Deep RL Keras
1.0.0
التنفيذ المعياري لخوارزميات التعلم العميق الشعبية في كيراس:
يتطلب هذا التنفيذ Keras 2.1.6 ، وكذلك Openai Gym.
$ pip install gym keras==2.1.6خوارزمية الممثل الناقص هي طريقة خالية من النماذج خارج الجودة حيث يعمل الناقد كقوات تقريبية للقيمة ، والممثل كقائد للسياسة. عند التدريب ، يتنبأ الناقد بـ TD-error ويوجه تعلم نفسه والممثل. في الممارسة العملية ، نقوم بتقريب خطير TD باستخدام دالة Advantage. لمزيد من الاستقرار ، نستخدم العمود الفقري الحسابي المشترك عبر كلتا الشبكتين ، بالإضافة إلى صياغة N-Step للمكافآت المخفضة. ندمج أيضًا مصطلح تنظيم الانتروبيا (التعلم "الناعم") لتشجيع الاستكشاف. على الرغم من أن A2C بسيط وفعال ، إلا أن تشغيله على ألعاب Atari يصبح سريعًا بسبب وقت الحساب الطويل.
بطريقة مماثلة مثل خوارزمية A2C ، يتضمن تنفيذ A3C تحديثات الوزن غير المتزامن ، مما يتيح حسابًا أسرع بكثير. نحن نستخدم عوامل متعددة لأداء صعود التدرج بشكل غير متزامن ، على مؤشرات ترابط متعددة. نختبر A3C على بيئة Atari Breakout.
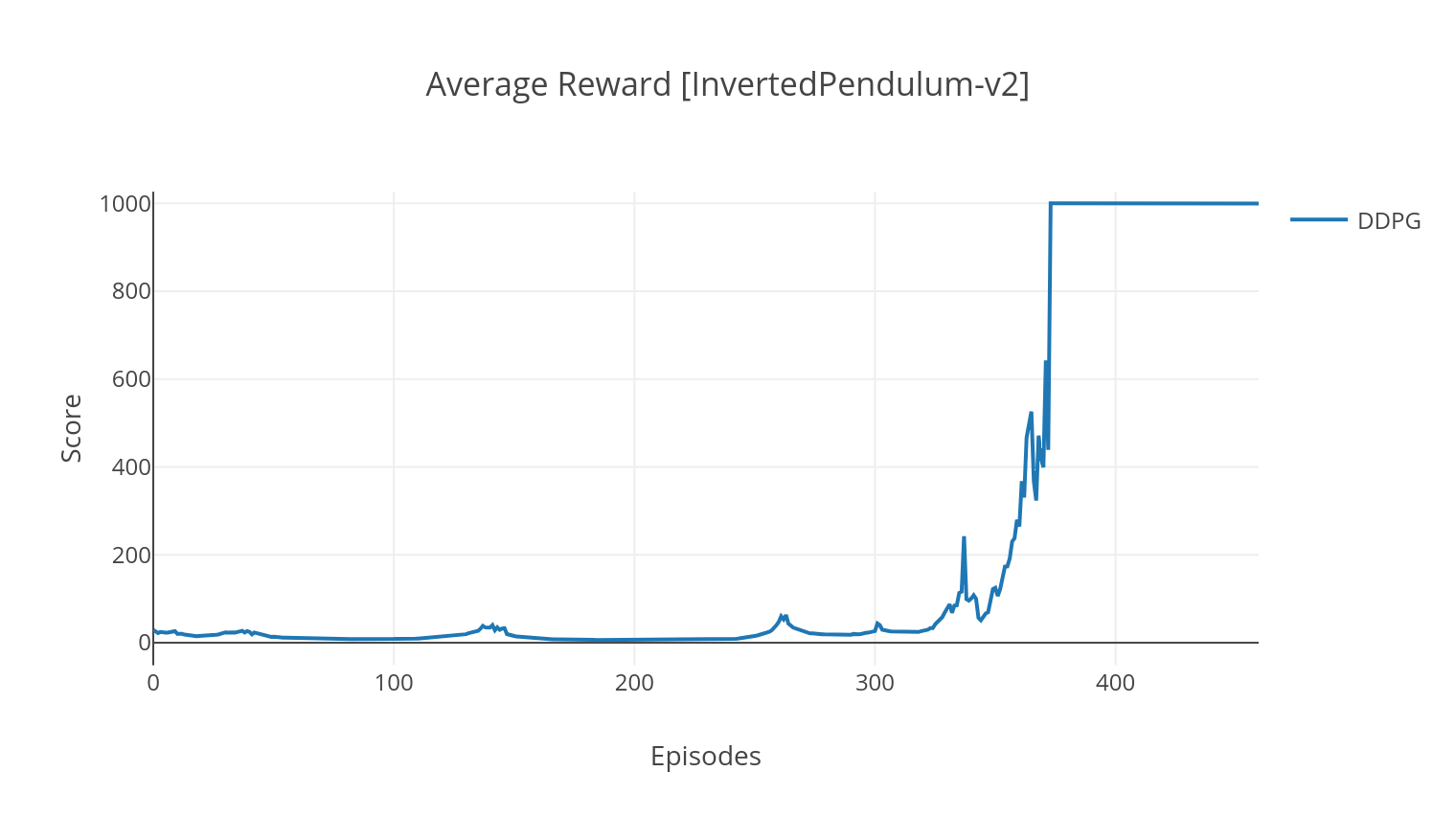
خوارزمية DDPG هي خوارزمية خالية من النماذج خارج السياسة لمساحات العمل المستمرة. على غرار A2C ، فهي خوارزمية ممثلة النحوية يتم فيها تدريب الممثل على سياسة مستهدفة حتمية ، ويتوقع الناقد القيم