IP Adapter
1.0.0
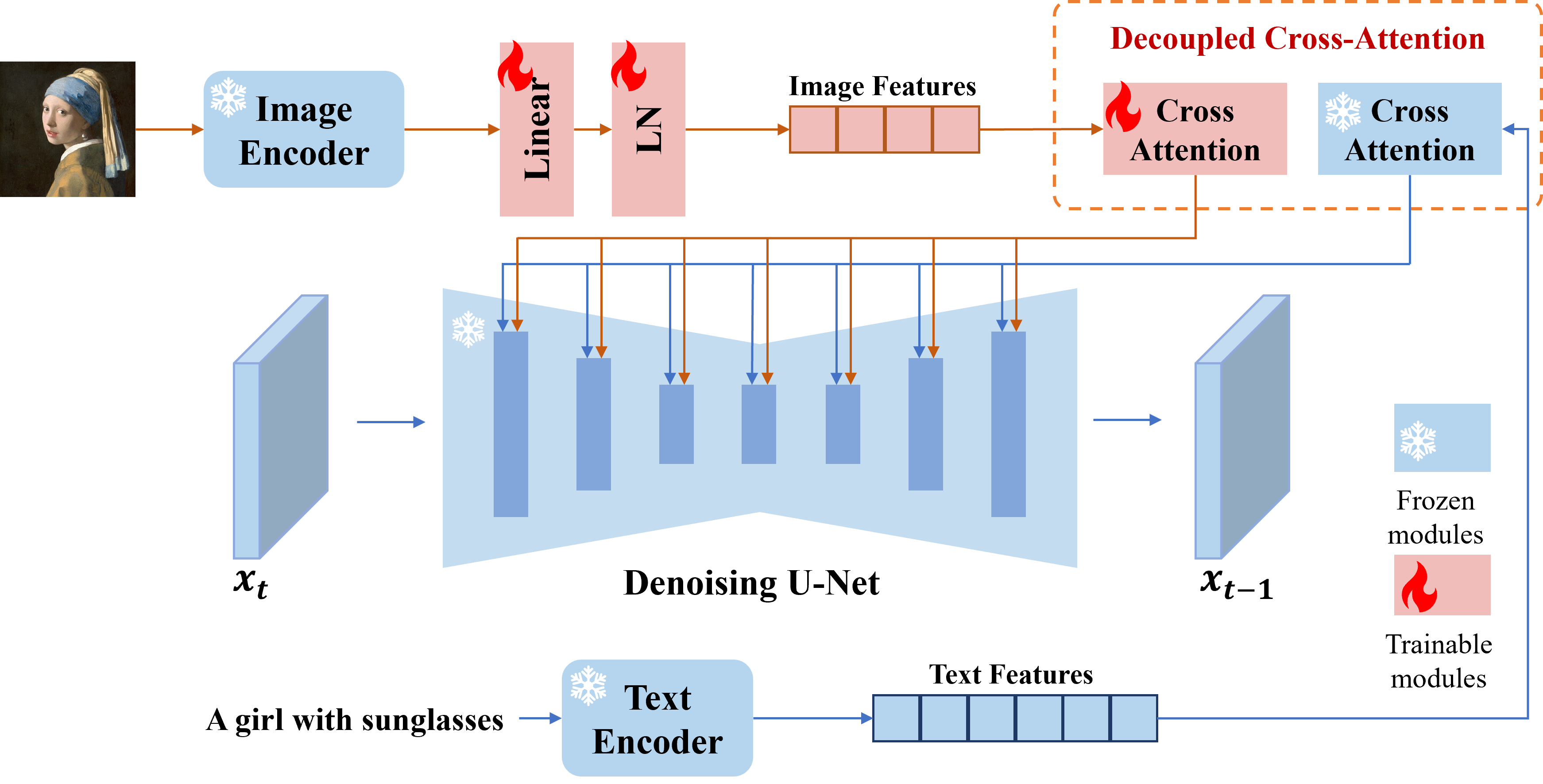
نقدم ADAPTER IP ، وهو محول فعال وخفيف الوزن لتحقيق إمكانية تأثير الصورة لنماذج نشر النص على الصورة المدربة مسبقًا. يمكن أن تحقق معلمة IP التي تحتوي على 22 مترًا فقط أداءً قابلاً للمقارنة أو حتى أفضل لنموذج موجه الصورة المضبوط. يمكن تعميم IP-ADAPTER ليس فقط على الطرز المخصصة الأخرى التي تم ضبطها من نفس النموذج الأساسي ، ولكن أيضًا إلى توليد يمكن التحكم فيه باستخدام أدوات قابلة للتحكم الحالية. علاوة على ذلك ، يمكن أن تعمل موجه الصورة بشكل جيد مع موجه النص لإنجاز توليد الصور متعددة الوسائط.
