Reading_groups
1.0.0
قوة الحوسبة : تُظهر الكثير من الأدلة أن التقدم في التعلم الآلي مدفوع إلى حد كبير بالحوسبة ، وليس البحث ، يرجى الرجوع إلى "الدرس المرير" ، وغالبًا ما تكون هناك ظواهر للظهور والتجانس. أظهرت الدراسات أن استخدام حوسبة الذكاء الاصطناعي يتضاعف كل 3.4 أشهر تقريبًا ، في حين يتضاعف تحسين الكفاءة كل 16 شهرًا. من بينها ، يتم تشغيل كمية الحساب بشكل أساسي عن طريق الحوسبة ، في حين أن الكفاءة مدفوعة بالبحث. هذا يعني أن نمو الحوسبة قد سيطر تاريخياً على التقدم في التعلم الآلي وحقوله الفرعية. وقد ثبت ذلك كذلك من خلال ظهور GPT-4. على الرغم من ذلك ، ما زلنا بحاجة إلى الانتباه إلى ما إذا كان سيكون هناك بنية أكثر تخريبًا في المستقبل ، مثل S4. تستند معظم النقاط الساخنة الحالية لـ NLP Research إلى LLM أكثر تقدمًا (~ 100b ،
لمزيد من أوراق موضوعات LLM ، يرجى الرجوع إلى هنا وهنا.
أوراق ( فئة خشنة )
الموارد
【اختبار على GPT-4 ، القيد】 سباركس الذكاء العام الاصطناعي: التجارب المبكرة مع GPT-4
【تعليمات الأوراق ، بما في ذلك SFT ، PPO ، وما إلى ذلك ، واحدة من أهم المقالات】 نماذج لغة التدريب لمتابعة التعليمات مع التعليقات البشرية
【الإشراف القابل للتطوير: كيف يمكن للبشر مواصلة تحسين نماذجهم بعد أن تتجاوز نماذجهم مهامهم؟ 】 قياس التقدم في الإشراف القابل للتطوير لنماذج اللغة الكبيرة
【تعريف المحاذاة ، التي تنتجها DeepMind】 محاذاة وكلاء اللغة
مساعد اللغة العامة كمختبر للمحاذاة
[الورق الرجعية ، تم البحث في النموذج باستخدام CCA+] تحسين نماذج اللغة من خلال الاسترداد من تريليونات الرموز
نماذج لغة صقلها من التفضيلات البشرية
تدريب مساعد مفيد وغير ضار مع التعلم التعزيز من ردود الفعل البشرية
【نموذج كبير باللغة الصينية والإنجليزية ، يتجاوز GPT-3】 GLM-130B: نموذج مفتوح ثنائي اللغة مسبقًا
【التحسين الهدف قبل التدريب】 UL2: موحد نماذج تعلم اللغة
【المعايير الجديدة للمحاذاة ، والمكتبات النموذجية والأساليب الجديدة】 هل التعلم التعزيز (وليس) لمعالجة اللغة الطبيعية؟: المعايير ، وخطوط الأساس ، وكتل البناء لتحسين سياسة اللغة الطبيعية
【MLM بدون علامات [Mask] من خلال التكنولوجيا】 نقص التمثيل في نمذجة اللغة المقنعة
【رسالة نصية إلى تدريب الصور تخفف من احتياجات المفردات ويقاوم بعض الهجمات】 نمذجة اللغة مع وحدات البكسل
Lexmae: معجم بوتلنك مسبق لاسترجاع واسع النطاق
incoder: نموذج توليدي لـ Code Infilling and Synthesis
[بحث الصور المتعلقة بالنص لنموذج اللغة قبل التدريب] النمذجة اللغوية المرصعة بصريًا
نموذج لغة غير متجانس للإنهاء الذاتي
【مقارنة وضبط ردود الفعل السلبية من خلال تصميم propt】 سلسلة من نماذج اللغة المتأخرة مع ردود الفعل
【نموذج العصفور】 تحسين محاذاة وكلاء الحوار عبر الأحكام البشرية المستهدفة
[استخدم معلمات نموذج صغيرة لتسريع عملية تدريب النموذج الكبير (لا تبدأ من نقطة الصفر)] تعلم نماذج نماذج مسبقة للتدريب على المحولات الفعالة
[نموذج اندماج المعرفة شبه المعرفة في MOE لمصادر المعرفة المتعددة] المعرفة في السياق: نحو نماذج لغة شبه براريامي
[Merge Method لدمج نماذج مدربة متعددة على مجموعات البيانات المختلفة] Dataless المعرفة الاندماج عن طريق دمج أوزان نماذج اللغة
[من الملهم للغاية أن آلية البحث تحل محل البنية العامة لـ FFN في Transformer (× 2.54 Time) لفصل المعرفة المخزنة في معلمات النموذج]
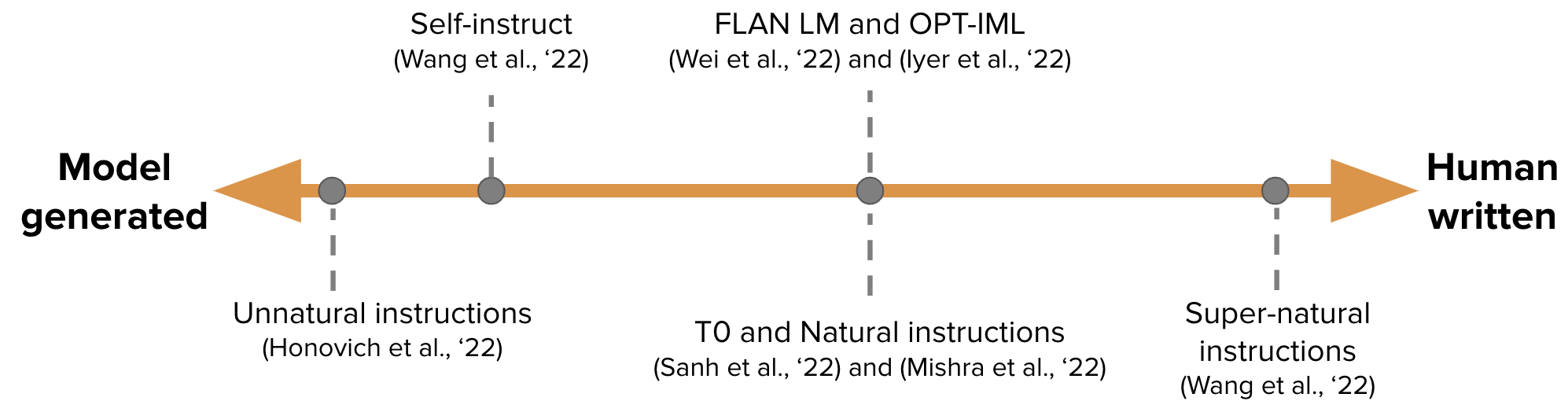
【إنشاء بيانات ضبط التعليمات تلقائيًا لتدريب GPT-3】 الإقرار الذاتي: مواءمة نموذج اللغة مع تعليمات تم إنشاؤها ذاتيًا
- 
نحو نماذج اللغة المقنعة المعتمدة بشكل مشروط
【المعايرة بشكل تكرار مصححات مستقلة تم إنشاؤها بشكل غير كامل ، مقالة متابعة شون ويلك】 توليد تسلسل عن طريق التعلم إلى تصحيح ذاتي
[التعلم المستمر: أضف propt للمهمة الجديدة ، وتبقى ProPT للمهمة السابقة والنموذج الكبير مطالبات تدريجية: التعلم المستمر لنماذج اللغة دون نسيان
[EMNLP 2022 ، التحديث المستمر للنموذج] memprompt: تحرير موجه بمساعدة الذاكرة مع ملاحظات المستخدم
【العمارة العصبية الجديدة (FOLNET) ، والتي تحتوي على التحيز الحث المنطقي من الدرجة الأولى】 تمثيل لغة التعلم مع التحيز الاستقرائي المنطقي
GANLM: التدريب قبل الترميز مع تمييز إضافي
【نموذج لغة ما قبل التدريب على أساس نماذج فضاء الحالة ، ويتجاوز bert】 pretring دون اهتمام
[النظر في ردود الفعل البشرية أثناء النماذج اللغوية قبل التدريب] مع التفضيلات البشرية
[Meta Open Source Model Llama ، 7B-65B ، يدرب نماذج صغيرة أكثر من المعتاد ، وتحقيق الأداء الأمثل في ظل ميزانيات الاستدلال المختلفة] Llama: نماذج لغة أساس مفتوحة وفعالة
[تعليم نماذج اللغة الكبيرة للقرص الذاتي وشرح الكود الذي تم إنشاؤه من خلال عدد صغير من الأمثلة ، ولكن تم استخدامها مثل هذا الآن] تدريس نماذج لغة كبيرة للذات
إلى أي مدى يمكن أن تذهب الجمال؟
ليما: أقل من ذلك بالنسبة للمحاذاة
【شجرة الفكر ، أشبه بالألفاجو-حل المشكلات المتعمدة مع نماذج اللغة الكبيرة
【طريقة التفكير متعددة الخطوات لتطبيق ICL ملهم للغاية】 React: تآزر التفكير والتمثيل في نماذج اللغة
【COT ينشئ رمز البرنامج مباشرة ، ثم يتيح لمترجم Python تنفيذ برنامج الأفكار المطالبة: Disentangling Compution من التفكير في مهام التفكير العددي
[النموذج الكبير يولد سياق الأدلة مباشرة] توليد بدلاً من استرداده: نماذج اللغة الكبيرة هي مولدات سياق قوية
【نموذج الكتابة مع 4 عمليات محددة】 الأقران: نموذج لغة تعاونية
【الجمع بين Python و SQL Executors والنماذج الكبيرة】 نماذج لغة الربط باللغات الرمزية
[استرداد رمز توليد المستندات] المستند: إنشاء رمز عن طريق استرداد المستندات
[سيكون هناك العديد من المقالات في Grounding+LLM في السلسلة التالية] LLM-Planner: تخطيط قليلة الطلقة للعوامل المجسدة مع نماذج لغة كبيرة
【الجيل الذاتي (تم التحقق منه باستخدام بيانات تدريب Python)】 يمكن أن تعلمنا نماذج اللغة نفسها لبرمجة أفضل
المقالات ذات الصلة: متخصصة نماذج لغة أصغر نحو التفكير متعدد الخطوات
Star: Bootstrapping Reasoring مع التفكير ، من Neupips 22 (قم بإنشاء بيانات COT لضبط النموذج الدقيق) ، مما تسبب في سلسلة من مقالات COT التي تدرس النماذج الصغيرة.
أفكار مماثلة [تقطير المعرفة] تدريس نماذج اللغة الصغيرة للتسبب والتعلم من خلال تقطير السياق
الأفكار المماثلة لمجموعات Kaist و Xiang Ren ([Cot Rationale Tuning (Professor)] Pinto: منطق اللغة المؤمنين باستخدام المبررات المولدة ، وما إلى ذلك) ونماذج اللغة الكبيرة تعتبر المعلمين
نماذج تحلل المشكلة في قطارات ETH ونماذج حل المشكلات بشكل منفصل] تقطير إمكانات التفكير متعددة الخطوات في نماذج اللغة الكبيرة في نماذج أصغر من خلال التحلل الدلالي
【دع النماذج الصغيرة تتعلم قدرات سرير الأطفال】 التقطير التعليمي أثناء السياق: نقل قدرة التعلم القليلة على التعلم لنماذج اللغة المسبقة مسبقًا
【نموذج كبير يقوم بتدريس النماذج الصغيرة cot】 نماذج اللغة الكبيرة تعتبر المعلمين
[النموذج الكبير يولد أدلة (تلاوة) ثم يقوم بنماذج اللغة المغلقة في كتاب عينة صغيرة
[أساليب اللغة الطبيعية للمناطق الاستقرائية] نماذج اللغة كأسباب استقرائية
[يتم استخدام GPT-3 لتعليق البيانات (مثل التصنيف العاطفي)] هل GPT-3 عبارة عن مسيرة جيدة للبيانات؟
【نماذج لزيادة البيانات بناءً على التدريب متعدد المهام لتقليل عينة تكبير البيانات】 Knowda: نموذج خليط المعرفة الكل في واحد لزيادة البيانات في NLP منخفضة الموارد
【عمل التخطيط الإجرائي ، غير مهتم بالوقت الذي يتواجد فيه التخطيط الإجرائي العصبي مع الطالب المنطقي
[الهدف: إنشاء مقالات صحيحة من الناحية الواقعية للاستعلامات عن طريق التأريض على مجموعة الويب الكبيرة
【الجمع بين نتائج محاكاة الفيزياء الخارجية في السياق】 عين العقل: نموذج اللغة المسترقة المنطق من خلال المحاكاة
[استرداد مهمة تعزيز COT للقيام بالمعرفة المكثفة] استرجاع التراجع مع التفكير في سلسلة أفكار للأسئلة متعددة الخطوات كثيفة المعرفة