Q. من أجل تقليل التباين وزيادة الاستقرار ، نستخدم تجربة إعادة التشغيل وشبكات مستهدفة منفصلة. علاوة على ذلك ، كما ألمح من قبل Openai ، فإننا نشجع الاستكشاف من خلال ضوضاء مساحة المعلمة (على عكس ضوضاء مساحة العمل التقليدية). نختبر DDPG على بيئة Lunar Lander.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2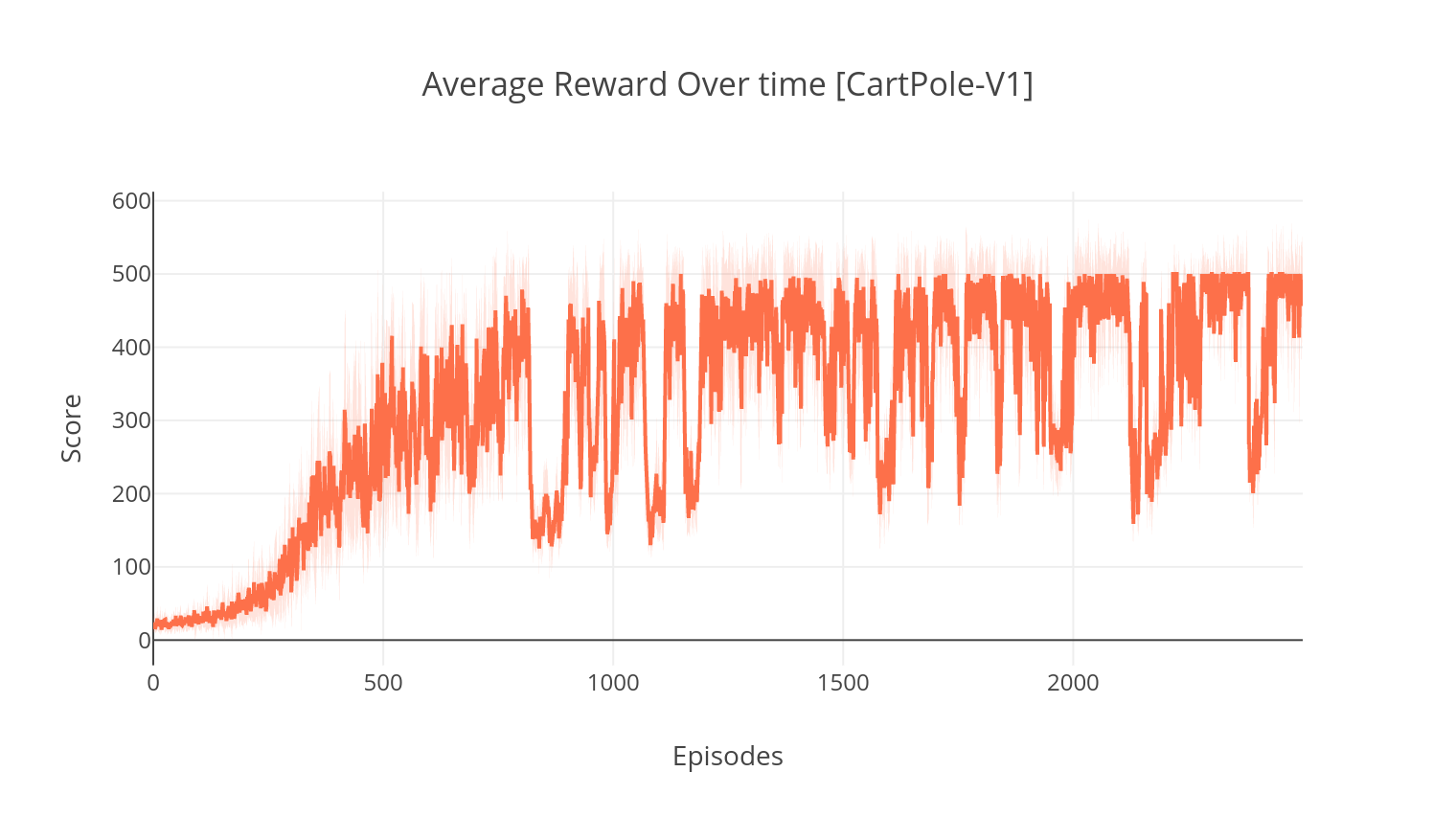
خوارزمية DQN هي خوارزمية للتعلم Q ، والتي تستخدم شبكة عصبية عميقة كقوة دالة Q-Value. نحن نقدر قيم Q Target من خلال الاستفادة من معادلة Bellman ، ونجمع الخبرة من خلال سياسة Epsilon-Greedy. لمزيد من الاستقرار ، نقوم بتجربة التجارب السابقة بشكل عشوائي (تجربة إعادة). البديل من خوارزمية DQN هو Double-DQN (أو DDQN). للحصول على تقدير أكثر دقة للقيم Q ، نستخدم شبكة ثانية لتخفيف المبالغة في تقديرات القيم Q بواسطة الشبكة الأصلية. يتم تحديث هذه الشبكة المستهدفة بمعدل أبطأ TAU ، في كل خطوة تدريب.
يمكننا زيادة تحسين خوارزمية DDQN الخاصة بنا من خلال إضافة إعادة تشغيل أولوية لإعادة تشغيل (PER) ، والتي تهدف إلى أداء أخذ عينات الأهمية على التجربة التي تم جمعها. يتم تصنيف هذه التجربة بواسطة TD-Beror ، وتخزينها في بنية Sumtree ، والتي تتيح استرجاعًا فعالًا للانتقالات (S ، A ، R ، S ') بأعلى خطأ.
في البديل المبارز من DQN ، ندمج طبقة وسيطة في الشبكة Q لتقدير كل من قيمة الحالة ووظيفة الميزة المعتمدة على الحالة. بعد إعادة الصياغة (انظر المرجع) ، اتضح أنه يمكننا التعبير عن القيمة Q-value المقدرة كقيمة الحالة ، والتي نضيف إليها تقدير ميزة وطرح متوسطها. يساعد هذا العوامل في القيم المستقلة عن الدولة والمعتمدة على الدولة في فك الارتباط عبر الإجراءات ويحقق نتائج أفضل.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling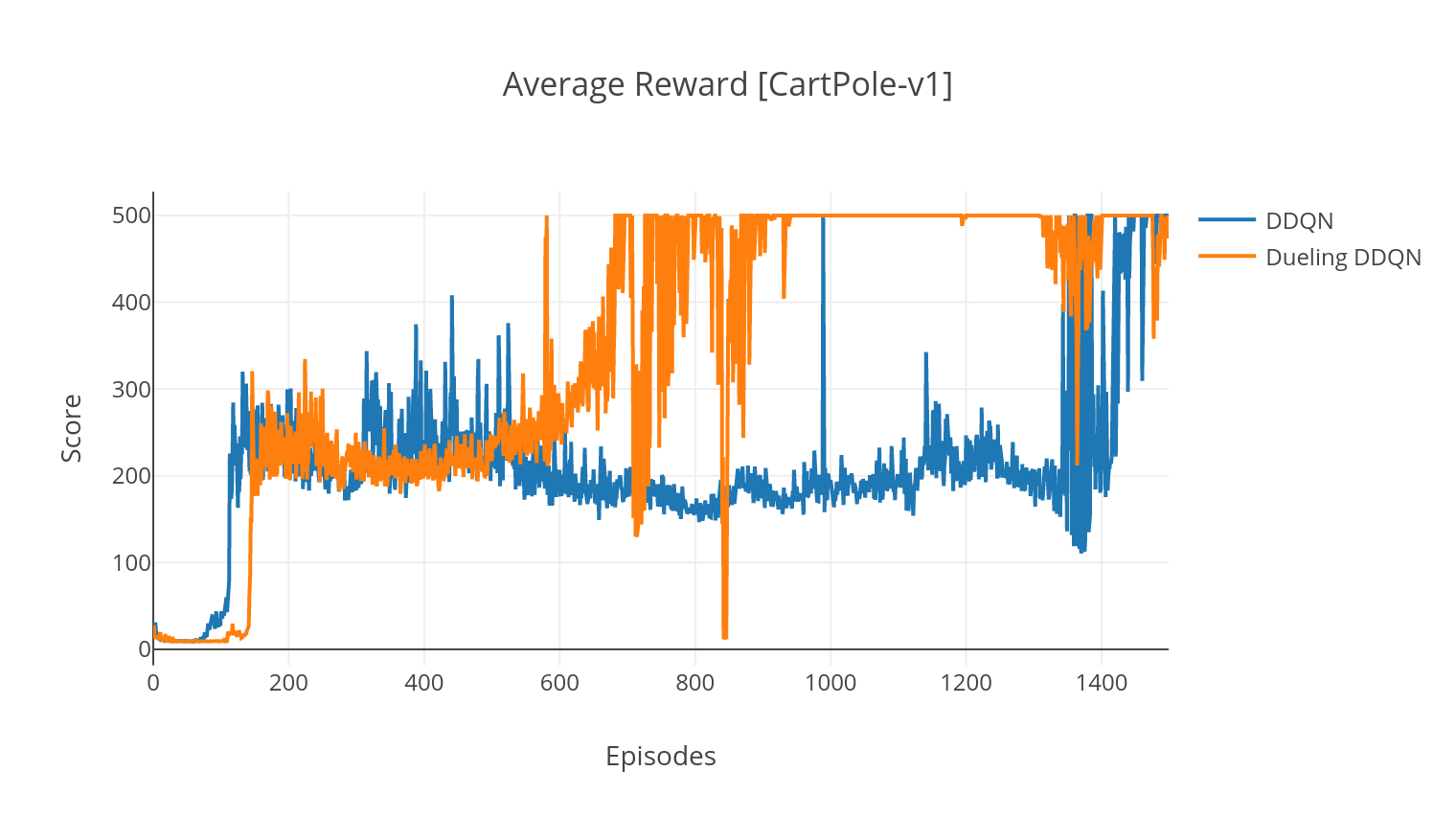
| دعوى | وصف | قيم |
|---|---|---|
| --يكتب | نوع خوارزمية RL للتشغيل | اختر من {A2C ، A3C ، DDQN ، DDPG} |
| -env | حدد البيئة | breakoutnoframeskip-v4 (افتراضي) |
| -NB_EPISODES | عدد الحلقات التي يجب تشغيلها | 5000 (افتراضي) |
| -batch_size | حجم الدُفعة (DDQN ، DDPG) | 32 (افتراضي) |
| -تتراوح من consecutive_frames | عدد الإطارات المتتالية المكدسة | 4 (افتراضي) |
| -is_atari | ما إذا كانت البيئة لعبة أتاري مع إدخال بكسل | - |
| -مع _per | سواء كنت تستخدم إعادة تشغيل أولوية إعادة التشغيل (مع DDQN) | - |
| -السلان | سواء كنت تستخدم شبكات المبارزة (مع DDQN) | - |
| --N_Threads | عدد المواضيع (A3C) | 16 (افتراضي) |
| -gather_stats | ما إذا كان يجب حساب احصائيات الدرجات في المتوسط أكثر من 10 ألعاب (بطيئة ، انظر أدناه) | - |
