kubeai
helm-chart-models-0.9.0
احصل على استنتاج يعمل على kubernetes: LLMs ، التضمينات ، الكلام إلى النص.
✅ استبدال الانخفاض في Openai مع توافق API
⚖ النطاق من الصفر ، التلقائي بناءً على الحمل
؟ تخدم نماذج توليد النص (LLMS ، VLMS ، إلخ)
الكلام إلى إرسال رسالة إلى API
؟ التضمين/متجه API
متعدد المنصات: وحدة المعالجة المركزية فقط ، GPU ، TPU
؟ التخزين المؤقت للنموذج مع أنظمة الملفات المشتركة (EFS ، Filestore ، إلخ)
تبعيات صفر (لا تعتمد على ISTIO ، Knative ، وما إلى ذلك)
المدرجة في واجهة المستخدم (OpenWebui)
؟ تعمل خوادم نموذج OSS (Vllm ، Ollama ، FasterWhisper ، Infinity)
✉ دفق/استنتاج الدُفعة عبر تكامل المراسلة (كافكا ، PubSub ، إلخ)
ونقلت من المجتمع:
حل قابل لإعادة الاستخدام ، مجردة جيدًا لتشغيل LLMS - Mike Ensor
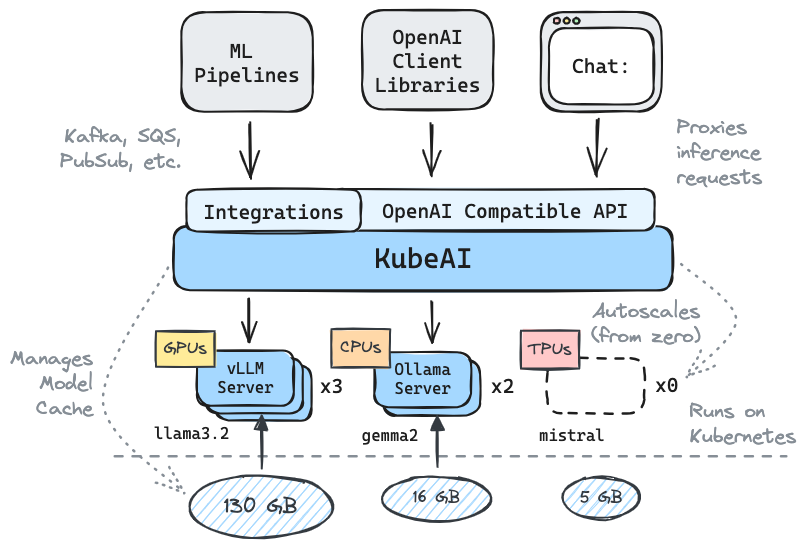
يخدم Kubeai واجهة برمجة تطبيقات HTTP المتوافقة مع Openai. يمكن للمسؤولين تكوين نماذج ML عبر kind: Model الموارد المخصصة Kubernetes. يمكن اعتبار Kubeai كمشغل نموذج (انظر نمط المشغل) الذي يدير خوادم VLLM و Ollama.
إنشاء مجموعة محلية باستخدام نوع أو minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startأضف مستودع Kubeai Helm.
helm repo add kubeai https://www.kubeai.org
helm repo updateقم بتثبيت kubeai وانتظر أن تكون جميع المكونات جاهزة (قد تستغرق دقيقة).
helm install kubeai kubeai/kubeai --wait --timeout 10mتثبيت بعض النماذج المحددة مسبقا.
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlقبل التقدم إلى الخطوات التالية ، ابدأ مشاهدة على القرون في محطة مستقلة لمعرفة كيف تنشر Kubeai نماذج.
kubectl get pods --watch نظرًا لأننا وضعنا minReplicas: 1 لنموذج Gemma ، يجب أن ترى جراب نموذج بالفعل.
ابدأ منفذًا محليًا إلى الأمام إلى واجهة مستخدم الدردشة المجمعة.
kubectl port-forward svc/openwebui 8000:80افتح الآن متصفحك إلى LocalHost: 8000 وحدد نموذج GEMMA لبدء الدردشة معه.
إذا عدت إلى المتصفح وبدأت دردشة مع QWEN2 ، ستلاحظ أن الأمر سيستغرق بعض الوقت للرد في البداية. هذا لأننا نضع minReplicas: 0 لهذا النموذج ويحتاج kubeai إلى تدوير جراب جديد (يمكنك التحقق من kubectl get models -oyaml qwen2-500m-cpu ).
الخروج من وثائقنا على kubeai.org للعثور على معلومات حول:
قائمة المتبنين المعروفين:
| اسم | وصف | وصلة |
|---|---|---|
| تلسكوب | يستخدم Telescope kubeai لاستدلال LLM على نطاق واسع متعدد المناطق. | Trytelescope.ai |
| حافة موزعة السحابة من Google | يتم تضمين Kubeai كعمارة مرجعية للاستدلال على الحافة. | LinkedIn ، Gitlab |
| لامدا | يمكنك تجربة Kubeai على Cloud Lambda AI Developer Cloud. انظر التعليمي والفيديو Lambda. | لامدا |
إذا كنت تستخدم kubeai وترغب في إدراجها كقائد بالتبني ، فيرجى عمل العلاقات العامة.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* ملاحظة: ولد Kubeai من مشروع يسمى Lingo والذي كان وكيل Kubernetes LLM بسيط مع التلقائي الأساسي. قمنا بإعادة إطلاق المشروع باسم Kubeai (أواخر أغسطس 2024) وقمنا بتوسيع خريطة الطريق إلى ما هو عليه اليوم.
؟ لا تنس أن تسقط لنا نجمة على جيثب واتبع الريبو للبقاء على اطلاع دائم!
أخبرنا بالميزات التي تهتم برؤيتها أو التواصل مع الأسئلة. قم بزيارة قناة Discord للانضمام إلى المناقشة!
أو فقط تواصل على LinkedIn إذا كنت ترغب في الاتصال:


