Verteilte Hbase-Datenbank v2.4.18
2.4.18
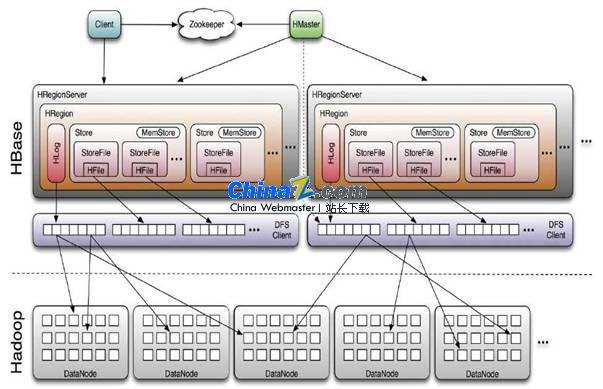
Die verteilte Hbase-Datenbank ist die verteilte, skalierbare NoSQL-Hadoop-Datenbank von Apache, die sich gut skalieren lässt. Daten in Hbase sind eine spaltenorientierte Datenbank, in der strukturierte Daten in Schlüssel-Wert-Paaren gespeichert werden. Hbase ist in Java geschrieben. Hbase ist inspiriert von Google Paper – „Big Table: A Distributed Storage System for Structured Data“. Hbase kommt vor allem dort zum Einsatz, wo sehr schnelle Lese- und Schreibzugriffe erforderlich sind. In diesem Beitrag zeige ich, wie man Apache Hbase unter Windows installiert. Hbase kann unabhängig von Hadoop verwendet werden.
Linear skalierbar.
Konsequentes Lesen und Schreiben.
Automatisches und konfigurierbares Sharding von Tabellen
Automatische Failover-Unterstützung für Regionsserver.
Integrieren Sie Hadoop als Quelle und Ziel.
Einfach zu verwendende Java-basierte API für den Clientzugriff.
Zugriff mit geringer Latenz auf eine einzelne Zeile unter Milliarden von Datensätzen.
Finden Sie schnell größere Tische.
Thrift-Gateway und REST-fähige Webdienste, die XML-, Protobuf- und binäre Datenkodierungsoptionen unterstützen
Erweiterbare Jruby-basierte (JIRB) Shell
Unterstützt den Export von Metriken in eine Datei oder Ganglia über das Hadoop-Metrik-Subsystem oder über JMX