GPTCache
v0.1.44
قم بقطع تكاليف API LLM بمقدار 10x؟ ، زيادة السرعة بمقدار 100x ⚡
؟ تم دمج GPTCache بالكامل مع؟ ️؟ langchain! فيما يلي تعليمات استخدام مفصلة.
؟ تم إصدار صورة Docker Server GPTCACHE ، مما يعني أن أي لغة ستتمكن من استخدام GPTCACHE!
؟ يمر هذا المشروع بتطوير سريع ، وعلى هذا النحو ، قد تخضع واجهة برمجة التطبيقات للتغيير في أي وقت. للحصول على أحدث المعلومات ، يرجى الرجوع إلى أحدث الوثائق وإصدار ملاحظة.
ملاحظة: نظرًا لأن عدد النماذج الكبيرة ينمو بشكل متفجر وتتطور شكل واجهة برمجة التطبيقات الخاصة بهم باستمرار ، لم نعد نضيف دعمًا لواجهة برمجة التطبيقات أو الطرز الجديدة. نحن نشجع استخدام استخدام واجهة برمجة تطبيقات GET and SET في GPTCACHE ، إليك الرمز التجريبي: https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
تتميز ChatGPT ومختلف نماذج اللغة الكبيرة (LLMS) براعة لا تصدق ، مما يتيح تطوير مجموعة واسعة من التطبيقات. ومع ذلك ، مع نمو شعبية التطبيق الخاص بك ويواجه مستويات مرور أعلى ، يمكن أن تصبح النفقات المتعلقة بمكالمات API LLM كبيرة. بالإضافة إلى ذلك ، قد تظهر خدمات LLM أوقات استجابة بطيئة ، خاصة عند التعامل مع عدد كبير من الطلبات.
لمعالجة هذا التحدي ، أنشأنا GPTCache ، وهو مشروع مخصص لبناء ذاكرة التخزين المؤقت الدلالية لتخزين استجابات LLM.
ملحوظة :
python --versionpython -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installستساعدك هذه الأمثلة على فهم كيفية استخدام المطابقة الدقيقة والمماثلة مع التخزين المؤقت. يمكنك أيضًا تشغيل المثال على كولاب. والمزيد من الأمثلة التي يمكنك الرجوع إليها
قبل تشغيل المثال ، تأكد من تعيين متغير بيئة OpenAI_API_KEY عن طريق تنفيذ echo $OPENAI_API_KEY .
إذا لم يتم تعيينه بالفعل ، فيمكن تعيينه باستخدام export OPENAI_API_KEY=YOUR_API_KEY على أنظمة UNIX/Linux/MacOS أو set OPENAI_API_KEY=YOUR_API_KEY على أنظمة Windows.
من المهم أن نلاحظ أن هذه الطريقة فعالة فقط مؤقتًا ، لذلك إذا كنت تريد تأثيرًا دائم ، فستحتاج إلى تعديل ملف التكوين المتغير للبيئة. على سبيل المثال ، على جهاز Mac ، يمكنك تعديل الملف الموجود على
/etc/profile.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )إذا طرحت chatgpt نفس السؤالين بالضبط ، فسيتم الحصول على إجابة السؤال الثاني من ذاكرة التخزين المؤقت دون طلب chatgpt مرة أخرى.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )بعد الحصول على إجابة من ChatGPT ردًا على العديد من الأسئلة المماثلة ، يمكن استرداد الإجابات على الأسئلة اللاحقة من ذاكرة التخزين المؤقت دون الحاجة إلى طلب ChatGPT مرة أخرى.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )يمكنك دائمًا تمرير معلمة من درجة الحرارة أثناء طلب خدمة أو طراز API.
نطاق
temperatureهو [0 ، 2] ، القيمة الافتراضية هي 0.0.درجة الحرارة الأعلى تعني إمكانية أعلى لتخطي البحث عن ذاكرة التخزين المؤقت وطلب نموذج كبير مباشرة. عندما تكون درجة الحرارة 2 ، فإنها ستخطي ذاكرة التخزين المؤقت وإرسال الطلب إلى طراز كبير مباشرة. عندما تكون درجة الحرارة 0 ، فإنها ستبحث عن ذاكرة التخزين المؤقت قبل طلب خدمة نموذج كبيرة.
الافتراضي
post_process_messages_funcهوtemperature_softmax. في هذه الحالة ، راجع مرجع API لمعرفة كيفية تأثيرtemperatureعلى الإنتاج.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])لاستخدام GPTCache على وجه الحصر ، لا يلزم سوى الأسطر التالية من التعليمات البرمجية ، وليس هناك حاجة لتعديل أي رمز موجود.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()المزيد من المستندات :
تقدم GPTCache الفوائد الأساسية التالية:
غالبًا ما تعرض الخدمات عبر الإنترنت موقع بيانات ، حيث يصل المستخدمون بشكل متكرر إلى المحتوى الشائع أو المتجه. تستفيد أنظمة ذاكرة التخزين المؤقت من هذا السلوك عن طريق تخزين البيانات التي يتم الوصول إليها بشكل شائع ، والتي بدورها تقلل من وقت استرجاع البيانات ، ويحسن أوقات الاستجابة ، ويخفف من عبء الخوادم الخلفية. عادةً ما تستخدم أنظمة ذاكرة التخزين المؤقت التقليدية مطابقة دقيقة بين استعلام جديد واستعلام مخزنة مؤقتًا لتحديد ما إذا كان المحتوى المطلوب متاحًا في ذاكرة التخزين المؤقت قبل جلب البيانات.
ومع ذلك ، فإن استخدام نهج المطابقة الدقيق لذاكرة التخزين المؤقت LLM أقل فعالية بسبب تعقيد وتباين استعلامات LLM ، مما يؤدي إلى انخفاض معدل ذاكرة التخزين المؤقت. لمعالجة هذه المسألة ، تتبنى GPTCache استراتيجيات بديلة مثل التخزين المؤقت الدلالي. يحدد التخزين المؤقت الدلالي ويخزن استعلامات مماثلة أو ذات صلة ، وبالتالي زيادة احتمالية ذاكرة التخزين المؤقت وتعزيز كفاءة التخزين المؤقت بشكل عام.
توظف GPTCache دمج خوارزميات لتحويل الاستعلامات إلى تضمينات وتستخدم متجر ناقلات للبحث عن التشابه على هذه التضمينات. تتيح هذه العملية GPTCache تحديد واسترداد استعلامات مماثلة أو ذات صلة من تخزين ذاكرة التخزين المؤقت ، كما هو موضح في قسم الوحدات النمطية.
يتميز GPTCache بتصميم وحدات ، يسهل على المستخدمين تخصيص ذاكرة التخزين المؤقت الدلالية الخاصة بهم. يقدم النظام تطبيقات مختلفة لكل وحدة ، ويمكن للمستخدمين حتى تطوير تطبيقاتهم الخاصة لتناسب احتياجاتهم الخاصة.
في ذاكرة التخزين المؤقت الدلالية ، قد تواجه إيجابيات كاذبة أثناء ضربات ذاكرة التخزين المؤقت والسلبيات الخاطئة أثناء مخيفين ذاكرة التخزين المؤقت. تقدم GPTCache ثلاث مقاييس لقياس أدائها ، وهو أمر مفيد للمطورين لتحسين أنظمة التخزين المؤقت الخاصة بهم:
يتم تضمين معيار عينة للمستخدمين للبدء في تقييم أداء ذاكرة التخزين المؤقت الدلالية.
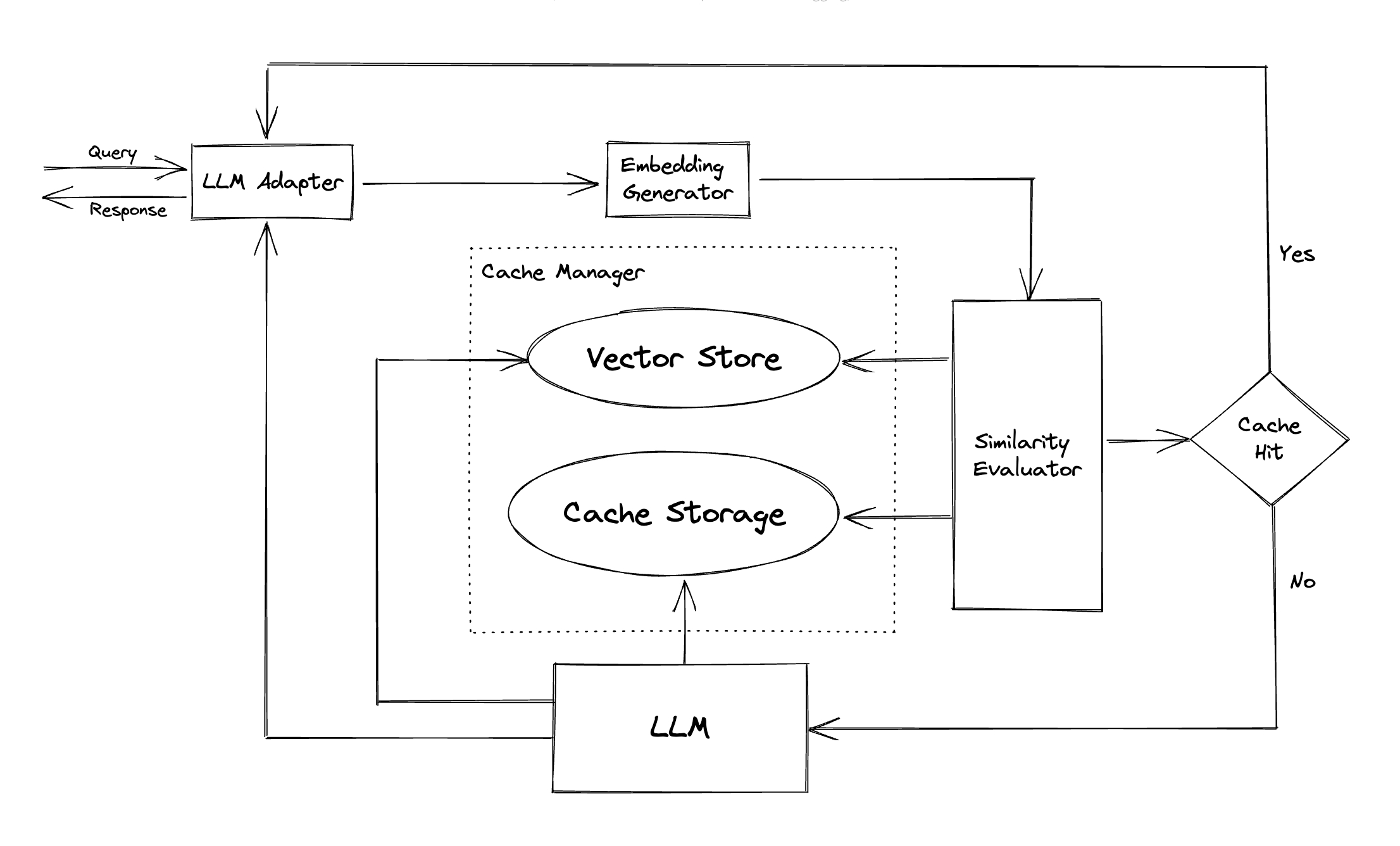
محول LLM : تم تصميم محول LLM لدمج نماذج LLM المختلفة عن طريق توحيد بروتوكولات واجهات برمجة التطبيقات وطلب. تقدم GPTCache واجهة موحدة لهذا الغرض ، مع الدعم الحالي لتكامل ChatGPT.
محول متعدد الوسائط (تجريبي) : تم تصميم المحول متعدد الوسائط لدمج نماذج مختلفة متعددة الوسائط مختلفة عن طريق توحيد بروتوكولات واجهات برمجة التطبيقات وطلب. يوفر GPTCACHE واجهة موحدة لهذا الغرض ، مع الدعم الحالي لدمج توليد الصور ، نسخ الصوت.