【قارن المعرفة المحتملة (الثنائية) في نموذج لغة التعرف غير الخاضع للإشراف】 اكتشاف المعرفة الكامنة في نماذج اللغة دون إشراف
[Percy Liang Group ، محرك البحث الموثوق به ، 51.5 ٪ فقط من الجمل التي تم إنشاؤها مدعومة بالكامل من خلال الاستشهادات] تقييم التحقق من التحقق في محركات البحث التوليدي
يؤدي التقدم التقدمي إلى تحسين التفكير في نماذج اللغة الكبيرة
التحديد الذاتي للنماذج اللغوية التي تعتمد على المبدأ من الصفر مع الحد الأدنى من الإشراف البشري
الحكم LLM-AS-A-DUCK
[في رأيي ، إنها واحدة من أهم المقالات. التدريب وعرض وعمق تفاصيل العمارة مثل العرض والعمق.
[واحدة من أهم المقالات الأخرى ، Chinchilla ، تحت الحوسبة المحدودة ، فإن النموذج الأمثل ليس هو النموذج الأكبر ، ولكنه نموذج أصغر مدرب مع المزيد من البيانات (60-70 ب)
[ما هي أهداف الهندسة المعمارية والتحسين التي تساعد على التعميم الصفري على العينة] ما هي العمارة النموذجية اللغوية والهدف المسبق بشكل أفضل لتعميم الصفر؟
【تحفظ عملية التعلم "Epiphany"-تكوين الدائرة-> تنظيف】 مقاييس التقدم للمسعات عبر التفسير الميكانيكي
[تحقق من خصائص النموذج القائم على البحث وتجد أن كلاهما ذو منطق محدود] يمكن أن يسبب النماذج اللغوية المستردة؟
[إطار تقييم التفاعل بين اللغة البشرية AI] تقييم تفاعل نموذج اللغة البشرية
ما هي خوارزمية التعلم التعليمية في السياق؟
【تحرير النموذج ، هذا هو الموضوع الساخن】 ذاكرة تحرير الكتلة في محول
[حساسية النموذج للسياق غير ذي صلة ، وإضافة معلومات غير ذات صلة إلى الأمثلة في المطالبة وإضافة إرشادات تتجاهل السياق غير ذي صلة بحل جزئيًا] يمكن أن يصرف نماذج اللغة الكبيرة بسهولة عن طريق سياق غير ذي صلة
【سيظهر COT الصفر التحيز والسمية في ظل قضايا حساسة】 في الفكر الثاني ، دعونا لا نفكر في خطوة!
【COT من النموذج الكبير يحتوي على إمكانيات متعددة اللغات】 نماذج اللغة هي أسباب متعددة اللغات الفكر
[كلما انخفض الارتباك في تسلسلات سريعة مختلفة ، كلما كان أداء الغموض بشكل أفضل في نماذج اللغة من خلال تقدير الحيرة
[مهمة دقة الدقة الثنائية للنماذج الكبيرة ، هذا الاقتراح صعب وليس هناك ظاهرة تحجيم] نماذج لغوية كبيرة ليست اتصالات صفر (https://github.com/google/big-bench/tree/main/bigbench/ Benchmark_tasks/ الضمني)
【المطالبة القائمة على التعقيد للتفكير متعدد الخطوات
ما الذي يهم التقليم المنظم لنماذج اللغة التوليدية؟
[مجموعة بيانات Ambibench ، غموض المهمة: يعمل نموذج التحجيم RLHF بشكل أفضل في مهام الغموض. يعد النقل الدقيق أكثر فائدة من طلقة قليلة مما يؤدي إلى غموض المهمة في البشر ونماذج اللغة
【اختبار GPT-3 ، بما في ذلك الذاكرة ، المعايرة ، التحيز ، إلخ.
