rlcard
RLCard 1.0.7
中文文档
RLCard هي مجموعة أدوات لتعلم التعزيز (RL) في ألعاب الورق. وهو يدعم بيئات بطاقات متعددة مع واجهات سهلة الاستخدام لتنفيذ مختلف خوارزميات التعلم والبحث عن التعزيز. الهدف من RLCard هو سد التعلم التعزيز وألعاب المعلومات غير الكاملة. تم تطوير RLCard بواسطة Data Lab في جامعة رايس وجامعة تكساس إيه آند إم ، والمساهمين في المجتمع.
مجتمع:
أخبار:
يتم تطوير الألعاب التالية وصيانتها بشكل أساسي من قبل المساهمين في المجتمع. شكرًا لك!
شكرا لجميع المساهمين!




























إذا وجدت هذا الريبو مفيدًا ، فقد تستشهد:
تشا ، دوشن ، وآخرون. "RLCard: منصة للتعلم التعزيز في ألعاب الورق." ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} تأكد من تثبيت Python 3.6+ وتثبيت PIP . نوصي بتثبيت الإصدار المستقر من rlcard مع pip :
pip3 install rlcard
سيتضمن التثبيت الافتراضي بيئات البطاقات فقط. لاستخدام تنفيذ Pytorch لخوارزميات التدريب ، قم بتشغيل
pip3 install rlcard[torch]
إذا كنت في الصين وكان الأمر أعلاه بطيئًا جدًا ، فيمكنك استخدام المرآة التي توفرها جامعة Tsinghua:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
بدلاً من ذلك ، يمكنك استنساخ أحدث إصدار مع (إذا كنت في الصين و Github بطيئة ، يمكنك استخدام المرآة في جيتي):
