pytorch openai transformer lm
1.0.0
هذا هو تطبيق Pytorch لرمز TensorFlow الذي تم توفيره مع ورقة Openai "تحسين فهم اللغة من خلال التدريب قبل التدريب" بقلم أليك رادفورد ، كارثيك ناراسيمهان ، تيم سليمانس وإيليا سوتسكفر.
يشتمل هذا التنفيذ على برنامج نصي للتحميل في نموذج Pytorch الأوزان التي تم تدريبها مسبقًا من قبل المؤلفين مع تنفيذ TensorFlow.
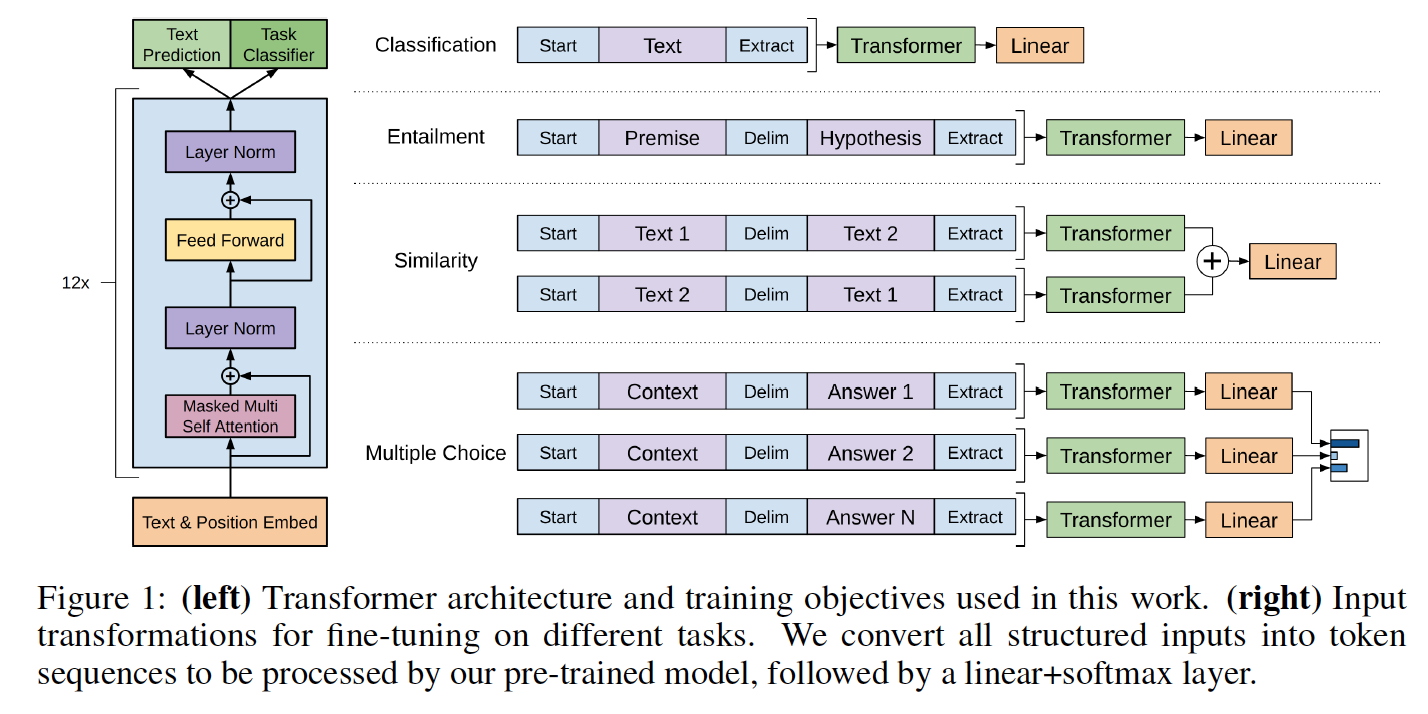
توجد فئات النماذج والبرنامج النصي تحميل في model_pytorch.py.