[دراسة OSU أي جزء من COT فعال في الأداء] نحو فهم سلسلة الفكرة: دراسة تجريبية لما يهم
[البحث عن نموذج اللغات المتقاطع للمطالبات المنفصلة] هل يمكن أن يطالب استخراج المعلومات المنفصلة بالتعميم عبر نماذج اللغة؟
【معدل الذاكرة هو العلاقة الخطية اللوغاريتمية مع حجم النموذج وطول البادئة ومعدل التكرار في التدريب】 تحديد الكميات عبر نماذج اللغة العصبية
【إنها ملهمة للغاية ، وتحلل المشكلة إلى أسئلة فرعية من خلال تكرار GPT والإجابة عليها】 قياس وتضييق فجوة التكوين في نماذج اللغة
[اختبار مماثل لـ GPT-3 على غرار أسئلة ذكاء الموظفين المدنيين] المنطق التماثلي الناشئ في نماذج اللغة الكبيرة
【التدريب على النص القصير ، اختبار النص الطويل ، تقييم القدرة على التكيف المتغير النموذج】 محول الطول الطول
[عندما لا تثق في نماذج اللغة: التحقيق في فعالية وقيود الذكريات البارمية وغير البارامترية
【ICL هو شكل آخر من أشكال التحديث التدرج】 لماذا يمكن لـ GPT التعلم في السياق؟
هل GPT-3 مختل عقليا؟
[بحث حول عملية تدريب نموذج OPT بأحجام مختلفة ، ووجد أن الارتباك هو مؤشر على مسارات التدريب على ICL] لنماذج اللغة عبر المقاييس
[EMNLP 2022 ، يحتوي مجموعة اللغة الإنجليزية النقية التي تم تدريبها مسبقًا على لغات أخرى ، وقد تساعد إمكانات اللغة المتقاطعة للنموذج من تسرب البيانات] تلوث اللغة في شرح القدرات المتقاطعة للنماذج الإنجليزية المسبقة
[تجاوزات الدلالات الدلالية واستخدام المعلومات في PORT هي قدرة زيادة على الطفعة] نماذج لغوية أكبر تقوم بالتعلم داخل السياق بشكل مختلف
【EMNLP 2022 النتائج】 ما هو نموذج اللغة لتدريب إذا كان لديك مليون ساعة GPU؟
[إدخال تقنية CFG أثناء التفكير بشكل كبير يحسن قدرة الامتثال للتعليمات للنماذج الصغيرة] البقاء على الموضوع مع إرشادات خالية من المصنف
【قم بتدريب طراز Llama الخاص بك باستخدام GPT-4 من Openai ، ولا يمكنني إلا أن أقول إنني معجب بك】 تعليمات مع GPT-4
الانعكاس: عامل مستقل مع ذاكرة ديناميكية وانعكاس ذاتي
【تعلم النمط الشخصي التعلم ، الاختيار】 مطالبات قابلة للتمديد لنماذج اللغة
[تسريع فك تشفير النماذج الكبيرة ، باستخدام الإجماع المباشر بين النماذج الصغيرة والنماذج الكبيرة لاستخدامها عدة مرات في وقت واحد ، بعد كل شيء ، سيكون المدخلات بطيئة للغاية إذا كان طويلًا] تسريع نموذج لغوي كبير مع أخذ العينات المتخصصة
[استخدم موجهًا ناعمًا لتقليل الانخفاض في إمكانية ICL الناتجة عن ضبط دقيق ، وضبط المرحلة الأولى ، وضبط المرحلة الثانية] مع الحفاظ
【مهام التحليل الدلالية ، وطرق اختيار العينة من ICL ، و Codex و T5-LARGE】 مظاهرات متنوعة تعمل على تحسين التعميم التركيبي داخل السياق
【طريقة تحسين جديدة لتوليد النص】 نماذج توليد اللغات الخيالية تحت مسافة التباين الكلي
[تقدير عدم اليقين للجيل الشرطي ، باستخدام التجميع الدلالي جنبًا إلى جنب مع مخرجات أخذ العينات المتعددة لتقدير إنتروبيا عدم اليقين الدلالي: الثبات اللغوي لتقدير عدم اليقين في توليد اللغة الطبيعية
