OneForAll
1.0.0
ورقة: https://arxiv.org/abs/2310.00149
المؤلفون: Hao Liu ، Jiarui Feng ، Lecheng Kong ، Ningyue Liang ، Dacheng Tao ، Yixin Chen ، Muhan Zhang
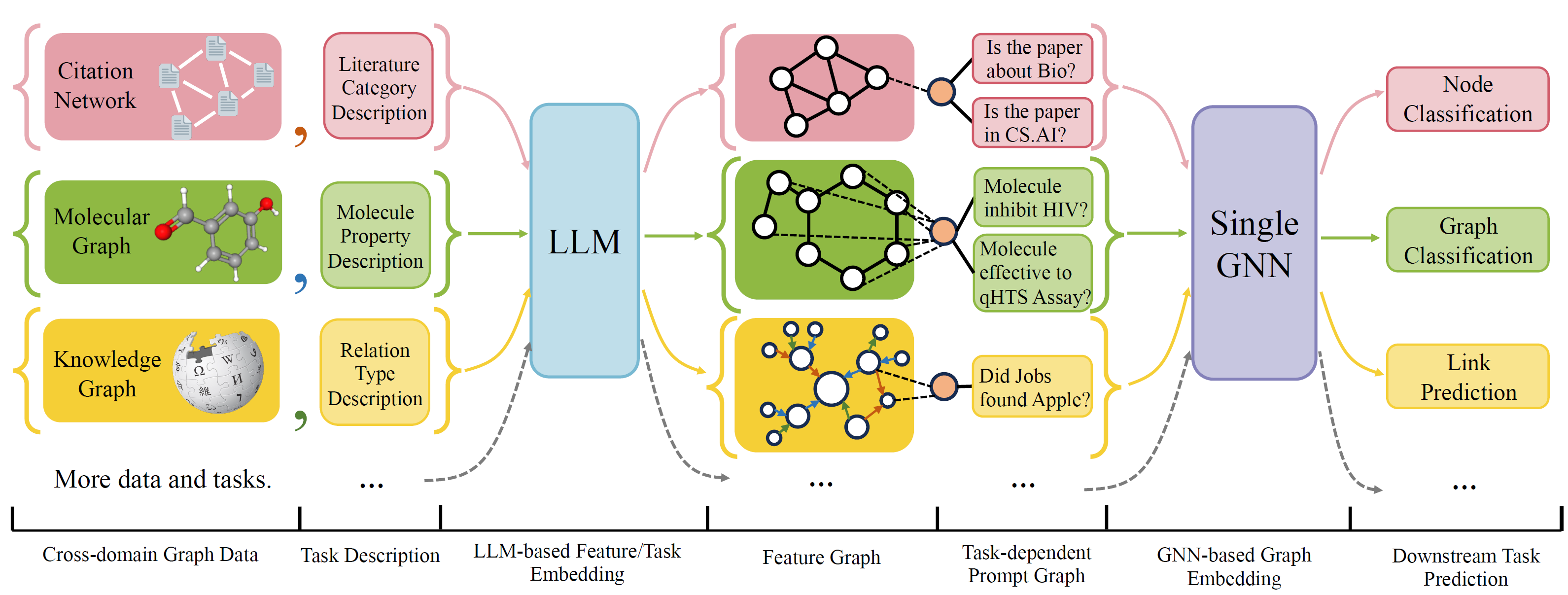
OFA هو إطار تصنيف الرسم البياني العام يمكنه حل مجموعة واسعة من مهام تصنيف الرسم البياني مع نموذج واحد ومجموعة واحدة من المعلمات. المهام عبارة عن مجال متقاطع (على سبيل المثال شبكة الاقتباس ، الرسم البياني الجزيئي ، ...) والمهام المتقاطعة (على سبيل المثال ، طلقة قليلة ، صفر ، مستوى الرسم البياني ، العقدة ، ...) ...)
تستخدم OFA اللغات الطبيعية لوصف جميع الرسوم البيانية ، واستخدام LLM لتضمين كل الوصف في نفس مساحة التضمين ، والتي تمكن التدريب عبر المجال باستخدام نموذج واحد.
OFA يقترح جدوى مطالبة بأن جميع معلومات المهمة يتم تحويلها إلى رسم بياني موجه. لذلك فإن نموذج اللاحقة قادر على قراءة المهام المعلومات والتنبؤ بالهدف المتصاعد وفقًا لذلك ، دون الحاجة إلى ضبط معلمات النموذج والهندسة المعمارية. وبالتالي ، يمكن أن يكون نموذج واحد تبادل المهام.