مولد التضمين : يتم إنشاء هذه الوحدة لاستخراج التضمين من طلبات البحث عن التشابه. تقدم GPTCache واجهة عامة تدعم واجهات برمجة التطبيقات المتعددة التضمين ، وتقدم مجموعة من الحلول للاختيار من بينها.
تخزين ذاكرة التخزين المؤقت : تخزين تخزين ذاكرة التخزين المؤقت هو المكان الذي يتم فيه تخزين استجابة LLMS ، مثل ChatGPT. يتم استرداد الاستجابات المخزنة مؤقتًا للمساعدة في تقييم التشابه ويتم إرجاعها إلى الطالب إذا كانت هناك تطابق دلالي جيد. في الوقت الحاضر ، تدعم GPTCACHE SQLITE وتوفر واجهة يمكن الوصول إليها عالميًا لتمديد هذه الوحدة.
متجر Vector : تساعد وحدة Store Vector في العثور على أكثر الطلبات K مماثلة من التضمين المستخرج من طلب الإدخال. يمكن أن تساعد النتائج في تقييم التشابه. يوفر GPTCACHE واجهة سهلة الاستخدام تدعم متاجر المتجهات المختلفة ، بما في ذلك Milvus و Zilliz Cloud و FAISS. المزيد من الخيارات ستكون متاحة في المستقبل.
مدير التخزين المؤقت : مدير التخزين المؤقت مسؤول عن التحكم في تشغيل كل من تخزين ذاكرة التخزين المؤقت ومتجر المتجهات .
cachetools في Python أو بطريقة موزعة باستخدام Redis كمتجر القيمة الرئيسية.حاليًا ، تتخذ GPTCache قرارات بشأن عمليات الإخلاء تعتمد فقط على عدد الخطوط. يمكن أن يؤدي هذا النهج إلى تقييم غير دقيق للموارد وقد يسبب أخطاء خارج الذاكرة (OOM). نحن نحقق بنشاط وتطوير استراتيجية أكثر تطوراً.
إذا كنت ترغب في توسيع نطاق نشر GPTCACHE أفقياً باستخدام التخزين المؤقت في الذاكرة ، فلن يكون ذلك ممكنًا. نظرًا لأن المعلومات المخزنة مؤقتًا ستقتصر على جراب واحد.
مع التخزين المؤقت الموزع ، معلومات ذاكرة التخزين المؤقت متسقة في جميع النسخ المتماثلة ، يمكننا استخدام متاجر ذاكرة التخزين المؤقت الموزعة مثل redis.
مُقيِّم التشابه : تجمع هذه الوحدة البيانات من كل من تخزين ذاكرة التخزين المؤقت ومتجر المتجهات ، وتستخدم استراتيجيات مختلفة لتحديد التشابه بين طلب الإدخال والطلبات من متجر المتجهات . بناءً على هذا التشابه ، يحدد ما إذا كان الطلب يطابق ذاكرة التخزين المؤقت. يوفر GPTCache واجهة موحدة لدمج الاستراتيجيات المختلفة ، إلى جانب مجموعة من التطبيقات لاستخدامها. يتم دعم تعريفات التشابه التالية حاليًا أو سيتم دعمها في المستقبل:
ملاحظة : قد لا تكون جميع مجموعات الوحدات النمطية المختلفة متوافقة مع بعضها البعض. على سبيل المثال ، إذا قمنا بتعطيل مستخرج التضمين ، فقد لا يعمل متجر المتجهات على النحو المقصود. نحن نعمل حاليًا على تنفيذ فحص عقلاني لـ GPTCache .
قريباً! ابقوا متابعين!
نحن منفتحون للغاية على المساهمات ، سواء كان ذلك من خلال ميزات جديدة أو بنية تحتية محسّنة أو وثائق محسنة.
للحصول على تعليمات شاملة حول كيفية المساهمة ، يرجى الرجوع إلى دليل المساهمة لدينا.


