super json mode
1.0.0
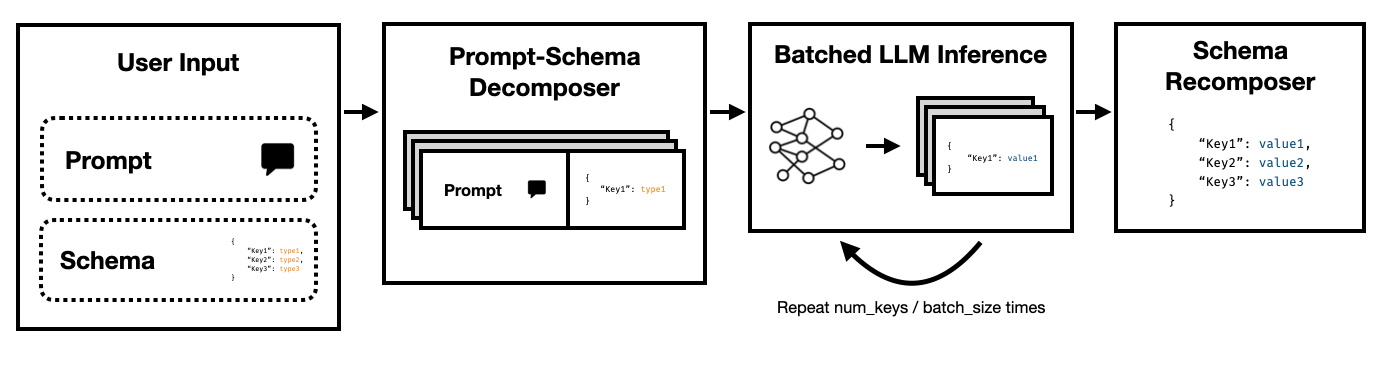
Super JSON Mode هو إطار Python يمكّن من إنشاء المخرجات المهيكلة من LLM عن طريق تقسيم مخطط مستهدف إلى مكونات ذرية ثم أداء أجيال بالتوازي.
وهو يدعم كل من LLMs على أحدث طراز Art LLMS عبر API من Openai و LLMs Open Source مثل عن طريق Lugging Face Transformers و VLLM . سيتم دعم المزيد من LLMS قريبًا!
بالمقارنة مع خط أنابيب جيل JSON الساذج الذي يعتمد على المحولات المطلوبة و HF ، نجد أن وضع JSON Super JSON يمكن أن يولد مخرجات ما يصل إلى 10x أسرع . كما أنه أكثر حتمية وأقل عرضة للواجب في مشاكل التحليل عند مقارنتها بالجيل الساذج.
التثبيت بسيط: pip install super-json-mode
تنسيقات الإخراج المنظمة ، مثل JSON أو YAML ، لها بنية متوازية أو هرمية متأصلة.
النظر في المقطع غير المهيكلة التالي (الناتج عن GPT-4):
مرحبًا بكم في 123 Azure Lane ، وهو مقر إقامة مذهل في سان فرانسيسكو يضم تصميمًا معاصرًا رائعًا ، الآن في السوق مقابل 2500،000 دولار. ينتشر هذا العقار على مساحة فاخرة تبلغ 3000 قدم مربع ، ويجمع بين التطور والراحة لخلق تجربة معيشة فريدة من نوعها حقًا.
منزل شاعري للعائلات أو المحترفين ، تم تجهيز إقامتنا الحصرية بخمس غرف نوم واسعة ، كل دفء وموزعة. يتم التخطيط بعناية غرف النوم للسماح بمساحة تخزين طبيعية واسعة ومساحة تخزين سخية. مع ثلاثة حمامات كاملة مصممة بأناقة ، يضمن الإقامة الراحة والخصوصية لسكانها.
يقودك المدخل الكبير إلى منطقة معيشة واسعة ، مما يوفر أجواء ممتازة للتجمعات أو أمسية هادئة بجوار النار. يشتمل مطبخ الطاهي على الأجهزة الحديثة والخزائن المخصصة وأسطح الجرانيت الجميلة مما يجعله حلمًا لأي شخص يحب الطهي.
إذا أردنا استخراج address ، square footage ، number of bedrooms ، number of bathrooms ، price باستخدام LLM ، فيمكننا أن نطلب من النموذج ملء مخطط وفقًا للوصف.
