archgw
release 0.1.5 ?
Arch عبارة عن وكيل ذكي من الطبقة 7 الموزعة مصممة لحماية وكلاء الذكاء الاصطناعى ومراقبته وتخصيصه باستخدام واجهات برمجة التطبيقات الخاصة بك.
تم تصميم ARCH مع LLMs المصممة لهذا الغرض ، مع المهام الحرجة ولكن غير المتمايزة المتعلقة بالتعامل مع المطالبات ومعالجتها ، بما في ذلك اكتشاف ورفض محاولات الحماية من الحماية ، والاتصال بذكاء "الواجهة" لتلبية طلب المستخدم المركزي في متداولة في متداولة.
تم بناء Arch على (والمساهمين الأساسيين في وكيل المبعوث مع الاعتقاد:
المطالبات هي طلبات مستخدمة دقيقة ودقيقة ، والتي تتطلب نفس القدرات مثل طلبات HTTP التقليدية بما في ذلك المعالجة الآمنة ، والتوجيه الذكي ، والملاحظة القوية ، والتكامل مع أنظمة الخلفية (API) للتخصيص - جميع منطق العمل الخارجي.*
الميزات الأساسية :
اقفز إلى مستنداتنا لمعرفة كيف يمكنك استخدام ARCH لتحسين سرعة وأمان وتخصيص تطبيقات Genai الخاصة بك.
مهم
اليوم ، يتم استضافة وظيفة الاتصال بـ LLM (الوظيفة القوس) المصممة لسيناريوهات الوكيل والخرقة مجانًا في المنطقة الأمريكية المركزية. لتقديم زمنات زمنية وإنتاجية متسقة ، ولإدارة نفقاتنا ، سنمكّن الوصول إلى الإصدار المستضاف عبر مفاتيح المطورين قريبًا ، ونمنحك خيار تشغيل LLM محليًا. لمزيد من التفاصيل ، راجع هذه المشكلة رقم 258
للتواصل معنا ، يرجى الانضمام إلى خادم Discord الخاص بنا. سنراقب ذلك بنشاط ونقدم الدعم هناك.
اتبع هذا الدليل لمعرفة كيفية إعداد القوس بسرعة ودمجه في تطبيقات الذكاء الاصطناعي التوليدي.
قبل أن تبدأ ، تأكد من أن لديك ما يلي:
Docker & Python مثبتة على نظامكAPI Keys لمقدمي خدمات LLM (إذا كنت تستخدم LLMs الخارجية)يسمح لك Arch's CLI بإدارة بوابة القوس والتفاعل بكفاءة. لتثبيت CLI ، ما عليك سوى تشغيل الأمر التالي: نصيحة: نوصي بأن يقوم المطورون بإنشاء بيئة افتراضية جديدة في بيثون لعزل التبعيات قبل تثبيت القوس. هذا يضمن أن ArchGW وتبعياتها لا تتداخل مع الحزم الأخرى على نظامك.
تأكد من تثبيت المرافق التالية قبل المضي قدمًا ،
$ python -m venv venv
$ source venv/bin/activate # On Windows, use: venvScriptsactivate
$ pip install archgwيعمل Arch استنادًا إلى ملف التكوين حيث يمكنك تحديد موفري LLM ، والأهداف السريعة ، والدرجات ، وما إلى ذلك.
version : v0.1
listener :
address : 127.0.0.1
port : 8080 # If you configure port 443, you'll need to update the listener with tls_certificates
message_format : huggingface
# Centralized way to manage LLMs, manage keys, retry logic, failover and limits in a central way
llm_providers :
- name : OpenAI
provider : openai
access_key : $OPENAI_API_KEY
model : gpt-3.5-turbo
default : true
# default system prompt used by all prompt targets
system_prompt : |
You are a network assistant that helps operators with a better understanding of network traffic flow and perform actions on networking operations. No advice on manufacturers or purchasing decisions.
prompt_targets :
- name : device_summary
description : Retrieve network statistics for specific devices within a time range
endpoint :
name : app_server
path : /agent/device_summary
parameters :
- name : device_ids
type : list
description : A list of device identifiers (IDs) to retrieve statistics for.
required : true # device_ids are required to get device statistics
- name : days
type : int
description : The number of days for which to gather device statistics.
default : " 7 "
- name : reboot_devices
description : Reboot a list of devices
endpoint :
name : app_server
path : /agent/device_reboot
parameters :
- name : device_ids
type : list
description : A list of device identifiers (IDs).