قام OFA برعاية قائمة مجموعات بيانات الرسم البياني من مصادر ومجالات مختلفة ووصف العقد/الحواف في الرسوم البيانية مع بروتوكول الانهيار المنهجي. نشكر الأعمال السابقة بما في ذلك OGB و Gimlet و Moleculenet و Graphllm و Villmow لتوفير بيانات الرسم البياني/النص الخام الرائع الذي يجعل عملنا ممكنًا.
خضع Oneforall لمراجعة كبيرة ، حيث قمنا بتنظيف الكود وقمنا بإصلاح العديد من الأخطاء المبلغ عنها. التحديثات الرئيسية هي:
إذا كنت قد استخدمت مستودعنا مسبقًا ، فيرجى سحب وحذف الميزة/النصية التي تم إنشاؤها القديم وتجديدها. نأسف للإزعاج.
لتثبيت متطلبات المشروع باستخدام كوندا:
conda env create -f environment.yml
للتجارب الشاملة إلى النهاية على جميع مجموعة البيانات التي تم جمعها ، قم بتشغيل
python run_cdm.py --override e2e_all_config.yaml
يمكن تغيير جميع الوسائط حسب القيم المنفصلة عن الفضاء مثل
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
يمكن للمستخدمين تعديل متغير task_names في ./e2e_all_config.yaml للتحكم في مجموعات البيانات التي يتم تضمينها أثناء التدريب. يجب أن يكون طول task_names و d_multiple و d_min_ratio هو نفسه. يمكن أيضًا تحديدها في وسيطات سطر الأوامر بواسطة قيم مفصول فاصلة.
على سبيل المثال
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
يمكن تحديد OFA-IND بواسطة
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
لتشغيل تجارب قليلة وتصدر صفر
python run_cdm.py --override lr_all_config.yaml
نحدد التكوينات لكل مهمة ، تحتوي كل تكوينات مهمة على العديد من تكوينات مجموعات البيانات.
يتم تخزين تكوينات المهام في ./configs/task_config.yaml . تتكون المهمة عادةً من عدة انشقاقات لمجموعات البيانات (وليس بالضرورة نفس مجموعات البيانات). على سبيل المثال ، ستحصل مهمة تصنيف عقدة CORA من طرف إلى طرف إلى تقسيم قطار مجموعة بيانات CORA كمجموعة بيانات القطار ، والانقسام الصحيح لمجموعة بيانات CORA كواحدة من مجموعة البيانات الصالحة ، وكذلك لتقسيم الاختبار. يمكنك أيضًا الحصول على مزيد من التحقق/الاختبار من خلال تحديد تقسيم القطار في CORA كواحد من مجموعات بيانات التحقق/الاختبار. على وجه التحديد ، يبدو تكوين المهمة
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train split يتم تخزين تكوينات مجموعة البيانات في ./configs/task_config.yaml . يحدد تكوين مجموعة البيانات كيفية إنشاء مجموعة بيانات. خاصة،
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 إذا كنت تقوم بتنفيذ مجموعة بيانات مثل CORA/PubMed/ARXIV ، فإننا نوصي بإضافة دليل لبياناتك $ custom_data $ ضمن البيانات/single_graph/$ custom_data $ وتطبيق gen_data.py ضمن الدليل ، يمكنك استخدام البيانات/cora/gen_data. PY كمثال.
بعد إنشاء البيانات ، تحتاج إلى تسجيل اسم مجموعة البيانات هنا ، وتنفيذ فاصل مثل هنا. إذا كنت تقوم بمهام صفر/طلقة قليلة ، فيمكنك تقسيم الصفر/الطلقة القليلة هنا أيضًا.
أخيرًا ، قم بتسجيل إدخال التكوين في التكوينات/data_config.yaml. على سبيل المثال ، لتصنيف العقدة الشاملة
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$يقوم Process_Label_Func بتحويل التسمية الهدف إلى التسمية الثنائية ، وتحويل تضمين الفئة إذا كانت المهمة عبارة عن طلقة صفرية/قليلة ، حيث لم يتم إصلاح عدد عقدة الفصل. قائمة من Avalaillection process_label_func هنا. يستغرق في جميع الفئات التضمين والتسمية الصحيحة. الإخراج عبارة عن tuple: (label ، class_node_embedding ، تسمية ثنائية/واحدة).
إذا كنت ترغب في مزيد من المرونة ، فإن إضافة مجموعات بيانات مخصصة تتطلب تنفيذ فئة فرعية مخصصة لـ OfpygDataset.
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