يمكن أن يبدو المخطط المحتمل (مثل أحد كائن Pydantic) مثل هذا:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
ويمكن أن يبدو الناتج الصحيح مثل هذا:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
يتمثل النهج الواضح في تعشق المخطط في المطالبة واطلب من النموذج ملءه. وهذا هو كيفية استخراج معظم الفرق حاليًا من الناتج المنظم من النص غير المنظم باستخدام LLMs.
ومع ذلك ، هذا غير فعال لثلاثة أسباب.
لاحظ كيف تكون كل من هذه المفاتيح مستقلة عن بعضها البعض. يستفيد وضع Super JSON من التوازي الفوري من خلال معاملة كل زوج من القيمة الرئيسية في المخطط كتحقيق منفصل. على سبيل المثال ، يمكننا استخراج num_baths دون إنشاء address بالفعل!
إن طلب نموذج لإنشاء JSON من نقطة الصفر يستهلك الرموز الرموز (والوقت) بشكل غير ضروري على بناء الجملة يمكن التنبؤ به ، مثل أسماء الأقواس وأسماء المفاتيح ، والتي من المتوقع بالفعل في الإخراج. هذا أمر قوي قبل الجيل الذي يجب أن نكون قادرين على استخدامه لتحسين الكمون.
LLMs متوازية بشكل محرج وتشغيل الاستعلامات على دفعات أسرع بكثير مما هو في ترتيب متسلسل. وبالتالي ، يمكننا تقسيم المخطط على استفسارات متعددة. سوف تملأ LLM المخطط لكل مفتاح مستقل بالتوازي وينبعث منها عدد أقل بكثير من الرموز في تمريرة واحدة ، مما يتيح أوقات استنتاج أسرع بكثير.
قم بتشغيل الأمر التالي:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
لقد حاولنا جعل وضع Super Json Super سهل الاستخدام. انظر مجلد examples لمزيد من الأمثلة واستخدام vLLM .
باستخدام Openai و gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }باستخدام MISTRAL 7B مع محولات Luggingface:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } هناك الكثير من الميزات التي يمكن أن تجعل وضع Super JSON أفضل. هنا بعض الأفكار.
تحليل الإخراج النوعي : قمنا بتشغيل معايير الأداء ، ولكن يجب أن نتوصل إلى نهج أكثر صرامة للحكم على المخرجات النوعية لوضع Super JSON.
أخذ العينات المهيكلة : من الناحية المثالية ، يجب علينا إخفاء سجلات LLM لفرض قيود النوع ، على غرار JSonformer. هناك عدد قليل من الحزم التي تقوم بذلك بالفعل ، وإما أن تدمج خط أنابيب جيل JSON المتوازي أو يجب أن نبنيه في وضع Super JSON.
دعم الرسم البياني للاعتماد : يحتوي وضع Super JSON على حالة فشل واضحة للغاية: عندما يكون للمفتاح اعتماد على مفتاح آخر. النظر في blob json مع مفتاحين ، thought response . يعتبر هذا النوع من الإخراج المطلوب شائعًا في سلسلة الأفكار مع نماذج لغة كبيرة ، ومن الواضح جدًا أن response تعتمد على thought . يجب أن نكون قادرين على تمريره في رسم بياني من التبعيات ومطالبات الدُفعات بطريقة اكتملت مخرجات الوالدين وتمريرها على عناصر مخطط الطفل.
دعم النماذج المحلية : يعمل وضع Super JSON بشكل أفضل في المواقف المحلية حيث يكون حجم الدُفعة عمومًا 1. يمكنك استغلال الدفعة لتقليل الكمون ، على غرار فك تشفير المضاربة. Llama.cpp هو الإطار الرئيسي للموديلات المحلية + الاستدلال وحدة المعالجة المركزية. أحب تنفيذ هذا باستخدام Ollama إن أمكن.
دعم TRT-LLM : VLLM رائع وسهل الاستخدام ، ولكن من الناحية المثالية ندمج مع إطار عمل أكثر بكثير مثل TRT-LLM.
نحن نقدر ذلك إذا كنت ستشير إلى هذا الريبو إذا وجدت أن المكتبة مفيدة لعملك:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
تم بناء هذا المشروع لـ CS 229: أنظمة التعلم الآلي. شكر كبير لفريق التدريس و TAS على توجيههما خلال هذا المشروع.