الضبط: تحسين قدرات التعلم الصفرية من نماذج اللغة الأصغر
【طريقة توليد نصية ملهمة للغاية ضمن قيود نصية مجانية】 توليد النصوص القابلة للتحكم مع قيود اللغة
[عند توليد التنبؤات ، استخدم التشابه مع اختيار العبارة بدلاً من رمز الرمز المميز]
[طريقة ICL للنص الطويل] سياق متوازي يحسن التعلم داخل السياق لنماذج اللغة الكبيرة
【عينة من نموذج instructgpt يولد ICL في حد ذاته】 نماذج لغة كبيرة ذاتية ل QA المجال المفتوح
【آليات النقل والانتباه تمكن ICL من إدخال المزيد من عينات التعليقات التوضيحية】 مطالبة منظمة: تحجيم التعلم في السياق إلى 1000 أمثلة
معايرة الزخم لتوليد النص
【طريقتان اختيار عينة ICL ، تجارب تعتمد على OPT و GPTJ】 يعمل على استقرار إدارة البيانات الدقيقة في التعلم داخل السياق
【تحليل مؤشرات التقييم للوحش (Pillutla et al.)】 حول فائدة التضمينات والمجموعات والسلاسل لتقييم النص
Promsagator: استرجاع كثيف قليل من 8 أمثلة
[ثلاثة cobblers ، Zhuge Liang] يعزز التوافق الذاتي سلسلة من التفكير في نماذج اللغة
[انقلب ، الإدخال والتسمية توليد تعليمات للشروط] تخمين تعليمات!
【الاشتقاق العكسي للاشتقاء العكسي ، فإن نماذج اللغة الكبيرة هي أسباب مع التحسين الذاتي
【طرق للبحث - سيناريوهات السلامة تحت عملية إنشاء أدلة】 fovate ، ورجعها ، والترشيد: نحو الذكاء الاصطناعي الآمن والجدير بالثقة
[تقدير الثقة للشظايا المستخرجة من المعلومات التي تم إنشاؤها النصية بناءً على البحث عن الشعاع] كيف يحسن بحث الحزمة من تقدير الثقة على مستوى السبعة في وضع العلامات التسلسلية التوليدية؟
SPT: ضبط موجه شبه البراريامي لتوليف المهام متعددة المهام التي دفعت إلى التعلم
【مناقشة حول ملخص الذهب الملخص المستخرج】 ملخص النص مع توقع Oracle
【طريقة اكتشاف ood استنادًا إلى مسافة المريخ】 اكتشاف التوزيع الخارجي والتوليد الانتقائي لنماذج اللغة الشرطية
[وحدة الانتباه تدمج موجه للتنبؤ بمستوى العينة] مجموعة النموذج بدلاً من الانصهار السريع: طريقة نقل المعرفة الخاصة بالعينة لضبط موجه قليل
【موجه للمهام المتعددة عن طريق التحلل والتقطير في موجه واحد】 تمكين توليف المهام متعددة المهام يتيح التعلم الناقل الفعال للمعلمة
[يمكن استخدام مؤشرات التقييم للمنطق الذي تم إنشاؤه خطوة بخطوة كموضوع لمشاركته في المرة القادمة]
[معايرة احتمال التسلسل يحسن توليد اللغة الشرطية]
【طريقة الهجوم النصية استنادًا إلى تحسين التدرج】 Textgrad: تقدم تقييم المتانة في NLP عن طريق التحسين الذي يحركه التدرج
[GMM النمذجة الحدود لتصنيف القرار ICL لمعايرة] المعايرة النموذجية للتعلم قليل من نماذج اللغة
【مشكلة إعادة كتابة ، وطريقة تجميع ICL المستندة إلى الرسم البياني】 اسألني أي شيء: استراتيجية بسيطة لطرح نماذج اللغة
[قاعدة بيانات لاختيار المرشحين الجيدين كـ ICLs من حمامات السباحة غير المقابلة] يجعل التعليقات التوضيحية الانتقائية نماذج اللغة أفضل متعلمين قليلة
promsboosting: تصنيف نص صناديق أسود مع عشرة تمريرات للأمام