git clone https://github.com/datamllab/rlcard.git
أو فقط استنساخ فرع واحد لجعله أسرع:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
ثم تثبيت مع
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
نحن نقدم أيضًا طريقة تثبيت كوندا :
conda install -c toubun rlcard
يوفر تثبيت Conda فقط بيئات البطاقات ، بل تحتاج إلى تثبيت Pytorch يدويًا على مطالبك.
مثال قصير كما هو موضح أدناه.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()يمكن توصيل RLCard بمرونة بخوارزميات مختلفة. انظر الأمثلة التالية:
قم بتشغيل examples/human/leduc_holdem_human.py للعب مع نموذج Leduc Hold'em الذي تم تدريبه مسبقًا. Leduc Hold'em هي نسخة مبسطة من Texas Hold'em. يمكن العثور على القواعد هنا.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
نحن نقدم أيضا واجهة المستخدم الرسومية لسهولة تصحيح الأخطاء. يرجى التحقق هنا. بعض العروض التوضيحية:
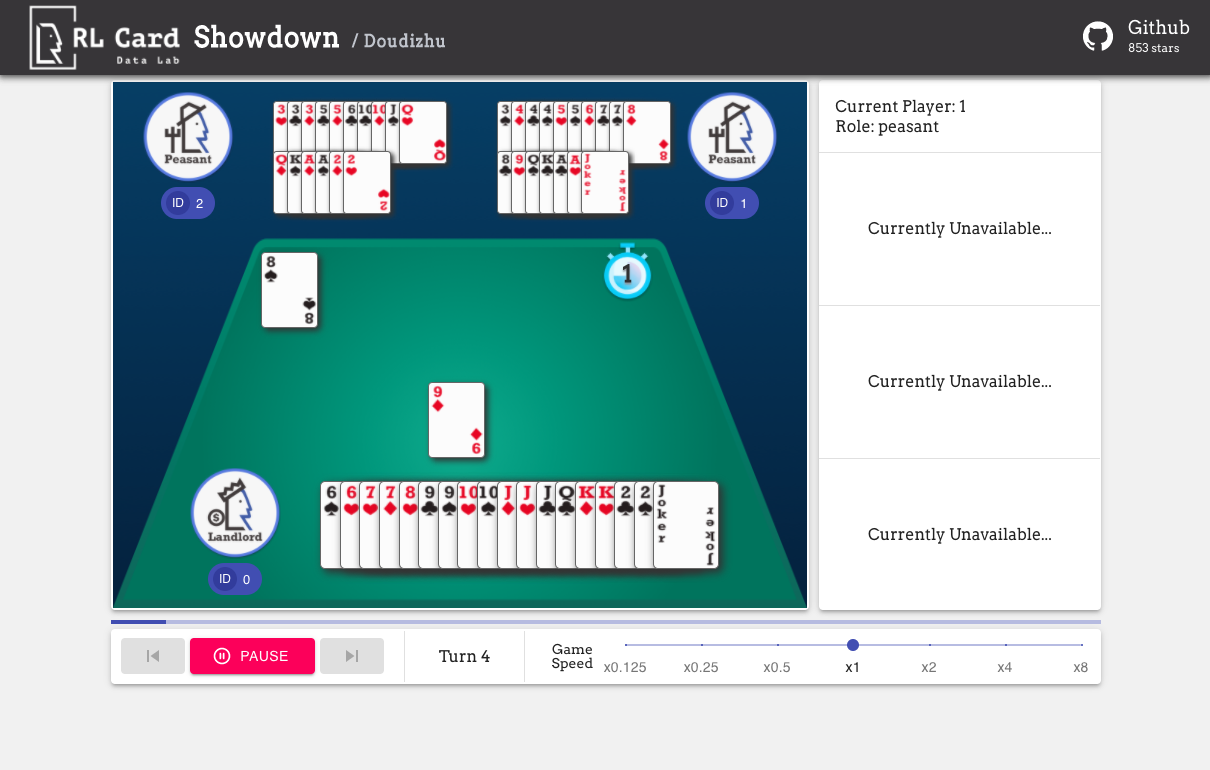
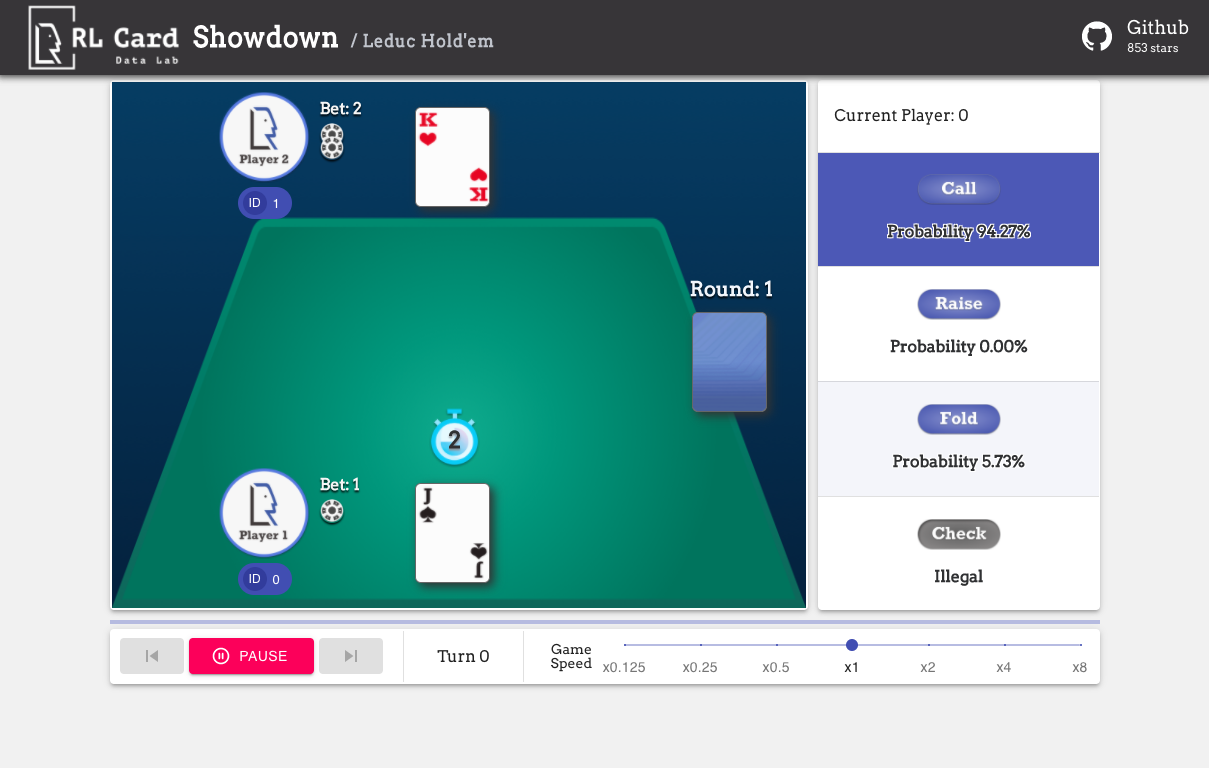
نحن نقدم تقدير التعقيد للألعاب على عدة جوانب. رقم Infoset: عدد مجموعات المعلومات ؛ حجم Infoset: متوسط عدد الحالات في مجموعة معلومات واحدة ؛ حجم الإجراء: حجم مساحة العمل. الاسم: الاسم الذي يجب أن يتم تمريره إلى rlcard.make لإنشاء بيئة اللعبة. نقدم أيضًا الرابط إلى الوثائق والمثال العشوائي.
