text embeddings inference
v1.5.1
حل استنتاج سريع النيران لنماذج تضمينات النص.
معيار لـ BAAI/BGE-BASE-EN-V1.5 على NVIDIA A10 بطول تسلسل 512 رمزًا:
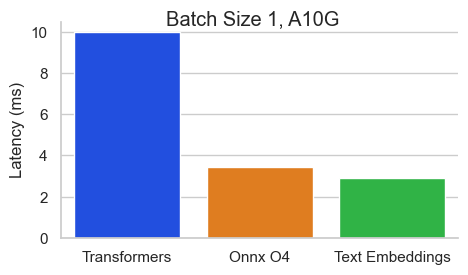
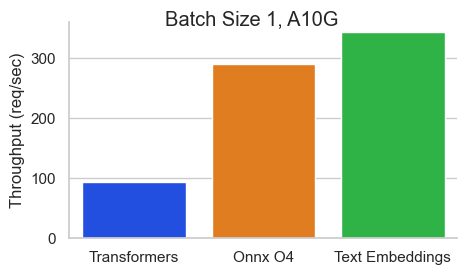
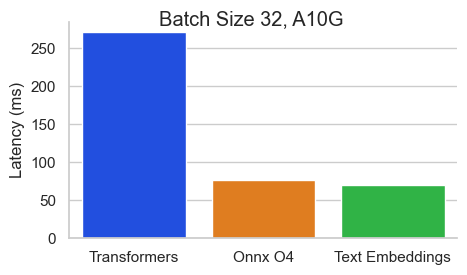
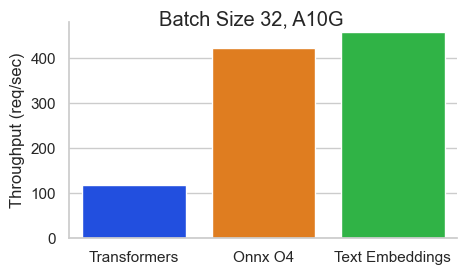
استدلال تضمينات النص (TEI) هو مجموعة أدوات لنشر وخدمة تضمينات النص المفتوح المصدر ونماذج تصنيف التسلسل. يتيح TEI الاستخراج عالي الأداء للنماذج الأكثر شعبية ، بما في ذلك flagembedding و ember و GTE و E5. تنفذ TEI العديد من الميزات مثل:
يدعم استدلال تضمينات النص حاليًا نماذج Nomic و Bert و Camembert و XLM-Roberta ذات المواقف المطلقة ونماذج Jinabert مع مواقف Alibi و Mistral و Alibaba GTE و QWEN2 مع مواقف الحبل.
فيما يلي بعض الأمثلة على النماذج المدعومة حاليًا:
| رتبة MTEB | حجم النموذج | نوع النموذج | معرف النموذج |
|---|---|---|---|
| 1 | 7 ب (باهظ الثمن) | خطأ | Salesforce/SFR-Embedding-2_r |
| 2 | 7 ب (باهظ الثمن) | Qwen2 | Alibaba-NLP/GTE-QWEN2-7B-instruct |
| 9 | 1.5 ب (باهظ الثمن) | Qwen2 | Alibaba-NLP/GTE-QWEN2-1.5B-instruct |
| 15 | 0.4b | علي بابا GTE | Alibaba-NLP/GTE-LARGE-EN-V1.5 |
| 20 | 0.3b | بيرت | حيث uae/uae-large-v1 |
| 24 | 0.5B | XLM-Roberta | intfloat/multilingual-e5-large-instruct |
| ن/أ | 0.1B | Nomicbert | Nomic-AA/NOMIC-EMBED-TEXT-V1 |
| ن/أ | 0.1B | Nomicbert | Nomic-AA/NOMIC-EMBED-TEXT-V1.5 |
| ن/أ | 0.1B | جينابيرت | Jinaai/Jina-Embeddings-V2-Base-en |
| ن/أ | 0.1B | جينابيرت | Jinaai/Jina-Embeddings-V2-Base-Code |
لاستكشاف قائمة أفضل نماذج تضمينات النصوص ، تفضل بزيارة لوحة المتصدرين المعيارين في النص الضخم (MTEB).
يدعم استدلال تضمينات النص حاليًا نماذج تصنيف تسلسل Camembert و XLM-Roberta مع مواقف مطلقة.
فيما يلي بعض الأمثلة على النماذج المدعومة حاليًا:
| مهمة | نوع النموذج | معرف النموذج |
|---|---|---|
| إعادة الرابطة | XLM-Roberta | باي/bge-reranker-large |
| إعادة الرابطة | XLM-Roberta | Baai/Bge-Reranker-base |
| إعادة الرابطة | GTE | Alibaba-NLP/GTE-MURILITALAL-RERANKER-BASE |
| تحليل المشاعر | روبرتا | Samlowe/Roberta-Base-Go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelثم يمكنك تقديم طلبات مثل
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json 'ملاحظة: لاستخدام وحدات معالجة الرسومات ، تحتاج إلى تثبيت مجموعة أدوات حاوية NVIDIA. يجب أن تكون برامج تشغيل NVIDIA على جهازك متوافقة مع الإصدار 12.2 CUDA أو أعلى.