# install latest diffusers
pip install diffusers==0.22.1
# install ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# download the models
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# then you can use the notebook
يمكنك تنزيل النماذج من هنا. لتشغيل العرض التوضيحي ، يجب عليك أيضًا تنزيل النماذج التالية:









أفضل الممارسات
scale=1.0 و text_prompt="" (أو بعض مطالبات النص العام ، على سبيل المثال "أفضل جودة" ، يمكنك أيضًا استخدام أي موجه نص سلبي). إذا قمت بتخفيض scale ، فيمكن إنشاء صور أكثر تنوعًا ، لكنها قد لا تكون متسقة مع موجه الصورة.scale للحصول على أفضل النتائج. في معظم الحالات ، يمكن أن يحصل ضبط scale=0.5 على نتائج جيدة. لإصدار SD 1.5 ، نوصي باستخدام نماذج المجتمع لإنشاء صور جيدة.IP-Adapter للصور غير المربعة
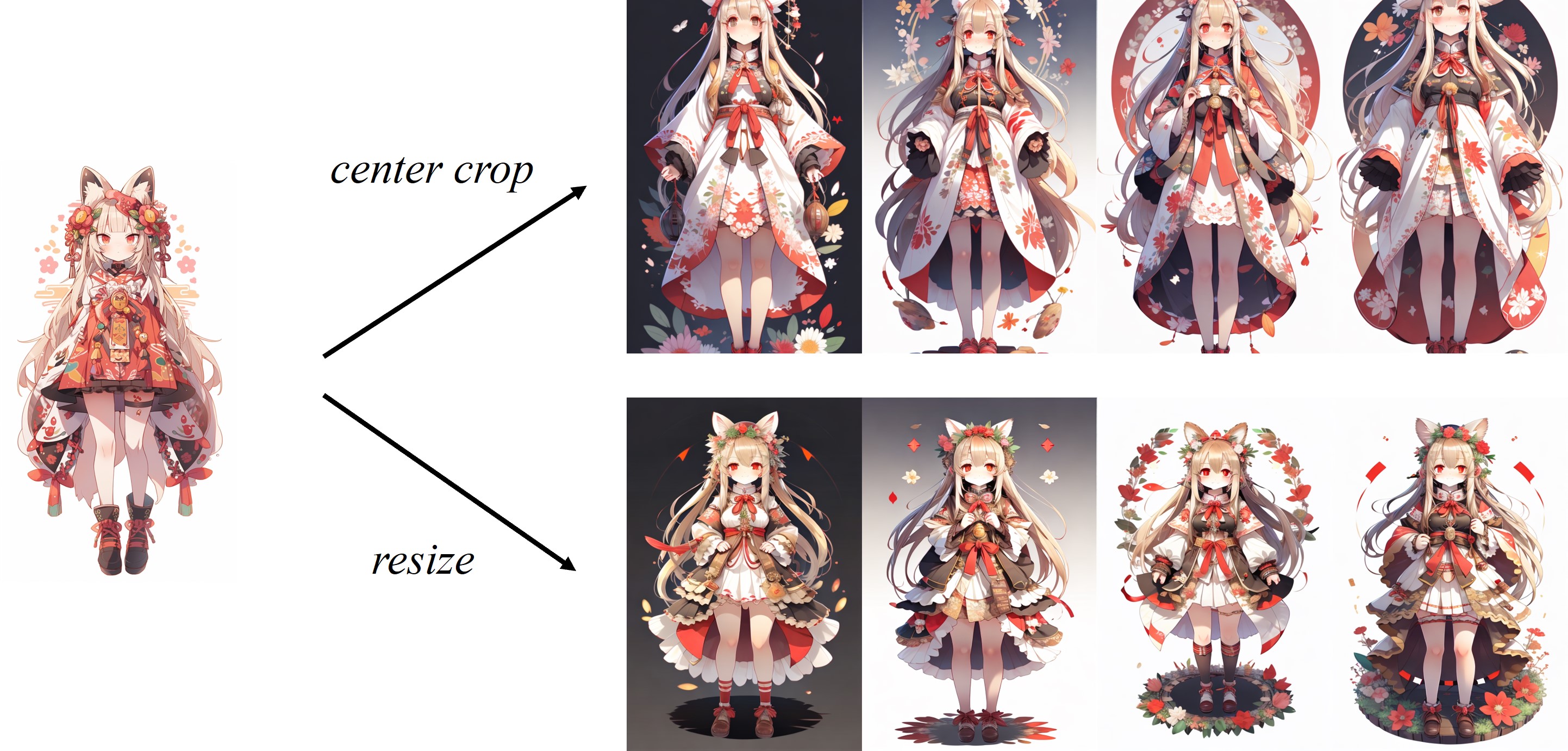
نظرًا لأن الصورة يتم اقتصاصها في معالج الصور الافتراضي للمقطع ، فإن IP-Adapter يعمل بشكل أفضل للصور المربعة. بالنسبة للصور غير المربعة ، ستفقد المعلومات خارج المركز. ولكن يمكنك فقط تغيير الحجم إلى 224 × 224 للصور غير المربعة ، فإن المقارنة هي كما يلي:
يتم عرض مقارنة IP-ADAPTER_XL مع REAMAGINE XL على النحو التالي:

تحسينات في الإصدار الجديد (2023.9.8) :
للتدريب ، يجب عليك تثبيت التسريع وجعل مجموعة البيانات الخاصة بك في ملف JSON.
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16"
tutorial_train.py
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/"
--image_encoder_path="{image_encoder_path}"