| لعبة | رقم Infoset | حجم Infoset | حجم العمل | اسم | الاستخدام |
|---|---|---|---|---|---|
| Blackjack (ويكي ، بايك) | 10^3 | 10^1 | 10^0 | بلاك جاك | مستند ، مثال |
| ليدوك هولد (ورقة) | 10^2 | 10^2 | 10^0 | ليدوك هولديم | مستند ، مثال |
| Limit Texas Hold'em (Wiki ، Baike) | 10^14 | 10^3 | 10^0 | الحد الأقصى | مستند ، مثال |
| دو ديزو (ويكي ، بايكي) | 10^53 ~ 10^83 | 10^23 | 10^4 | دوديزو | مستند ، مثال |
| Mahjong (ويكي ، بايك) | 10^121 | 10^48 | 10^2 | محجونغ | مستند ، مثال |
| No-Limit Texas Hold'em (Wiki ، Baike) | 10^162 | 10^3 | 10^4 | بدون حدود | مستند ، مثال |
| Uno (ويكي ، بايك) | 10^163 | 10^10 | 10^1 | Uno | مستند ، مثال |
| جين رومي (ويكي ، بايك) | 10^52 | - | - | الجن روم | مستند ، مثال |
| جسر (ويكي ، بايك) | - | - | كوبري | مستند ، مثال |
| خوارزمية | مثال | مرجع |
|---|---|---|
| Deep Monte-Carlo (DMC) | أمثلة/run_dmc.py | [ورق] |
| التعلم Q العميق (DQN) | أمثلة/run_rl.py | [ورق] |
| اللعب الذاتي الوهمي العصبي (NFSP) | أمثلة/run_rl.py | [ورق] |
| تقليل الأسف المعاكس (CFR) | أمثلة/run_cfr.py | [ورق] |
نحن نقدم حديقة حيوان نموذجية لتكون بمثابة خطوط الأساس.
| نموذج | توضيح |
|---|---|
| LEDUC-HOLDEM-CFR | نموذج CFR (أخذ عينات من الصدفة) مسبقًا على Leduc Hold'em |
| LEDUC-Holdemm-Rule-V1 | النموذج القائم على القواعد لـ Leduc Hold'em ، V1 |
| LEDUC-Holdemm-Rule-V2 | النموذج القائم على القواعد لـ Leduc Hold'em ، v2 |
| Uno-Rule-V1 | نموذج قائم على القواعد لـ UNO ، V1 |
| الحد الأقصى--قسمة-V1 | نموذج قائم على القواعد للحد من تكساس هولد ، v1 |
| Doudizhu-Rule-V1 | نموذج قائم على القواعد لـ Dou Dizhu ، V1 |
| الجن-رومي- القاعدة | نموذج قاعدة قواعد Gin Rummy |
يمكنك استخدام الواجهة التالية لصنع بيئة. يمكنك تحديد بعض التكوينات اختياريا مع قاموس.
env_id هي سلسلة من البيئة. config هو قاموس يحدد بعض تكوينات البيئة ، والتي هي كما يلي.seed : الافتراضي None . تعيين بيئة بذرة عشوائية محلية لتكاثر النتائج.allow_step_back : False . True إذا سمحت وظيفة step_back بالتجاوز للخلف في الشجرة.game_ . حاليًا ، نحن ندعم فقط game_num_players في Blackjack ،.بمجرد إنشاء Environemnt ، يمكننا الوصول إلى بعض المعلومات عن اللعبة.
الدولة هو قاموس بيثون. وهو يتألف من state['obs'] ، state['legal_actions'] ، state['raw_obs'] state['raw_legal_actions'] .
توفر الواجهات التالية استخدامًا أساسيًا. إنه سهل الاستخدام ولكنه يحتوي على افتراضات على الوكيل. يجب أن يتبع الوكيل قالب الوكيل.
agents هي قائمة كائن Agent . يجب أن يكون طول القائمة مساوياً لعدد اللاعبين في اللعبة.set_agents . إذا كان is_training True ، فسيستخدم وظيفة step في الوكيل لتشغيل اللعبة. إذا كان is_training False ، فسيتم استدعاء eval_step بدلاً من ذلك.للاستخدام المتقدم ، تتيح الواجهات التالية عمليات مرنة على شجرة اللعبة. هذه الواجهات لا تجعل أي آثار على الوكيل.
action خامًا أو عدد صحيح ؛ يجب أن يكون raw_action True إذا كان الإجراء هو إجراء الخام (سلسلة).allow_step_back True . خذ خطوة واحدة للخلف. يمكن استخدام هذا للخوارزميات التي تعمل على شجرة اللعبة ، مثل CFR (أخذ العينات).True إذا انتهت اللعبة الحالية. otherewise ، العودة False .player_id .يتم سرد أغراض الوحدات الرئيسية على النحو التالي:
لمزيد من الوثائق ، يرجى الرجوع إلى مستندات المقدمات العامة. وثائق API متوفرة على موقعنا.
المساهمة في هذا المشروع موضع تقدير كبير! يرجى إنشاء مشكلة للتعليقات/الأخطاء. إذا كنت ترغب في المساهمة في الرموز ، فيرجى الرجوع إلى دليل المساهمة. إذا كان لديك أي أسئلة ، فيرجى الاتصال بـ Daochen Zha مع [email protected].
نود أن نشكر JJ World Network Technology Co. ، Ltd على الدعم السخي وجميع المساهمات من المساهمين في المجتمع.