| --يجعل | سواء كانت ستجعل البيئة كما هي تدريب | - |
| -GPU | مؤشر GPU | 0 |
يتم حفظ جميع النماذج تحت <algorithm_folder>/models/ عند الانتهاء من التدريب. يمكنك تصورها تعمل في نفس البيئة التي تم تدريبها من خلال تشغيل البرنامج النصي load_and_run.py . بالنسبة لنماذج DQN ، يجب عليك تحديد المسار إلى النموذج المطلوب في وسيطة --model_path . بالنسبة للنماذج الفاعلة الناقصة ، تحتاج إلى تحديد كل من ملفات الوزن في --actor_path و- --critic_path .
باستخدام Tensorboard ، يمكنك مراقبة درجة الوكيل أثناء التدريب. عند التدريب ، سيتم إنشاء مجلد سجل يحمل الاسم الذي يتطابق مع البيئة المختارة. على سبيل المثال ، لمتابعة تقدم A2C على Cartpole-V1 ، ببساطة تشغيل:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ عند التدريب مع الوسيطة --gather_stats ، يتم إنشاء ملف السجل الذي يحتوي على نتائج أكثر من 10 ألعاب في كل حلقة: logs.csv . باستخدام مخطط ، يمكنك تصور متوسط المكافأة لكل حلقة. للقيام بذلك ، ستحتاج أولاً إلى تثبيت مؤسسة والحصول على ترخيص مجاني.
pip3 install plotlyلإعداد بيانات الاعتماد الخاصة بك ، قم بتشغيل:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )أخيرًا ، لرسم النتائج ، تشغيل:
python3 utils/plot_results.py < path_to_your_log_file >