required : true
- name : days
type : int
description : A list of device identifiers (IDs)
default : " 7 "
# Arch creates a round-robin load balancing between different endpoints, managed via the cluster subsystem.
endpoints :
app_server :
# value could be ip address or a hostname with port
# this could also be a list of endpoints for load balancing
# for example endpoint: [ ip1:port, ip2:port ]
endpoint : host.docker.internal:18083
# max time to wait for a connection to be established
connect_timeout : 0.005sإجراء مكالمات خارجية عبر القوس
from openai import OpenAI
# Use the OpenAI client as usual
client = OpenAI (
# No need to set a specific openai.api_key since it's configured in Arch's gateway
api_key = '--' ,
# Set the OpenAI API base URL to the Arch gateway endpoint
base_url = "http://127.0.0.1:12000/v1"
)
response = client . chat . completions . create (
# we select model from arch_config file
model = "--" ,
messages = [{ "role" : "user" , "content" : "What is the capital of France?" }],
)
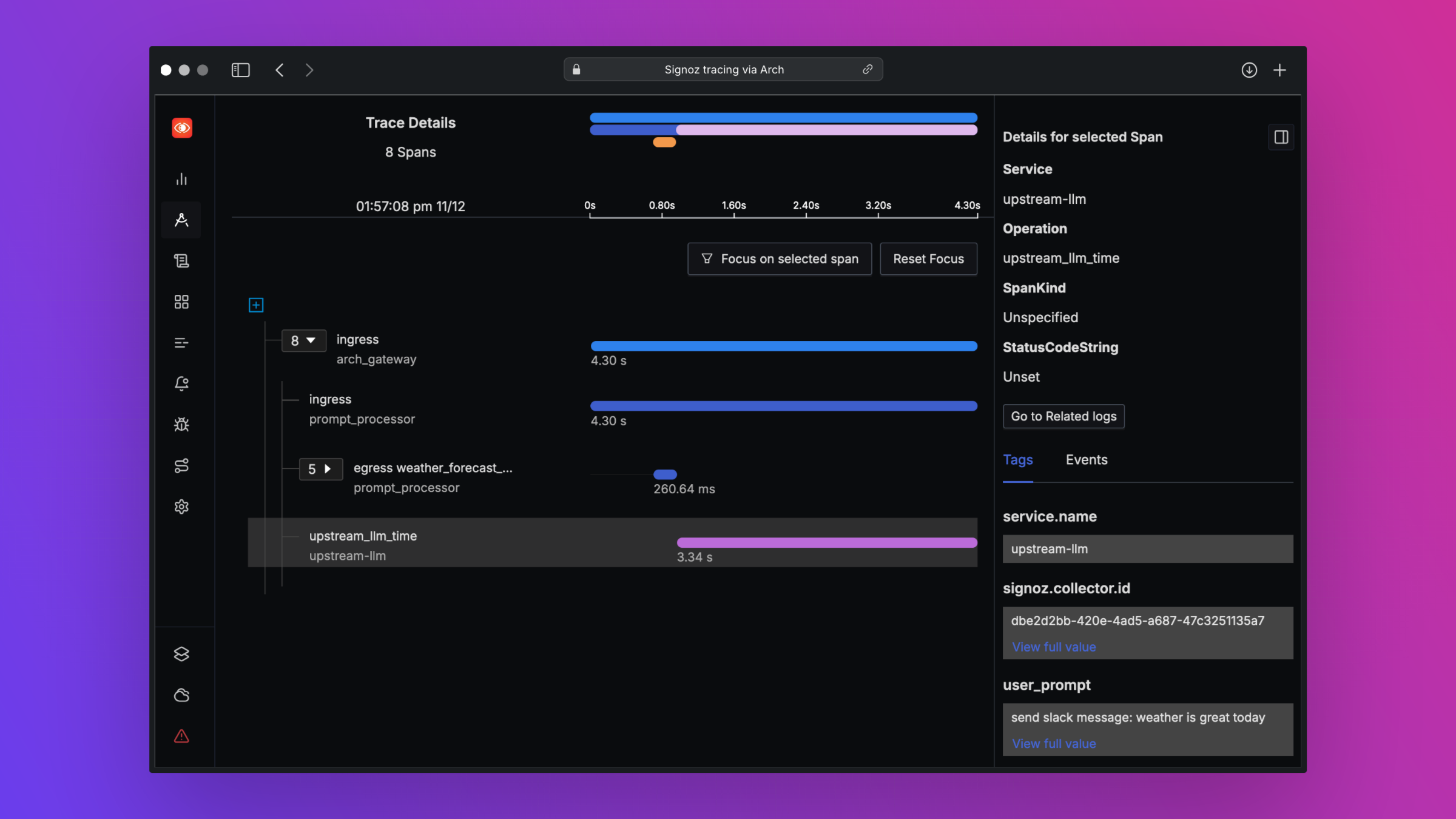
print ( "OpenAI Response:" , response . choices [ 0 ]. message . content )تم تصميم Arch لدعم أفضل إمكانية ملاحظته من خلال دعم المعايير المفتوحة. يرجى قراءة مستنداتنا حول قابلية الملاحظة لمزيد من التفاصيل حول التتبع والمقاييس والسجلات
نود ردود الفعل على خريطة الطريق الخاصة بنا ونرحب بالمساهمات في Arch ! سواء كنت تقوم بإصلاح الأخطاء أو إضافة ميزات جديدة أو تحسين الوثائق أو إنشاء برامج تعليمية ، فإن مساعدتك موضع تقدير كبير. يرجى زيارة دليل المساهمة لدينا لمزيد من التفاصيل


