wang] نظرة عامة على RL (HF)+LLM
التركية
هدفنا هو جعل هذا الريبو أفضل. إذا كنت مهتمًا بالمساهمة ، فيرجى الرجوع إلى هنا للحصول على تعليمات بالمساهمة.
يتم إصدار RLHF Awesome بموجب ترخيص Apache 2.0.