--data_json_file="{data.json}"
--data_root_path="{image_path}"
--mixed_precision="fp16"
--resolution=512
--train_batch_size=8
--dataloader_num_workers=4
--learning_rate=1e-04
--weight_decay=0.01
--output_dir="{output_dir}"
--save_steps=10000
بمجرد اكتمال التدريب ، يمكنك تحويل الأوزان بالرمز التالي:
import torch
ckpt = "checkpoint-50000/pytorch_model.bin"
sd = torch . load ( ckpt , map_location = "cpu" )
image_proj_sd = {}
ip_sd = {}
for k in sd :
if k . startswith ( "unet" ):
pass
elif k . startswith ( "image_proj_model" ):
image_proj_sd [ k . replace ( "image_proj_model." , "" )] = sd [ k ]
elif k . startswith ( "adapter_modules" ):
ip_sd [ k . replace ( "adapter_modules." , "" )] = sd [ k ]
torch . save ({ "image_proj" : image_proj_sd , "ip_adapter" : ip_sd }, "ip_adapter.bin" )يسعى هذا المشروع إلى التأثير بشكل إيجابي على مجال توليد الصور الذي يحركه AI. يتم منح المستخدمين حرية إنشاء صور باستخدام هذه الأداة ، لكن من المتوقع أن يمتثلوا للقوانين المحلية واستخدامها بطريقة مسؤولة. لا يتحمل المطورون أي مسؤولية عن إساءة استخدام المستخدمين المحتملين.
إذا وجدت IP-Adapter مفيدة للبحث والتطبيقات الخاصة بك ، فيرجى الاستشهاد باستخدام هذا bibtex:
@article { ye2023ip-adapter ,
title = { IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models } ,
author = { Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei } ,
booktitle = { arXiv preprint arxiv:2308.06721 } ,
year = { 2023 }
}