تتبع أسماء الوحدات النمطية في نموذج Pytorch أسماء المتغير في تطبيق TensorFlow. يحاول هذا التنفيذ متابعة الكود الأصلي بأكبر قدر ممكن لتقليل التناقضات.
وبالتالي ، يشتمل هذا التنفيذ أيضًا على خوارزمية تحسين ADAM المعدلة كما هو مستخدم في ورقة Openai مع:
لاستخدام النموذج IT-Self عن طريق استيراد model_pytorch.py ، تحتاج فقط إلى:
لتشغيل البرنامج النصي التدريبي المصنف في Train.py ستحتاج بالإضافة إلى ذلك:
يمكنك تنزيل أوزان الإصدار Openai الذي تم تدريبه مسبقًا من خلال استنساخ ريبو أليك رادفورد ووضع مجلد model الذي يحتوي على الأوزان التي تم تدريبها مسبقًا في الريبو الحالي.
يمكن استخدام النموذج كنموذج لغة محول مع أوزان Openai مسبقًا على النحو التالي:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) يولد هذا النموذج حالات المحول المخفية. يمكنك استخدام فئة LMHead في model_pytorch.py لإضافة وحدة فك ترميز مرتبطة بأوزان التشفير والحصول على نموذج لغة كاملة. يمكنك أيضًا استخدام فئة ClfHead في model_pytorch.py لإضافة مصنف أعلى المحول والحصول على مصنف كما هو موضح في منشور Openai. (انظر مثالًا لكليهما في وظيفة __main__ train.py)
لاستخدام التشفير الموضعي للمحول ، يجب عليك تشفير مجموعة البيانات الخاصة بك باستخدام وظيفة encode_dataset() من utils.py. يرجى الرجوع إلى بداية وظيفة __main__ في Train.py لمعرفة كيفية تحديد المفردات بشكل صحيح وترميز مجموعة البيانات الخاصة بك.
يمكن أيضًا دمج هذا النموذج في مصنف على النحو المفصل في ورقة Openai. يتم تضمين مثال على صقل المهمة على rocstories cloze مع رمز التدريب في Train.py
يمكن تنزيل مجموعة بيانات Rocstories من موقع الويب المرتبط.
كما هو الحال مع رمز TensorFlow ، ينفذ هذا الرمز نتيجة اختبار cloze rocstories المبلغ عنها في الورقة التي يمكن استنساخها عن طريق التشغيل:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]يستغرق التغلب على نموذج Pytorch لمدة 3 عصر على عمليات التمويل 10 دقائق لتشغيله على Nvidia K-80.
تبلغ دقة اختبار التشغيل الفردي هذا الإصدار Pytorch 85.84 ٪ ، بينما يبلغ المؤلفون دقة متوسطة مع رمز Tensorflow البالغ 85.8 ٪ ، وتبلغ الورقة عن أفضل دقة فردية قدرها 86.5 ٪.
تستخدم تطبيقات المؤلفين 8 GPU ، وبالتالي يمكن أن تستوعب مجموعة من 64 عينة بينما التنفيذ الحالي هو وحدة معالجة الرسومات الفردية ونتائج تقتصر على 20 حالة على K80 لأسباب الذاكرة. في اختبارنا ، زادت حجم الدفعة من 8 إلى 20 عينة من دقة الاختبار بمقدار 2.5 نقطة. يمكن الحصول على دقة أفضل باستخدام إعداد متعدد GPU (لم يتجرب بعد).
تبلغ SOTA السابقة على مجموعة بيانات Rocstories 77.6 ٪ ("نموذج التماسك المخفي" لـ Chaturvedi et al. تم نشره في "فهم القصة" للتنبؤ بما يحدث بعد ذلك "EMNLP 2017 ، وهي ورقة لطيفة للغاية أيضًا!)