لرؤية جميع الخيارات لخدمة النماذج الخاصة بك:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
يشحن استدلال تدمسينات النص مع صور Docker متعددة يمكنك استخدامها لاستهداف الواجهة الخلفية المحددة:
| بنيان | صورة |
|---|---|
| وحدة المعالجة المركزية | ghcr.io/huggingface/text-embeddings-- |
| فولتا | غير مدعوم |
| Turing (T4 ، RTX 2000 Series ، ...) | ghcr.io/huggingface/text-embeddings--- |
| Ampere 80 (A100 ، A30) | ghcr.io/huggingface/text-embeddings---- |
| أمبير 86 (A10 ، A40 ، ...) | ghcr.io/huggingface/text-embeddings-- |
| Ada Lovelace (سلسلة RTX 4000 ، ...) | ghcr.io/huggingface/text-embeddings-- |
| هوبر (H100) | ghcr.io/huggingface/text-embeddings--- |
تحذير : يتم إيقاف انتباه الفلاش بشكل افتراضي لصورة Turing لأنها تعاني من مشكلات دقيقة. يمكنك تشغيل Flash Vense V1 باستخدام استخدام USE_FLASH_ATTENTION=True .
يمكنك الرجوع إلى وثائق OpenAPI لمواجهة واجهة text-embeddings-inference باستخدام مسار /docs . يتوفر واجهة المستخدم Swagger أيضًا على: https://huggingface.github.io/text-embeddings-
لديك خيار الاستفادة من متغير بيئة HF_API_TOKEN لتكوين الرمز المميز الذي يستخدمه text-embeddings-inference . هذا يتيح لك الوصول إلى الموارد المحمية.
على سبيل المثال:
HF_API_TOKEN=<your cli READ token>أو مع Docker:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelلنشر استنتاج تضمينات النص في بيئة مغطاة بالهواء ، قم أولاً بتنزيل الأوزان ثم قم بتركيبها داخل الحاوية باستخدام وحدة تخزين.
على سبيل المثال:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference V0.4.0 تمت إضافة دعم لكامبيرت وروبرتا و XLM-Roberta و GTE Sequence Models. نماذج RESTRELS هي نماذج تصنيف تصنيف التسلسل مع فئة واحدة تسجل التشابه بين الاستعلام والنص.
شاهد هذا المدونة من قبل فريق Llamaindex لفهم كيف يمكنك استخدام نماذج RESTROLES في خط أنابيب الخرقة لتحسين أداء المصب.
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelوبعد ذلك يمكنك تصنيف التشابه بين الاستعلام وقائمة النصوص مع:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' يمكنك أيضًا استخدام نماذج تصنيف التسلسل الكلاسيكية مثل SamLowe/roberta-base-go_emotions :
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model بمجرد نشر النموذج ، يمكنك استخدام نقطة نهاية predict للحصول على المشاعر المرتبطة أكثر بالمدخلات:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'يمكنك اختيار تنشيط تجميع splade لبنية Bert و Distilbert Maskedlm:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade بمجرد نشر النموذج ، يمكنك استخدام نقطة النهاية /embed_sparse للحصول على التضمين المتفرق:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' تتم أداة إعادة text-embeddings-inference مع تتبع موزعة باستخدام قياس الأوبنتيل. يمكنك استخدام هذه الميزة عن طريق تعيين العنوان إلى جامع OTLP مع وسيطة- --otlp-endpoint .
يوفر text-embeddings-inference تطبيقات GRPC كبديل ل API HTTP الافتراضي للنشر عالي الأداء. يمكن العثور على تعريف Protobuf API هنا.
يمكنك استخدام API GRPC عن طريق إضافة علامة -grpc إلى أي صورة TEI Docker. على سبيل المثال:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed يمكنك أيضًا اختيار تثبيت text-embeddings-inference محليًا.
أول تثبيت الصدأ:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shثم قم بالتشغيل:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalيمكنك الآن تشغيل استدلال تضمينات النص على وحدة المعالجة المركزية مع:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080ملاحظة: في بعض الآلات ، قد تحتاج أيضًا إلى مكتبات OpenSSL و GCC. على آلات Linux ، قم بتشغيل:
sudo apt-get install libssl-dev gcc -yلا يتم دعم وحدات معالجة الرسومات مع قدرات حساب CUDA <7.5 (V100 ، Titan V ، GTX 1000 Series ، ...).
تأكد من تثبيت CUDA وسائقي NVIDIA. يجب أن تكون برامج تشغيل NVIDIA على جهازك متوافقة مع الإصدار 12.2 CUDA أو أعلى. تحتاج أيضًا إلى إضافة ثنائيات nvidia إلى طريقك:
export PATH= $PATH :/usr/local/cuda/binثم قم بالتشغيل:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresيمكنك الآن إطلاق استنتاج نصي على إشراف على وحدة معالجة الرسومات مع:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080يمكنك بناء حاوية وحدة المعالجة المركزية مع:
docker build .لإنشاء حاويات CUDA ، تحتاج إلى معرفة غطاء حساب GPU الذي ستستخدمه في وقت التشغيل.
ثم يمكنك بناء الحاوية مع:
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capكما هو موضح هنا MPS جاهزة ، صورة Docker ARM64 ، لا يتم دعم المعادن / النواب عبر Docker. على هذا النحو ، سيكون الاستدلال ملزمة للوحدة المعالجة المركزية ، وعلى الأرجح بطيئة جدًا عند استخدام صورة Docker هذه على وحدة المعالجة المركزية ARM M1/M2.
docker build . -f Dockerfile --platform=linux/arm64