هجمات الباب الخلفي الموجهة للانتباه ضد المحولات
【موقع القناع الموجه اختيار التسمية التلقائي】 نماذج اللغة التي تم تدريبها مسبقًا يمكن أن تكون متعلمين تمامًا صفريًا
[ضغط طول متجه إدخال FID وإعادة ترتيبه عند الإخراج لإخراج تصنيف المستند] الإخلاص الإثارة: توليد نص فعال وفعال من أجل الاسترجاع
【شرح لتوليد النماذج الكبيرة】 pinto: التفكير اللغوي المؤمن باستخدام المبررات التي تم إنشاؤها بواسطة
【ابحث عن مجموعة فرعية من تأثيرات ما قبل التدريب】 orca: تفسير نماذج اللغة المطلوبة عبر أدلة دعم الموقع في محيط بيانات ما قبل التدريب
[المشروع السريع ، الذي يستهدف التعليمات ، يولد المرحلة الأولى وتصفية فرز المرحلة] نماذج لغوية كبيرة هي مهندسين على مستوى الإنسان
المعرفة غير المعرفة لتخفيف مخاطر الخصوصية في نماذج اللغة
تحرير النماذج مع حساب المهمة
[لا تدخل التعليمات والعينات في كل مرة ، قم بتحويلها إلى وحدات فعالة للمعلمة ،] تلميح: ضبط تعليمات Hypernetwor
[طريقة توليد عرض ICL بدون اختيار عينة يدوي] Z-ICL: التعلم الصفر في السياق مع عمليات تعزيز زائفة
[تعليمات المهمة والنص توليد التضمين معًا] أحد التضمين ، أي مهمة: تضمينات نصية محفورة بالتعليمات
【نموذج كبير تدريس النموذج الصغير COT】 سكين: تقطير المعرفة مع المنطقات النصية الحرة
[مشكلة عدم الاتساق بين مصدر وتجزئة الكلمات المستهدفة لنموذج توليد استخراج المعلومات] مسائل تناسق الرمز المميز للنماذج التوليدية على مهام NLP الاستخراجية
Parsel: إطار عمل طبيعية موحدة للتفكير الخوارزمي
[اختيار عينة ICL ، اختيار المرحلة الأولى وفرز المرحلة الثانية] التعلم في السياق الذاتية
[القراءة المكثفة ، طريقة اختيار غير خاضعة للإشراف ، GPT-2] نحو ضبط موجه قابل للقراءة البشرية: Kubrick's The Shining هو فيلم جيد ، ومطالبة جيدة أيضًا
【اختبار مجموعة بيانات Prontoqa قدرة الاستدلال المولد وتجد أن قدرة التخطيط لا تزال محدودة】 نماذج اللغة يمكن (نوع) السبب: تحليل رسمي منهجي لسلسلة الفكر
【مجموعة بيانات التفكير】 wikiwhy: الإجابة وشرح أسئلة السبب والتأثير
【مجموعة بيانات التفكير】 Street: معيار تفكير منظم ومهنية متعددة المهام
【مجموعة بيانات التفكير ، مقارنة بين التدريب قبل التدريب والضبط ، بما في ذلك نماذج التثبيت الدقيقة cot】 التنبيه: تكييف نماذج اللغة مع مهام التفكير
[ملخص المنطق الأخير من قبل فريق Zhang Ningyu من جامعة Zhejiang] التفكير مع نموذج اللغة المطالبة: A Survey
[ملخص لتكنولوجيا توليد النص واتجاهه من قبل فريق Xiao Yanghua في Fudan] تسخير المعرفة والتفكير لتوليد اللغة الطبيعية التي تشبه الإنسان: مراجعة موجزة
[ملخص مقالات التفكير الحديثة ، جي هوانغ من UIUC] نحو التفكير في نماذج اللغة الكبيرة: مسح
【مراجعة المهام ومجموعات البيانات وأساليب التفكير الرياضي و DL】 دراسة استقصائية للتعلم العميق للتفكير الرياضي
دراسة استقصائية حول معالجة اللغة الطبيعية للبرمجة
مجموعة بيانات النمذجة المكافأة:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


